XiaoMi-AI文件搜索系统
World File Search System下进

波音 737-800 飞机进近时坠毁
简介 2009 年 2 月 25 日,土耳其航空公司运营的一架波音 737-800(航班 TK1951)从土耳其伊斯坦布尔阿塔图尔克机场飞往阿姆斯特丹史基浦机场。由于这是一次“监督下的航线飞行”,驾驶舱内有三名机组人员,分别是机长(兼任教练)、副驾驶(必须在航线上积累经验,因此在监督下飞行)和观察飞行的安全飞行员。机上还有四名机组人员和 128 名乘客。在接近史基浦机场 18 号右跑道(18R)时,飞机在距离跑道入口约 1.5 公里处坠毁在一片田地中。此次事故造成包括三名飞行员在内的四名机组人员和五名乘客丧生,另有三名机组人员和 117 名乘客受伤。

COVID-19疫苗接种文档和进气表
剂量:0.3毫升辉瑞/Biontech Covid-19疫苗0.5 ml Moderna Covid-19疫苗批次:______________________________________。Date: ________ Record: Vaccination record card provided to Patient Vaccinator's Comments (use additional space on back of form if necessary): ______________________________________________ ___________________________________________________________________________________________________________ ___________________________________________________________________________________________________________ ___________________________________________________________________________________________________________ ___________________________________________________ ______________________________________________ Vaccinator Signature Vaccinator Printed Name and Title Date Date Entered into ICARE:_______________________ Date Uploaded into AllVax:_______________ ICARE PID:____________________________

使用氢燃料电池进行长时储能
[1] P. Denholm,《可再生能源》130(2019 年)388-399 [2] MR Shaner、SJ Davis、NS Lewis、K. Calderia。“地球物理对美国太阳能和风能可靠性的限制。”《能源与环境科学》11(2018 年)914-925 [3] B. Pierpont。“注意存储缺口:我们需要多少灵活性来实现高可再生能源电网?”Green Tech Media,2017 年 6 月。 [4] B. Pierpont、D. Nelson、A. Goggins、D. Posner。“灵活性:通往低碳、低成本电网的道路。”《气候政策倡议》,2017 年 4 月。 [5] 氢能委员会,2020 年。“通往氢能竞争力的道路:成本视角。”

室内路径的多目标进化性人工电位
摘要:路径计划对于机器人技术至关重要,使机器人可以从其当前位置到目标位置找到无碰撞的路线。人造潜力领域(APF)方法利用有吸引力的排斥性领域来指导机器人朝目标,同时避免障碍物。但是,由于局部最小值,常规APF的排斥潜在方程可能会产生次优的结果。为了解决这个问题,引入了一种称为多目标进化性人工电位场(MOE-APF)的新颖方法。MOE-APF修改了排斥电势方程,并采用膜计算和遗传算法(GA)来优化一组新的APF参数。健身函数考虑了多个目标:路径长度,平滑度,成功率和安全性。与最新方法的比较称为膜进化性人工电位场(MEMEAPF)表明,MOE-APF显着提高了各种环境之间的路径质量,优化时间和成功率。MOE-APF的多功能性使其能够应对涉及非全面机器人,多个机器人,工业操纵器和动态障碍的路径规划挑战。

对成人进行人乳头瘤病毒疫苗
通过拥有书面急诊医疗方案以及设备和药物的书面急诊医疗方案,为管理与疫苗管理有关的医疗紧急情况做好准备。有关Immunize.org的“在社区环境中成年患者的疫苗反应的医疗管理”,请访问www.immunize.org/catg/catg.d/p3082.pdf。有关Immunize.org的“社区环境中儿童和青少年疫苗反应的医疗管理”,请访问www.immunize.org/catg/catg.d/p3082a.pdf。为了防止晕厥,在坐下或躺下时为患者接种疫苗,并考虑在接收疫苗后观察15分钟。
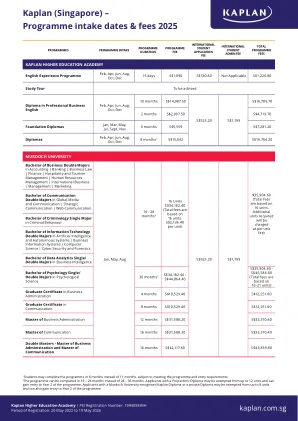
Kaplan(新加坡) - 程序进气日期和费用2025
1名学生可以在8个月而不是11个月内完成该计划,但要满足计划和入境要求。2该程序可以在16 - 24个月内完成,而不是28 - 36个月。具有理工文凭的申请人最多可免除12个单位,并且可以进入该计划的第二年。拥有默多克大学认可的卡普兰文凭或私人文凭的申请人可以免除8个单位,还可以进入该计划的第二年。

学术模块指南2024(2024年4月进气)
学生将通过照片录音室和实验室中的一系列讲座,演示和动手练习来发展数字成像和绘画方面的知识和技能。他们将在整个学期中以项目和练习的形式进行实际评估。然后,学生将渲染并提交一个最终的最终项目和/或工作主体(投资组合),以证明他们使用适当的软件和硬件作为最终评估的形式来解决他们解决沟通问题的能力。设计原理该模块为学生提供了视觉设计的基本原理,以有效地组织和呈现使用接口的信息。该模块将为学生提供有关有效设计的感知和认知原则的深入研究。该模块将利用支持并帮助建立以人为本设计的技术。交互式设计专业的学生将被介绍到特定于Web的编码和技术技能,以设计和开发非线性互动作品。将考虑概念和设计方面。该模块将通过讲师,示范和实用的结构来交付。设计研究

基于 GPS 的飞机进近和着陆系统的开发...
尖端技术构建美好未来:宇宙应用的先进技术 隼鸟2号的离子发动机及其潜在应用 隼鸟2号——自主导航、制导和控制系统 支持龙宫小行星精确着陆 隼鸟2号航天器利用太空激光雷达和遥感技术自主着陆 隼鸟2号:系统设计和运行结果 用于高速、大容量数据通信的光学卫星间通信技术 为三朝深空站开发30kW级X波段固态功率放大器 开发世界最高性能的薄膜太阳能电池阵列桨片

用于精密进近的差分 GPS - CORE
摘要:目前,美国国防部使用几种精确着陆系统 (PLS),包括仪表着陆系统 (lLS)、自动航母着陆系统 (ACLS)、 地面站设备,并且不是在不同服务中统一实施的。 这导致了各服务之间的可靠性问题。此外,这些着陆系统存在许多缺陷,包括可用性、人力需求和频繁拥堵。 因此。 需要一种新的 Pn:d 离子着陆系统来满足国防部的要求。地面站设备,并且不是在不同服务中统一实施的。这导致了各服务之间的可靠性问题。此外,这些着陆系统存在许多缺陷,包括可用性、人力需求和频繁拥堵。因此。需要一种新的 Pn:d 离子着陆系统来满足国防部的要求。
