XiaoMi-AI文件搜索系统
World File Search System内存

睡眠期间的记忆重新激活不会在对象内存
Siefert,E.M. 1,2*,Uppuluri,S。1,Mu。J.3,Tandoc,M.C。 1,Antony,J.W。 4,Schapiro,A.C。1* 1心理学系,宾夕法尼亚州宾夕法尼亚大学,宾夕法尼亚州费城大学,19104年,美国2宾夕法尼亚州宾夕法尼亚州宾夕法尼亚大学佩雷尔曼医学院,宾夕法尼亚州宾夕法尼亚大学佩雷曼医学院美国 *相应的作者:sieferte@pennmedicine.upenn.edu和aschapir@sas.upenn.edu在睡眠期间抽象的记忆重新激活被认为可以促进记忆巩固。 大多数睡眠重新激活研究都研究了特定事实,对象和关联的重新激活如何使其整体保留率有益。 但是,我们的记忆不是统一的,并且并非记忆的所有特征随着时间的流逝而持续存在。 取而代之的是,我们的记忆是转变的,有些特征加强了,有些特征却削弱了。 睡眠重新激活是否会驱动内存转换? 我们利用对象类别学习范式中的目标内存重新激活技术来检查这个问题。 参与者(20名女性,14名男性)学习了三类新物体,每个对象都具有独特的特征以及与其类别的其他成员共享的特征。 ,我们使用实时脑电图方案在优化的矩矩中以生成重新激活事件的时间来提示这些对象的重新激活。 我们发现,重新激活改善了记忆,以区分特征,同时使共享特征的存储器恶化,这表明了分化过程。3,Tandoc,M.C。1,Antony,J.W。 4,Schapiro,A.C。1* 1心理学系,宾夕法尼亚州宾夕法尼亚大学,宾夕法尼亚州费城大学,19104年,美国2宾夕法尼亚州宾夕法尼亚州宾夕法尼亚大学佩雷尔曼医学院,宾夕法尼亚州宾夕法尼亚大学佩雷曼医学院美国 *相应的作者:sieferte@pennmedicine.upenn.edu和aschapir@sas.upenn.edu在睡眠期间抽象的记忆重新激活被认为可以促进记忆巩固。 大多数睡眠重新激活研究都研究了特定事实,对象和关联的重新激活如何使其整体保留率有益。 但是,我们的记忆不是统一的,并且并非记忆的所有特征随着时间的流逝而持续存在。 取而代之的是,我们的记忆是转变的,有些特征加强了,有些特征却削弱了。 睡眠重新激活是否会驱动内存转换? 我们利用对象类别学习范式中的目标内存重新激活技术来检查这个问题。 参与者(20名女性,14名男性)学习了三类新物体,每个对象都具有独特的特征以及与其类别的其他成员共享的特征。 ,我们使用实时脑电图方案在优化的矩矩中以生成重新激活事件的时间来提示这些对象的重新激活。 我们发现,重新激活改善了记忆,以区分特征,同时使共享特征的存储器恶化,这表明了分化过程。1,Antony,J.W。4,Schapiro,A.C。1* 1心理学系,宾夕法尼亚州宾夕法尼亚大学,宾夕法尼亚州费城大学,19104年,美国2宾夕法尼亚州宾夕法尼亚州宾夕法尼亚大学佩雷尔曼医学院,宾夕法尼亚州宾夕法尼亚大学佩雷曼医学院美国 *相应的作者:sieferte@pennmedicine.upenn.edu和aschapir@sas.upenn.edu在睡眠期间抽象的记忆重新激活被认为可以促进记忆巩固。大多数睡眠重新激活研究都研究了特定事实,对象和关联的重新激活如何使其整体保留率有益。但是,我们的记忆不是统一的,并且并非记忆的所有特征随着时间的流逝而持续存在。取而代之的是,我们的记忆是转变的,有些特征加强了,有些特征却削弱了。睡眠重新激活是否会驱动内存转换?我们利用对象类别学习范式中的目标内存重新激活技术来检查这个问题。参与者(20名女性,14名男性)学习了三类新物体,每个对象都具有独特的特征以及与其类别的其他成员共享的特征。,我们使用实时脑电图方案在优化的矩矩中以生成重新激活事件的时间来提示这些对象的重新激活。我们发现,重新激活改善了记忆,以区分特征,同时使共享特征的存储器恶化,这表明了分化过程。结果表明睡眠重新激活不会在对象记忆上进行整体作用,而是支持某些特征比其他特征增强的转换过程。

