XiaoMi-AI文件搜索系统
World File Search System准确

公司财务困扰预测模型的准确性...
摘要本研究旨在获得Altman Z-Score,Zmijewski和Grover模型的准确性的证据,以预测印度尼西亚基础设施部门的财务困扰公司。此外,研究还旨在在公司进行财务预测困扰时获得最准确的模型证明。本研究使用以2018 - 2021年期间上市的基础设施部门公司的年度财务报表的形式进行的辅助数据,总共有26家公司的总样本。结果表明,Zmijewski模型成为一个预测模型,其精度最高为88.46%,这是由I型最低误差率为25%和II型的最低误差率,而II型的误差率为9.09%。因此,Zmijewski模型是印度尼西亚基础架构公司中使用的更合适的预测模型。关键字:预测模型,财务困扰,准确性,基础架构

增强阿尔茨海默氏症的检测:利用ADNI数据和大型语言模型进行高准确性诊断
摘要 - 最常见的痴呆症类型的阿尔茨海默氏病(AD)预计到2050年将影响1.52亿人,强调早期诊断的重要性。这项研究使用阿尔茨海默氏病神经影像学计划(ADNI)数据集,将认知测试,生物标志物,人口统计学细节和遗传数据结合在一起来构建预测模型。使用大型语言模型(LLM),特别是ChatGpt 3.5,我们达到了高分类的精度,认知上正常人(CN)个体的ROC AUC值为0.98,痴呆症的0.99,轻度认知障碍(MCI)0.98。这些发现表明LLM可以快速准确处理复杂的数据。通过关注数值和基于文本的数据而不是仅仅是成像,该方法为诊断AD提供了一种经济高效且易于访问的选项。添加遗传信息可以改善预测,反映了遗传学在AD风险中的重要作用。这项研究突出了将不同类型的数据与先进的机器学习和LSTM相结合以改善早期AD诊断的潜力。未来的研究应探索更多方法来结合数据并测试不同的机器学习模型,以进一步增强诊断工具。

开发利用人工智能生成医疗记录的风险缓解框架对于确保准确性、患者安全和医疗保健标准的合规性至关重要。
将人工智能融入医疗记录生成可提高效率并增强文档记录。然而,它会带来诸如不准确、偏见和安全问题等风险。该框架识别这些风险并提出缓解策略,符合美国国家标准与技术研究院 (NIST) 人工智能风险管理框架等标准。

