XiaoMi-AI文件搜索系统
World File Search System高维

HDANOVA:方差的高维分析
Hima-pake。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 2个二元帐户。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 3连续输出。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 4个hima。 div> 。 div> 。 div>Hima-pake。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>2个二元帐户。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 3连续输出。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 4个hima。 div> 。 div> 。 div>2个二元帐户。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>3连续输出。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>4个hima。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>5 hima_classic。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>9 hima_dblasso。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。。。。。11 hima_eficient。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。13 hima_microbiome。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。15 hima_quantile。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。16 hima_survival。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。18个微生物瘤。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。20量化。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。21生存。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。21

生理学的自动化、高维评估...
摘要 行为和生理是许多研究中必不可少的读数,但并未从改变分子和细胞表型的高维数据革命中受益。为了解决这个问题,我们开发了一种方法,将市售的自动表型硬件与系统生物学分析流程相结合,以生成小鼠行为/生理的高维读数,以及直观且与健康相关的汇总统计数据(弹性和生物年龄)。我们使用这个平台纵向评估了数百只年龄从 3 个月到 3.4 岁的杂交小鼠的衰老情况。与只能通过基于挑战的任务在动物能力极限下测量衰老的假设相反,我们观察到从生命早期开始的普遍生理和行为衰老。通过网络连接分析,我们发现生物体水平的弹性随着年龄的增长而加速下降,这与个体表型的轨迹不同。我们开发了一种联合衰老和生存预测衰老率 (CASPAR) 方法,用于联合预测实际年龄和生存时间,并表明生成的模型能够同时预测这两个变量,这是单独的年龄和死亡率预测模型无法捕捉到的行为。这项研究提供了小鼠生理衰老的独特高分辨率视图,并表明系统级生理分析提供了单个表型无法捕捉到的见解。本文描述的方法允许以更高的通量、分辨率和表型范围研究衰老以及影响行为和生理的其他过程。

高维的全量子层析成像 -
在很大程度上是由于整体两国频率梳(BFCS)[1]的出现,由于其固有的高尺寸和纠缠与fiftic网络的固有的高尺寸和纠缠相对于频率域中的量子信息处理越来越关注。但是,此类状态的量子状态层析成像(QST)需要进行主动频率混合操作的复杂而精确的工程[2-4],这很难扩展。为了加强这些局限性,我们提出了一种新颖的SO,它采用了脉冲塑造器和电动相调制器(EOM)来执行隆起操作,而不是以规定的方式进行混合。结合了最先进的贝叶斯统计方法[5],我们成功地验证了纠缠和重建由芯片SI 3 N 4微孔共振器(MRR)产生的BFC的全密度ma-Trix,最高为8×8- dimensional dimensional dimensials timensials Twip Qud-QudqudiT hilbert Space,最高频率为water water forsy Bins water for derumension for derumense for derumension for derumension。总体而言,我们的方法为频率可实现的操作提供了一种实验性的频率键断层扫描方法。编码单个光子的量子信息水平,称为光子Qudits [6],量子通信和网络相关的关键范围[7],例如较高的信息能力[8],增加噪声耐受性[9],以及对Bell不平等现象的强烈侵害[10]。已经在许多自由度中探索了光子量的生成和操纵,包括路径[11,12],轨道角度[13,14],频率箱[2,3,15]和时间箱[16,17]。综合光子学在缩放量子状态的复杂性[18,19]和量子操作[20]中起关键作用,并且自由度的频率程度特别有吸引力,因为芯片BFC可以以紧凑的方式产生大量的频谱纠缠的垃圾箱。

qudits和高维量子计算
Qudit是一种多级计算单元的替代品,可替代2级量子。与Qubit相比,Qudit提供了更大的状态空间来存储和过程信息,因此可以降低电路复杂性,简化实验设置以及算法效率的实现。本评论提供了基于Qudit的量子计算的概述,涵盖了从电路构建,算法设计到实验方法的各种主题。我们首先讨论了Qudit Gate的通用性和各种Qudit门,包括Pi/8 Gate,交换门和多级别控制的门。然后,我们介绍了几种代表性量子算法的QUDIT版本,包括Deutsch-Jozsa算法,量子傅立叶变换和相位估计算法。最后,我们讨论了用于QUDIT计算的各种物理实现,例如光子平台,铁陷阱和核磁共振。