Si/SiGe QuBus,用于具有内存和微米级连接功能的单电子信息处理设备
单载流子信息处理设备内的连接需要传输和存储单个电荷量子。单个电子在被限制在移动量子点中的短小、全电 Si/SiGe 穿梭设备(称为量子总线 (QuBus))中被绝热传输。这里我们展示了一个长度为 10 μ m 且仅由六个简单可调的电压脉冲操作的 QuBus。我们引入了一种称为穿梭断层扫描的表征方法,以对 QuBus 的潜在缺陷和局部穿梭保真度进行基准测试。单电子穿梭穿越整个设备并返回(总距离为 19 μ m)的保真度为 (99.7 ± 0.3) %。使用 QuBus,我们定位和检测多达 34 个电子,并使用任意选择的零电子和单电子模式初始化一个由 34 个量子点组成的寄存器。 28 Si/SiGe 中的简单操作信号、与工业制造的兼容性以及低自旋环境相互作用,有望实现自旋量子比特的长距离自旋守恒传输,从而实现量子计算架构中的量子连接。
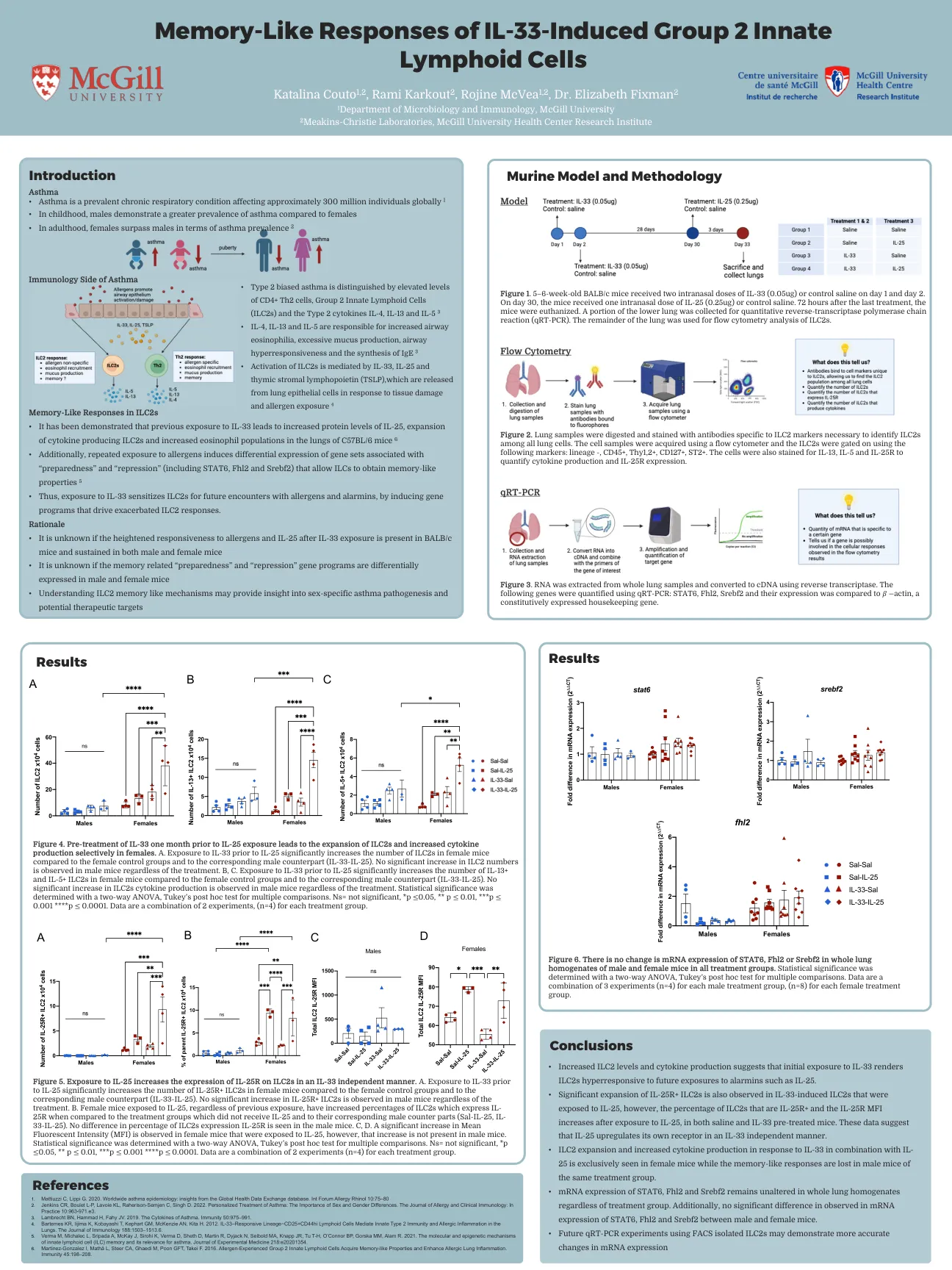
IL-33诱导的第2组先天的内存样响应...
1。Mattiuzzi C,Lippi G.2020。全球哮喘流行病学:来自全球健康数据交换数据库的见解。int论坛过敏犀牛10:75–80 2。Jenkins CR,Boulet L-P,Lavoie KL,Raherison-Semjen C,Singh D. 2022.个性化哮喘的治疗方法:性别和性别差异的重要性。过敏和临床免疫学杂志:实践10:963-971.e3。3。Lambrecht BN,Hammad H,Fahy JV。2019。哮喘的细胞因子。免疫50:975–991。4。Bartemes KR,IIJIMA K,Kobayashi T,Kephart GM,McKenzie AN,Kita H. 2012。IL-33-反应谱系-CD25+CD44HI淋巴样细胞介导肺中先天2型免疫和过敏性炎症。免疫学杂志188:1503–1513.6。5。Verma M,Michalec L,Sripada A,McKay J,Sirohi K,Verma D,Sheth D,Martin R,Martin R,Dyjack N,Seibold MA,Knapp Jr,Tu T-H,O'Connor BP,Gorska BP,Gorska MM,Alam R.2021。先天淋巴样细胞(ILC)记忆的分子和表观遗传机制及其与哮喘的相关性。实验医学杂志218:E20201354。6。Martinez-Gonzalez I,MathäL,Steer CA,Ghaedi M,Poon GFT,Takei F.2016。经验丰富的第2组先天淋巴样细胞获得了记忆样特性并增强过敏性肺部炎症。免疫45:198–208。