pangenomes有助于准确检测大插入和...
1。意大利布雷西亚布雷西亚大学分子与转化医学系2。 国家心脏和肺研究所,伦敦帝国学院,英国伦敦3. Velsera Inc,美国马萨诸塞州查尔斯敦4。 皇家布隆普顿和哈雷菲尔德医院,盖伊和圣托马斯的NHS基金会信托基金会,英国5。 MRC医学科学实验室,伦敦帝国学院,伦敦,英国6。 阿斯万心脏中心,阿斯万,埃及7。 Meyer儿童医院,意大利佛罗伦萨8。 生物学和医学遗传学系,捷克共和国布拉格的查尔斯大学和摩托大学医院第二夫人士。 捷克共和国布拉格查尔斯大学和摩托大学医院第二学院心脏病学系10. 意大利佛罗伦萨大学实验与临床医学系11. 遗传学单位,IRCCS ISTITUTO CENTRO SAN GIOVANNI DI DIO DIO FATEBENEFRATELLI,意大利布雷西亚12. SOD Diagnostica Genetica,Azienda Ospedaliero Universitaria Careggi,佛罗伦萨,意大利佛罗伦萨13。 七桥基因组学公司,美国马萨诸塞州查尔斯敦,美国14。 Bristol Myers Squibb,美国马萨诸塞州剑桥市15。 心血管和基因组学研究所,伦敦伦敦市圣乔治大学,英国16。 阿姆斯特丹大学阿姆斯特丹UMC临床和实验心脏病学系,意大利布雷西亚布雷西亚大学分子与转化医学系2。国家心脏和肺研究所,伦敦帝国学院,英国伦敦3. Velsera Inc,美国马萨诸塞州查尔斯敦4。 皇家布隆普顿和哈雷菲尔德医院,盖伊和圣托马斯的NHS基金会信托基金会,英国5。 MRC医学科学实验室,伦敦帝国学院,伦敦,英国6。 阿斯万心脏中心,阿斯万,埃及7。 Meyer儿童医院,意大利佛罗伦萨8。 生物学和医学遗传学系,捷克共和国布拉格的查尔斯大学和摩托大学医院第二夫人士。 捷克共和国布拉格查尔斯大学和摩托大学医院第二学院心脏病学系10. 意大利佛罗伦萨大学实验与临床医学系11. 遗传学单位,IRCCS ISTITUTO CENTRO SAN GIOVANNI DI DIO DIO FATEBENEFRATELLI,意大利布雷西亚12. SOD Diagnostica Genetica,Azienda Ospedaliero Universitaria Careggi,佛罗伦萨,意大利佛罗伦萨13。 七桥基因组学公司,美国马萨诸塞州查尔斯敦,美国14。 Bristol Myers Squibb,美国马萨诸塞州剑桥市15。 心血管和基因组学研究所,伦敦伦敦市圣乔治大学,英国16。 阿姆斯特丹大学阿姆斯特丹UMC临床和实验心脏病学系,国家心脏和肺研究所,伦敦帝国学院,英国伦敦3.Velsera Inc,美国马萨诸塞州查尔斯敦4。 皇家布隆普顿和哈雷菲尔德医院,盖伊和圣托马斯的NHS基金会信托基金会,英国5。 MRC医学科学实验室,伦敦帝国学院,伦敦,英国6。 阿斯万心脏中心,阿斯万,埃及7。 Meyer儿童医院,意大利佛罗伦萨8。 生物学和医学遗传学系,捷克共和国布拉格的查尔斯大学和摩托大学医院第二夫人士。 捷克共和国布拉格查尔斯大学和摩托大学医院第二学院心脏病学系10. 意大利佛罗伦萨大学实验与临床医学系11. 遗传学单位,IRCCS ISTITUTO CENTRO SAN GIOVANNI DI DIO DIO FATEBENEFRATELLI,意大利布雷西亚12. SOD Diagnostica Genetica,Azienda Ospedaliero Universitaria Careggi,佛罗伦萨,意大利佛罗伦萨13。 七桥基因组学公司,美国马萨诸塞州查尔斯敦,美国14。 Bristol Myers Squibb,美国马萨诸塞州剑桥市15。 心血管和基因组学研究所,伦敦伦敦市圣乔治大学,英国16。 阿姆斯特丹大学阿姆斯特丹UMC临床和实验心脏病学系,Velsera Inc,美国马萨诸塞州查尔斯敦4。皇家布隆普顿和哈雷菲尔德医院,盖伊和圣托马斯的NHS基金会信托基金会,英国5。MRC医学科学实验室,伦敦帝国学院,伦敦,英国6。阿斯万心脏中心,阿斯万,埃及7。Meyer儿童医院,意大利佛罗伦萨8。生物学和医学遗传学系,捷克共和国布拉格的查尔斯大学和摩托大学医院第二夫人士。捷克共和国布拉格查尔斯大学和摩托大学医院第二学院心脏病学系10.意大利佛罗伦萨大学实验与临床医学系11.遗传学单位,IRCCS ISTITUTO CENTRO SAN GIOVANNI DI DIO DIO FATEBENEFRATELLI,意大利布雷西亚12.SOD Diagnostica Genetica,Azienda Ospedaliero Universitaria Careggi,佛罗伦萨,意大利佛罗伦萨13。七桥基因组学公司,美国马萨诸塞州查尔斯敦,美国14。Bristol Myers Squibb,美国马萨诸塞州剑桥市15。心血管和基因组学研究所,伦敦伦敦市圣乔治大学,英国16。阿姆斯特丹大学阿姆斯特丹UMC临床和实验心脏病学系,

揭开克罗恩病的面纱:抗聚糖抗体(ACCA、ALCA、AMCA)可提高诊断准确性,同时提供预后价值,尤其是对于 ASCA 血清阴性患者
抗聚糖抗体 (AGA) 包括 ACCA(抗壳聚糖苷)、ALCA(抗层状聚糖苷)和 AMCA(抗甘露二糖苷),是克罗恩病 (CD) 特异性抗体,靶向微生物(例如白色念珠菌和酿酒酵母)中的聚糖(多糖)。它们可能会改变对真菌菌群失调的免疫反应。与 gASCA(抗酿酒酵母)一起使用时,患者血清中 AGA 的存在可将 CD 与溃疡性结肠炎 (UC) 和非 IBD 区分开来,特异性约为 85%。此外,2 个或更多 AGA 同时呈阳性会增加 CD 特异性(>95%),并预测会更快进展为更严重的疾病,并伴有狭窄和瘘管。AGA 的诊断准确性已得到十几项独立的同行评审研究的验证,这些研究涉及 4,000 多名 IBD 患者。 1 AGA 在临床实践中的最新应用和实际表现尚未得到表征。

