XiaoMi-AI文件搜索系统
World File Search System默认

NetBackuptm flex量表默认情况下安全
Veritas Technologies是安全多云数据管理的领导者。超过80,000个客户(包括财富100强的91%)依靠Veritas,以帮助确保其数据的保护,可恢复性和遵守情况。veritas以大规模的可靠性而闻名,这为客户所需的弹性提供了与网络攻击威胁的中断,例如勒索软件。没有其他供应商能够通过单个统一的方法来匹配Veritas执行的能力,并支持800多个数据源,100多个操作系统和1,400多个存储目标。由云量表技术提供支持,Veritas今天正在为自动数据管理的策略提供,从而降低了运营开销,同时又提供了更大的价值。在www.veritas.com上了解更多信息。在@veritastechllc上关注我们。

默认模式网络在实时使用EEG
摘要 - 心理健康障碍会影响全球无数人,并对精神卫生服务提出了一个重大挑战,这些服务正在全球范围内的需求挣扎。最近的研究表明,大脑的默认模式网络(DMN)的活动可以证明是在监测患者从抑郁症中康复的洞察力,并已被用作治疗靶点本身。存在使用功能性磁共振成像来复制针对DMN连接性的最新治疗方案,使用脑电图(EEG)的更经济可扩展的模态。这项工作的目的是验证使用公开可用数据集应用于脑电图数据的实时DMN检测方法的准确性。使用隐藏的马尔可夫模型来识别12个状态静止状态网络,这项工作的总体DMN检测准确性为95%。此外,该模型能够在基线和计算出的DMN分数占用率之间实现0.617的相关性。这些结果证明了实时分析通过脑电图数据有效识别DMN的能力,从而为进一步的应用程序提供了监测和治疗心理健康障碍的途径。
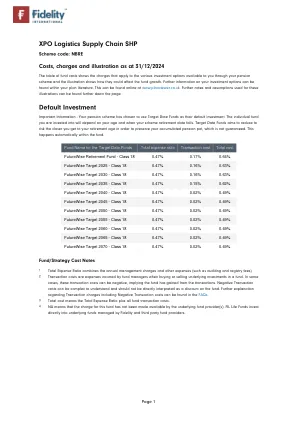
XPO物流供应链SHP默认投资
从2023年10月1日起,法规更改以改善我们用来计算估计生长的假设的计算方法。所有的养老金计划,包括忠诚度,现在都使用增长率,这些增长率基于过去五年中基金的价值上下的速度,这被称为波动性。在过去的5年中无法使用基金数据的情况下,我们使用了代理基金。以下估计的利率表明,根据投资基金的不同,要使用的增长率假设是2%,4%,6%或7%的增长率假设。假设通货膨胀率为每年2.5%,插图中的数字以真实的方式显示。这意味着我们弄清楚基金的估计增长率将允许通货膨胀的影响。


使用机器学习的贷款默认预测模型...
摘要。银行贷款违约是可能影响银行业务的重要问题之一。为了避免这样的问题,银行需要分析大量数据,因此机器学习(ML)用于帮助做出准确的贷款批准决策。但是,在任何数据集中,贷款违约的存在都很小,这可能导致阶级失衡和预测偏见。另一个问题是存在可能导致预测模型的无关变量。因此,本研究的目的是通过将机器学习分类器与功能工程和数据集进行重新采样来克服这两个问题,以产生准确的预测。因此,本研究评估了四个机器学习分类器的性能,即K-Nearest邻居(KNN),逻辑回归(LR),决策树(DT)和随机森林(RF),在贷款俱乐部的公共默认贷款数据集上。应用数据预处理后,提出的方法使用该功能工程来根据特征相关性消除无关的功能。然后,将自适应合成抽样(ADASYN)应用于管理类别问题。实验结果表明了模型过度拟合问题的严重性,因为四个模型在功能工程和ADASYN方面的表现更好,并且准确性的显着增强。在这四个模型中,增强的RF模型在准确性,精度,灵敏度,特异性,F1分数和AUC方面,分别为0.95、0.97、0.96、0.8、0.94和0.88。关键字:银行贷款批准,贷款默认,机器学习算法,预测模型,类不平衡,功能工程