Gofetch:使用数据内存依赖的预摘要
微构造的侧通道攻击动摇了现代处理器设计的基础。针对这些攻击的基石防御是为了确保关键安全计划不会使用秘密依赖数据作为地址。简单:不要将秘密作为地址传递给,例如数据存储器说明。然而,发现数据内存依赖性预定器(DMP)(DMP)(将程序数据直接从内存系统内部转换为地址)质疑该方法是否会继续保持安全。本文表明,DMP的安全威胁要比以前想象的要差得多,并使用Apple M-Series DMP证明了对关键安全软件的首次端到端攻击。对我们的攻击进行了探讨,这是对DMP的行为的新理解,该行为表明Apple DMP将代表任何受害者计划激活,并试图“泄漏”任何类似于指针的缓存数据。从这种理解中,我们签署了一种新型的输入攻击,该攻击使用DMP对经典的经典恒定时间实现(OpenSSL Diffie-Hellman键交换,GO RSA解密)和后Quantum Cryptogragra-Phy(Crystals-kyber-kyber-kyber and Crystals-dilith)进行端到端的键提取。

经验重播算法和情节内存的功能
1伦敦经济学和政治科学学院哲学,逻辑和科学方法摘要:情节记忆是过去事件的记忆。它特征在于在思想中“重播”自己的经历的经历。这种生物学现象激发了AI中几种“经验重播”算法的发展。在本章中,我询问经验重播算法是否可能揭示出关于情节记忆功能的难题:情节记忆有什么促进发现它的认知系统?我认为,经验重播算法可以作为情节记忆的理想化模型,以解决这个问题。以DQN算法为案例研究,我建议这些算法为助记符帐户提供了一些支持,在哪些情节内存的功能中,信息在存储,编码和检索信息。通过扩展和适应经验重播算法,我们可能会进一步了解情节记忆的操作和对认知的贡献。关键字:情节内存;经验重播;人工智能;认知角色功能;模型