高维计算——“诅咒”的好处......
Pentti Kanerva。2009 年。超维计算:使用高维随机向量进行分布式表示的计算简介。认知计算 1、2 (2009),139–159。https://doi.org/10.1007/s12559-009-9009-8
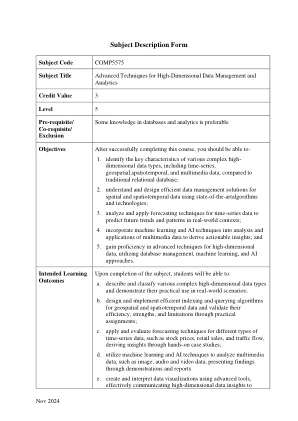
comp5575高维的高级技术...
•作业和项目通常提供动手学习的方法,使学生可以将理论知识应用于实际情况。通过处理与所有五个学习成果保持一致的各种任务,学生可以演示他们描述,设计,设计,实施,应用,评估和可视化高维数据的能力。这种连续的评估方法鼓励对主题的一致参与和更深入的了解。

HIMA:高维中介分析
pqrbayes包装。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>2覆盖范围。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>3个数据。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。。。。。。。。4估计。PQRBAYES。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。5 pqrbayes。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。6 pqrbayes.select。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。9 Predive_pqrbayes。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。11 print.pqrbayes。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。12 print.pqrbayes.pred。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。13 print.pqrbayes.select。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。13

qudits和高维量子计算
qudit是传统2级值的多级计算单元替代品。与Qubit相比,Qudit提供了更大的状态空间来存储和过程信息,因此可以降低电路复杂性,简化实验设置以及算法效率的增强。本评论提供了基于Qudit的量子计算的概述,涵盖了从电路构建,算法设计到实验方法的各种主题。我们首先讨论Qudit门通用性和各种Qudit门,包括Pi/8 Gate,交换门和多级别控制的门。然后,我们介绍了几种代表性量子算法的QUDIT版本,包括Deutsch-Jozsa算法,量子傅立叶变换和相位估计算法。最后,我们讨论了用于QUDIT计算的各种物理实现,例如光子平台,铁陷阱和核磁共振。

高维量子计算模拟器
摘要。使用经典计算机模拟量子计算已成功帮助研究过于复杂而无法进行分析的量子算法和电路。量子计算模拟器的当前实现仅限于两级量子系统。高维量子计算系统的最新进展证明了使用多级叠加和纠缠的可行性。这些进步允许在保持量子纠缠的同时灵活增加系统的维度数,实现更高的信息编码,并使量子算法不易受到退相干和计算错误的影响。在本文中,我们介绍了一种新型的高维云量子计算模拟器 QuantumSkynet。该平台允许模拟基于 qudit 的量子算法。我们还提出了高维量子门的统一泛化,可用于 QuantumSkynet 中的模拟。最后,我们报告了使用 QuantumSkynet 对基于 qudit 的 Deutsch-Jozsa 版本和量子相位估计算法进行的模拟及其结果。

高压下二元富氢超导体的实验研究进展
lah 10(T C = 250 K),Drozdov和Al。(2019)LAH 10(T C = 260 K),Somayazalu和Al。(2019)YH 9(T C = 243 K),Kong和Al。(2019)YH 6(T C = 224 K),Troyan和Al。(2019)CAH 6(T C = 215 K),但等。(2021)CAH 6(T C = 210 K),Li和Al。(2022)SH 3(T C = 203 K),Drozdov和Al。(2015)THH 10(T C = 161 K),Semenoch和Al。(2019)CEH 10(T C = 115 K),Chen和Al。(2021)CEH 9(T C = 100K),Chen和Al。(2021)YH 4(T C = 88 K),Shao和Al。(2021)BAH 12(T C = 20 K),Chhen和Al。(2021)SNH X(T C = 70K),Hong和Al。(2022)