人工智能中设计和默认的隐私沙盒 ...
针对侵犯人权的风险实施适当的问责措施。2019 年,工商监管局 (SIC) 发布了以下文件:(i) 电子商务个人数据处理指南 1 ;(ii) 营销和广告个人数据处理指南 2 ;(iii) 个人数据国际转移问责原则实施指南 3 。在所有这些文件中,建议在设计和默认时纳入隐私、道德和安全。此外,建议进行隐私影响评估 (PIA)。

默认模式网络 20 年:回顾与总结
默认模式网络 (DMN) 的发现彻底改变了我们对人类大脑运作方式的理解。在这里,我回顾了导致发现 DMN 的发展,提出了个人反思,并思考了我们对 DMN 功能的认识在过去二十年中是如何演变的。我总结了研究 DMN 在自我参照、社会认知、情景和自传体记忆、语言和语义记忆以及走神方面的作用的文献。我确定了统一的主题并提出了关于 DMN 在人类认知中的作用的新观点。我认为 DMN 整合并传播记忆、语言和语义表征,以创建一个反映我们个人经历的连贯的“内部叙事”。这种叙事对于构建自我意识至关重要,塑造了我们如何看待自己和与他人互动,可能在儿童时期的自我导向言语中具有个体发生起源,并构成了人类意识的重要组成部分。


朝着基于机器学习的公司贷款默认预测模型
摘要 - 作为银行体系的核心业务是借入货币,然后将其取回,贷款违约是商业银行最关键的问题之一。随着数据分析和人工智能,从历史数据中提取有价值的信息,以降低其损失,银行将能够对客户进行分类并预测信贷还款的可能性,而不是依靠传统方法。由于大多数实际的研究都集中在个人的贷款上,因此本文的新颖性是处理公司贷款。其主要目标是提出一个模型,使用选定的机器学习算法解决问题,以将公司分为两个类,以便能够预测贷款违约者。本文深入研究公司贷款默认预测模型(CLD PM),该模型旨在预测公司中的贷款违约。该模型以CRIRP-DM流程为基础,从理解公司要求并实施分类技术开始。数据采集和制备阶段对于测试所选算法至关重要,该算法涉及逻辑回归,决策树,支持向量机,随机森林,XGBoost和Adaboost。使用各种指标,即准确性,精度,召回,F1分数和AUC评估该模型的功效。随后,使用摩洛哥房地产公司的实际贷款数据集对该模型进行审查。调查结果表明,随机森林和XGBoost算法的表现优于其他算法,每个度量标准都超过90%。这是通过将SMOTE作为一种过采样方法来完成的,鉴于数据集的不平衡。此外,当专注于财务报表时,选择了五个最重要的财务比率和该公司的年龄,随机森林擅长预测结果良好的违约者:准确性为90%,精度为75%,召回50%,F1得分为60%,AUC为77%。

双重合格特殊需求计划(D-SNP)默认注册
i。确定成员的医疗补助参与提供者。II。 识别医疗补助福利,该成员可能有资格根据D-SNP的福利摘要,根据D-SNP未涵盖的医疗补助州计划,该计划未涵盖服务。 iii。 提供信息,包括根据会员的要求或案件协调员或其他健康计划人员确定的联系信息,以获得医疗补助福利。 iv。 协调根据会员的要求或计划的护理协调员确定的医疗补助服务的访问,包括识别和转介所需的服务,护理计划的援助以及获得所需服务的约会的帮助。 v。协助根据成员的要求或计划的护理协调员确定的有关承保范围或医疗保险之间可能出现的付款或付款问题的问题。II。识别医疗补助福利,该成员可能有资格根据D-SNP的福利摘要,根据D-SNP未涵盖的医疗补助州计划,该计划未涵盖服务。iii。提供信息,包括根据会员的要求或案件协调员或其他健康计划人员确定的联系信息,以获得医疗补助福利。iv。协调根据会员的要求或计划的护理协调员确定的医疗补助服务的访问,包括识别和转介所需的服务,护理计划的援助以及获得所需服务的约会的帮助。v。协助根据成员的要求或计划的护理协调员确定的有关承保范围或医疗保险之间可能出现的付款或付款问题的问题。