受过训练的复发性神经网络在工作内存任务中开发相锁的极限周期
神经振荡无处不在。这些振荡的一个提出的功能是它们充当内部时钟或“参考框架”。信息可以通过与此类振荡相相对于神经活动的时间来编码。与这一假设一致,大脑中这种相位代码的经验观察有多种经验观察。在这里我们问:什么样的神经动力学支持神经振荡的信息的阶段编码?我们通过分析经过工作记忆任务培训的经常性神经网络(RNN)来解决这个问题。净作品可以访问外部参考振荡并任务产生振荡,以使参考和输出振荡之间的相位差保持瞬态刺激的身份。我们发现网络收敛到稳定的振荡动力学。逆向工程这些网络表明,每个相位编码的内存都对应于单独的极限周期吸引子。我们表征了吸引力动力学的稳定性如何取决于参考振荡振幅和频率,即可以在实验上观察到的特性。要了解这些动态基础的连通性结构,我们表明训练有素的网络可以描述为两个相耦合的振荡器。使用此洞察力,我们将训练有素的网络凝结为由两个功能模块组成的简化模型:一个生成振荡的模块和一个在内部振荡和外部参考之间实现耦合函数的模型。总而言之,通过对训练有素的RNN的动态和连通性进行反向工程,我们提出了一种机制,神经网络可以利用该机制来利用参考振荡以进行工作记忆。具体来说,我们建议一个相编码网络生成自动振荡,并以多稳定的方式将其与外部参考振荡耦合。

micronas:内存和延迟约束硬件 -
设计域特定的神经网络是一项耗时,容易出错且昂贵的任务。神经体系结构搜索(NAS),以简化特定于域的模型开发,但在微控制器上进行时间分类的文献存在差距。因此,我们调整了可区分的神经修道搜索搜索(DNA)的概念,以解决有关资源约束的Mi-Crocontrollers(MCUS)的时间序列分类问题。我们介绍了Micronas,这是DNA,延迟查找表,动态音量和专门针对MCUS时序列分类设计的新颖搜索空间的DNA,延迟查找表,动态结合表和新颖的搜索空间的Micronas。所得系统是硬件感知的,可以生成满足用户定义的执行延迟和峰值内存消耗的限制的神经网络体系结构。我们在不同的MCUS和标准基准数据集上进行的广泛研究表明,Micronas找到了达到性能的MCU量身定制的体系结构(F1得分),附近是最先进的桌面模型。我们还表明,与独立于域的NAS基准(如DARTS)相比,我们的方法在遵守记忆和潜伏期限制方面具有优越性。

节能计算的 3D 逻辑和内存专题
单片微电子设计面临着巨大的挑战,因为计算内存带宽和延迟的需求日益增长,而计算的能效限制了其性能和成本。尽管最近的进展(例如领域特定加速、近内存和内存计算技术)试图解决这些问题,但单片设计的扩展趋势仍然落后于人工智能算法、高性能计算、高清传感和其他数据密集型应用不断增长的需求。在这种背景下,技术创新,特别是通过封装和单片方法实现的 3D 集成,对于实现异构集成 (HI) 并带来超越传统芯片设计的显著性能、能源和成本优势至关重要。3D 逻辑和内存设计允许灵活地生产和连接异构功能宏(即芯片),具有更高的互连密度、长度减少和面积利用率,为整个微电子设计堆栈开辟了新的机遇。


Hu等人:通过在铁电HF上插入Al 2 O 3 Interlayer的SI Channel FeFet内存窗口的扩大0.5 Zr 0.5 Zr 0.5 O 2 1 1
afnia(HFO 2)基于硅河道铁电场效应晶体管(HFO 2 Si-fefet)已对非挥发性记忆进行了广泛的研究[1-7],这要归功于掺杂的hfo 2 [8]中发现铁电性的。HFO 2 Si-fefet的存储窗口(MW)大约是文献报告中的1-2 V [9-12],该窗口不满足其对在多位数存储单元中应用的要求。最近,通过优化铁电层和栅极侧层间层[13],在SI-FEFET中报告了最高10.5 V的大型MW [13]。但是,它没有给出层中层的材料。及其物理机制仍未报告和澄清。为了改善MW,通常有两种方法。当前方法之一主要集中于减少掺杂的HFO HFO 2铁电和Si通道之间的底部SIO X互层中的电场,从而抑制了在掺杂的HFO 2 /SIO X界面处的电荷捕获[14-17]。另一种方法侧重于改进SIO X数量。但是,仍然缺乏改善Si FeFet MW的有效方法。