XiaoMi-AI文件搜索系统
World File Search System人口中心
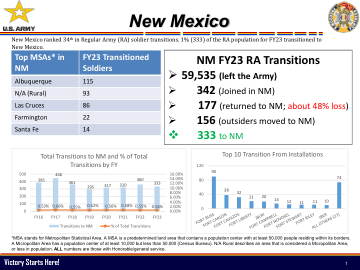
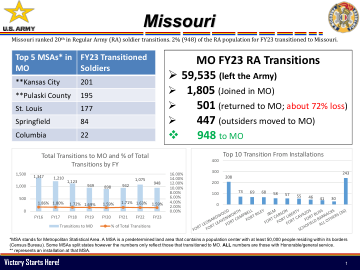
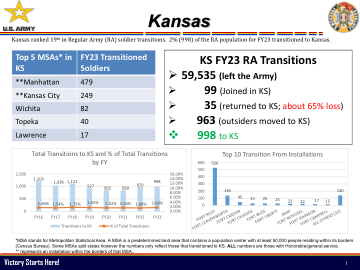
IA FY23 RA 过渡 ❖
*MSA 代表大都市统计区。MSA 是预先确定的土地区域,其中包含一个人口中心,其边界内至少有 50,000 人居住(人口普查局)。一些 MSA 分裂州,但这些数字仅反映过渡到 IA 的数字。所有数字都是那些拥有荣誉/一般服务的人。

Mohanraj Krishnan 博士 宾夕法尼亚州立大学助理教授 北卡罗来纳大学教堂山分校兼职助理教授
地址 生物行为健康 (BBH) 系 宾夕法尼亚州立大学 宾夕法尼亚州立大学公园州立学院,16802 卡罗来纳人口中心 北卡罗来纳大学教堂山分校 123 W. Franklin St. 北卡罗来纳州教堂山,27516 教育 2018 年哲学博士 遗传学 新西兰奥克兰大学。论文:新西兰肥胖遗传研究:SCOPE 儿童研究。 导师:Andrew Shelling 教授 2011 年理学硕士 (MSc) 优异成绩 遗传学 新西兰奥塔哥大学。论文:在新西兰病例对照样本中测试维生素 D 3 代谢基因变异与痛风的关联。 导师:Tony Merriman 教授 2008 年理学研究生文凭 (PgDipSci) 微生物学 新西兰奥塔哥大学。 2007 生物医学科学学士 (BBioMedSci) 健康与疾病的分子基础 奥塔哥大学,新西兰。 专业经历 2024 年至今 终身制助理教授 生物行为健康与癌症研究所 宾夕法尼亚州立大学 2024 年至今 兼职助理教授 遗传流行病学 北卡罗来纳大学教堂山分校 2022 年 - 2024 年 博士后研究员 卡罗来纳人口中心 (CPC)

海上风电有哪些优势?
▪ 高能源潜力: 海上风速通常比陆上风速更快、更稳定,从而能够可靠地生产能源。 ▪ 靠近人口中心: 风速强的地区通常位于人口稠密的地区附近,因此可以战略性地选择租赁区域。 ▪ 土地利用效率: 宝贵的陆上土地可以自由用于其他用途,同时考虑到选择发电地点的机会成本。 ▪ 创造就业机会: 随着行业的发展,工程师、金属工人、电工、涡轮机技术员和许多其他职业的多元化劳动力将供不应求。

Lawrence L. Wu 2025年3月
2015 Wu,Lawrence L.和Steven P. Martin。 “性发作和婚前第一胎:依次危害模型的见解。” 2015年9月在圣路易斯华盛顿大学发表的论文; 2014年11月,耶鲁大学不平等与生命课程中心; 2014年春季RC28的会议,匈牙利布达佩斯;明尼苏达州人口中心;美国社会学协会的2010年年度会议;宾夕法尼亚大学人口研究中心;马里兰大学人口研究中心; 2008年美国人口协会的年度会议;俄亥俄州立大学人口研究计划;威斯康星大学麦迪逊分校贫困研究所低收入研讨会;以及纽约大学的高级社会科学研究中心和人类发展与社会变革研究所。2015 Wu,Lawrence L.和Steven P. Martin。“性发作和婚前第一胎:依次危害模型的见解。” 2015年9月在圣路易斯华盛顿大学发表的论文; 2014年11月,耶鲁大学不平等与生命课程中心; 2014年春季RC28的会议,匈牙利布达佩斯;明尼苏达州人口中心;美国社会学协会的2010年年度会议;宾夕法尼亚大学人口研究中心;马里兰大学人口研究中心; 2008年美国人口协会的年度会议;俄亥俄州立大学人口研究计划;威斯康星大学麦迪逊分校贫困研究所低收入研讨会;以及纽约大学的高级社会科学研究中心和人类发展与社会变革研究所。

城市地形中的多域操作及其对医学努力的影响
他的城市战场长期以来一直是军事规划师存在的祸根。虽然高度紧张的冲突,但在力量上的场景几乎具有科学和分析性的质量,但插管的地形,复杂的人类维度(政治,权力,社会和文化)以及复杂的基础构造需要维持姿势,这表明姿势易于波动,不确定,不确定的,复杂的,复杂的,含糊的问题。因此,毫不奇怪的是,在伊拉克入侵的最初努力是由南部的通过人口中心,以免主体陷入困境。马克·米利(Mark Milley)将军首先担任陆军参谋长,最近担任联合参谋长的董事长,他明确表明,在不久的将来需要在城市战斗。1