XiaoMi-AI文件搜索系统
World File Search System交互方式

引文 (APA) Peschl, M.、Zgonnikov, A.、Oliehoek, FA 和 Cavalcante Siebert, L. (2022)。道德:通过多目标强化主动学习使人工智能与人类规范保持一致。在 C. Pelachaud 和 ME Taylor (Eds.) 中,第 21 届自主代理和多智能体系统国际会议 (AAMAS '22) 论文集 (第 1038-1046 页)。国际自主代理和多智能体系统基金会。https://dl.acm.org/doi/abs/10.5555/3535850.3535966 重要提示 要引用此出版物,请使用最终发布的版本(如果适用)。请检查上面的文档版本。
从演示和成对偏好推断奖励函数是将强化学习 (RL) 代理与人类意图相结合的良好方法。然而,最先进的方法通常专注于学习单一奖励模型,因此很难权衡来自多位专家的不同奖励函数。我们提出了多目标强化主动学习 (MORAL),这是一种将社会规范的不同演示组合成帕累托最优策略的新方法。通过维持标量权重的分布,我们的方法能够以交互方式调整深度 RL 代理以适应各种偏好,同时无需计算多个策略。我们在两种场景中通过实证证明了 MORAL 的有效性,这两种场景模拟了交付和紧急任务,需要代理在存在规范冲突的情况下采取行动。总的来说,我们认为我们的研究是朝着具有学习奖励的多目标 RL 迈出的一步,弥合了当前奖励学习和机器伦理文献之间的差距。

设计与成就 Kathleen Mullan Harris
有关 Add Health 研究设计、数据类型、数据文档、代码本和访问权限的信息可在我们的网站 (www.cpc.unc.edu/addhealth) 上找到,该网站每月平均点击量超过 56,000 次(Harris 等人,2009 年)。我们还管理着一个 Add Health 研究人员的交互式列表服务器,他们分享重要的数据发现、编码方案和测量策略,并以交互方式讨论和解决数据和分析问题。在 NIH 举办的两年一度的 Add Health 用户大会由 NICHD 共同赞助,出席人数通常超过 150 人,Add Health 研究人员平均发表 60 篇论文,Add Health 工作人员举办教学方法会议。最近 2012 年用户大会的论文摘要发布在 www.cpc.unc.edu/projects/addhealth/events。Add Health 传播核心促进了 Add Health 数据的访问和使用。

基因组学 2 蛋白质门户:将基因筛选结果与蛋白质序列和结构联系起来的资源和发现工具
基于人工智能的方法的最新进展彻底改变了结构生物学领域。与此同时,高通量测序和功能基因组学产生了前所未有的遗传变异。然而,需要有效的工具和资源来链接不同的数据类型——将变异“映射”到蛋白质结构上,更好地了解变异如何导致疾病,从而设计治疗方法。在这里,我们介绍了 Genomics 2 Proteins 门户网站 ( https://g2p.broadinstitute.org/ ):这是一种人类蛋白质组范围的资源,将 20,076,998 个遗传变异映射到 42,413 个蛋白质序列和 77,923 个结构上,具有一套全面的结构和功能特征。此外,Genomics 2 Proteins 门户网站允许用户以交互方式上传蛋白质残基注释(例如,变异和分数)以及数据库之外的蛋白质结构,以建立基因组学与蛋白质之间的联系。该门户网站是一个易于使用的发现工具,可供研究人员和科学家假设自然或合成变异与其分子表型之间的结构-功能关系。

利用生理数据检测强直信息处理活动
通过可穿戴传感器捕捉的生理信号来表征信息处理活动 (IPA),例如阅读、聆听、说话和写作,可以拓宽对人们如何产生和消费信息的理解。然而,传感器对外部条件高度敏感,而这些条件并不容易控制——即使在实验室用户研究中也是如此。我们进行了一项初步研究 (𝑁 = 7),以评估使用多个传感器的四种 IPA(阅读、聆听、说话和写作)中生理信号的稳健性和灵敏度。收集的信号包括皮电活动、血容量脉搏、凝视和头部运动。我们观察到参与者之间的一致趋势,以及四种 IPA 之间具有统计学上显着差异的十个特征。我们的结果为用户遇到 IPA 时生理反应的差异提供了初步的定量证据,揭示了根据 IPA 分别检查信号的必要性。本研究的下一步将进入特定的环境,即信息检索,并且 IPA 被视为与搜索系统的交互方式,例如通过说话或打字提交搜索查询。

454 PlanHelper:支持活动计划构建...
基于社区的问答 (CQA) 平台可以为寻求制定活动计划 (AP)(例如健身或观光)的人提供丰富的经验和建议。然而,CQA 平台中的回答帖子可能过于非结构化且难以理解,无法轻松应用于 AP 构建,这已通过我们为了解相关用户挑战而开展的形成性研究得到证实。因此,我们提出了一个回答帖子处理流程,并在此基础上构建了 PlanHelper,这是一个帮助用户处理 CQA 信息并以交互方式构建 AP 的工具。我们以类似 Quora 的界面为基线进行了一项受试者内研究(N=24)。结果表明,在使用 PlanHelper 创建 AP 时,用户对信息支持的满意度明显更高,并且在交互过程中参与度更高。此外,我们对 PlanHelper 的用户行为进行了深入分析,并总结了此类支持工具的设计考虑因素。

L-CoDe:使用颜色对象解耦条件的基于语言的着色
对灰度图像进行着色本质上是一个具有多模态不确定性的病态问题。基于语言的着色提供了一种自然的交互方式,即通过用户提供的标题来减少这种不确定性。然而,颜色-物体耦合和不匹配问题使得从单词到颜色的映射变得困难。在本文中,我们提出了一种使用颜色-物体解耦条件的基于语言的着色网络 L-CoDe。引入了物体-颜色对应矩阵预测器 (OCCM) 和新颖的注意力转移模块 (ATM) 来解决颜色-物体耦合问题。为了处理导致颜色-物体对应不正确的颜色-物体不匹配问题,我们采用了软门控注入模块 (SIM)。我们进一步提出了一个包含带注释的颜色-物体对的新数据集,以提供用于解决耦合问题的监督信号。实验结果表明,我们的方法优于基于标题的最先进的方法。

动态系统的在线多目标模型独立自适应跟踪机制
摘要:在机器人文献中,最佳跟踪问题通过使用各种鲁棒和自适应控制方法来解决。然而,这些方案与实施限制有关,例如在具有完整或部分基于模型的控制结构的不确定动态环境中的适用性、离散时间环境中的复杂性和完整性以及复杂耦合动态系统中的可扩展性。开发了一种在线自适应学习机制来解决上述限制,并为跟踪控制类问题提供通用的解决方案平台。该方案使用同时线性反馈控制策略最小化跟踪误差并优化整体动态行为。采用基于值迭代过程的强化学习方法来求解底层贝尔曼最优方程。生成的控制策略以交互方式实时更新,而无需任何有关底层系统动态的信息。采用自适应评论家的方法实时逼近最优解值函数和相关控制策略。在仿真中说明了所提出的自适应跟踪机制,以在不确定的气动学习环境下控制柔性翼飞机。

文档成像中的条形码 - 我的所有论文
大容量文档成像系统通常需要高效地捕获、存储、处理和检索数亿个文档图像。虽然这种系统的初始投资很高,但持续的劳动力成本很快就会使这些支出显得微不足道。尽管这些系统采用了高速扫描硬件和有能力的操作员,但净吞吐量很低。通常,错误频发,质量保证成本很高。在这样的系统中,资本设备没有得到充分使用,而人力则被用来执行计算机可以做得更好、更快的任务。原因很简单:文档图像的捕获和索引通常以交互方式执行,其中扫描仪操作员手动输入文档索引信息、执行文档计数、观察纸张处理问题,并在遇到非标准文档时明确更改扫描仪控制参数。可以将条形码添加到文档成像环境中,以实施各种策略,通过更充分利用资本设备并降低给定文档成像应用所需的劳动力成本来减少错误、提高系统吞吐量和节省资金。
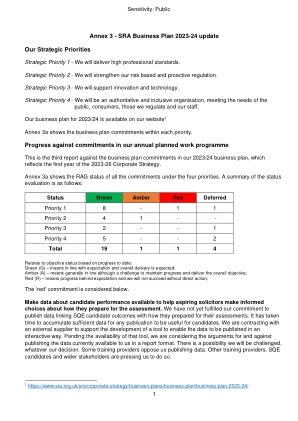
SRA 2023-24 年业务计划更新 我们的战略重点
与基于迄今为止的进展的客观状态相关:绿色 (G) – 表示符合预期,预计总体交付情况良好;琥珀色 (A) – 表示总体符合预期,但保持进度和实现总体目标存在挑战;红色 (R) – 表示进度落后于预期,如果不采取直接行动,我们将无法成功;“红色”承诺如下。提供有关候选人表现的数据,以帮助有抱负的律师就如何准备评估做出明智的选择。我们尚未履行发布将 SQE 候选人结果与他们如何准备评估联系起来的数据的承诺。积累足够的数据以使任何出版物对候选人有用需要时间。我们正在与外部供应商签约,以支持开发一种工具,以便以交互方式发布数据。在该工具可用之前,我们正在考虑以报告格式发布我们目前可用的数据的利弊。无论我们做出什么决定,都有可能受到挑战。一些培训提供商反对我们发布数据。其他培训提供商、SQE 候选人和更广泛的利益相关者都在敦促我们这样做。
文档成像中的条形码 - 我的所有论文
大容量文档成像系统通常需要高效地捕获、存储、处理和检索数亿个文档图像。虽然这种系统的初始投资很高,但持续的劳动力成本很快就会使这些支出显得微不足道。尽管这些系统采用了高速扫描硬件和有能力的操作员,但净吞吐量很低。通常,错误频发,质量保证成本很高。在这样的系统中,资本设备没有得到充分利用,而人力却被用来执行计算机可以做得更好、更快的任务。原因很简单:文档图像的捕获和索引通常以交互方式执行,其中扫描仪操作员手动键入文档索引信息、执行文档计数、观察纸张处理问题,并在遇到非标准文档时明确更改扫描仪控制参数。可以将条形码添加到文档成像环境中,以实施各种策略来减少错误、提高系统吞吐量并通过更充分利用资本设备和降低给定文档成像应用所需的劳动力成本来节省资金。