与临床医生收集和自我收集的阴道拭子相比,Daye诊断棉塞的诊断准确性用于检测HPV:一项比较研究
谁设定了雄心勃勃的目标,以消除宫颈癌到本世纪末(9)。但是,这个目标面临重大挑战。在英国是一个提供有组织的宫颈筛查的高收入国家,最近的数据显示,在2021 - 2022年,只有68.7%的合格个人被充分筛查,远低于80%的目标(10)。此外,大多数癌症表现出来的低收入和中等收入国家,通常没有筛查计划。为了实现消除宫颈癌的目标,迫切需要进行创新的筛查方法。这些必须解决参与障碍和医疗保健系统中的资源限制。虽然阴道自我采样(VSS)已被证明是增加宫颈癌筛查参与的有效策略,尤其是在不强调的人群中(9),有些患者也报告了较低的

人工智能在医疗实验室中的应用确保准确
1。在医疗实验室中的AI介绍(POC)客户反馈数据(2018年)确定了两个有问题的测试和自我报告的主题,这表明诸如Liebman和Conrad的R&D阶段之类的过程很重要,但可能不足以确保在所有情况下都能准确收集样品。这是一个问题,因为疾病控制中心(CDC)归因于造成所有实验室错误的46-68%的46-68%,其中35%是由于样本收集错误,可能导致诸如误诊,不正确的药物给药和患者不适等后果。这尤其令人担忧,因为此阶段完全或部分地在客户的控制之下。此外,Church(2012)最近发现,许多客户没有遵循建议的程序,例如在指纹之前直接使用旋转栅门或水槽。目前,尚不清楚这些发现在多大程度上推广到现场样本收集的标准实践。因此,在收集单一的新鲜血液毛细血管时,问题可能会在干燥的毛细血管血液的收集中识别出可能也有问题。因此,需要进一步的研究,随着世界在线的越来越多,将这项研究扩展到健康科学环境非常重要,尤其是与毛细血管血液的收集有关[1]。

关键的及时工程策略以平衡成本,绩效和准确性
首先,您将需要在提示中清楚地定义所需的响应,以避免AI的误解。例如,如果您要求提供一个新颖的摘要,则清楚地表明您正在寻找摘要,而不是详细的分析。这有助于AI仅专注于您的请求,并提供与您的目标保持一致的响应。
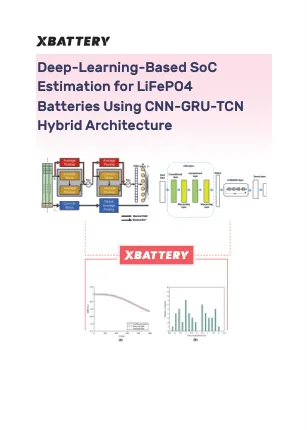
b'摘要\xe2\x80\x94准确估计充电状态 (SOC) 对于储能应用中电池管理系统 (BMS) 的有效和相对运行至关重要。本文提出了一种结合卷积神经网络 (CNN)、门控循环单元 (GRU) 和时间卷积网络 (TCN) 的新型混合深度学习模型,该模型结合了 RNN 模型特征和电压、电流和温度等非线性特征的时间依赖性,以与 SOC 建立关系。时间依赖性和监测信号之间的复杂关系源自磷酸铁锂 (LiFePO4) 电池的 DL 方法。所提出的模型利用 CNN 的特征提取能力、GRU 的时间动态建模和 TCN 序列预测强度的长期有效记忆能力来提高 SOC 估计的准确性和鲁棒性。我们使用来自 In\xef\xac\x82ux DB 的 LiFePO4 数据进行了实验,经过处理,并以 80:20 的比例用于模型的训练和验证。此外,我们将我们的模型的性能与 LSTM、CNN-LSTM、GRU、CNN-GRU 和 CNN-GRU-LSTM 的性能进行了比较。实验结果表明,我们提出的 CNN-GRU-TCN 混合模型在 LiFePO4 电池的 SOC 估计方面优于其他模型。'
b'摘要\xe2\x80\x94准确估计充电状态 (SOC) 对于储能应用中电池管理系统 (BMS) 的有效和相对运行至关重要。本文提出了一种结合卷积神经网络 (CNN)、门控循环单元 (GRU) 和时间卷积网络 (TCN) 的新型混合深度学习模型,该模型结合了 RNN 模型特征和电压、电流和温度等非线性特征的时间依赖性,以与 SOC 建立关系。时间依赖性和监测信号之间的复杂关系源自磷酸铁锂 (LiFePO4) 电池的 DL 方法。所提出的模型利用 CNN 的特征提取能力、GRU 的时间动态建模和 TCN 序列预测强度的长期有效记忆能力来提高 SOC 估计的准确性和鲁棒性。我们使用来自 In\xef\xac\x82ux DB 的 LiFePO4 数据进行了实验,经过处理,并以 80:20 的比例用于模型的训练和验证。此外,我们将我们的模型的性能与 LSTM、CNN-LSTM、GRU、CNN-GRU 和 CNN-GRU-LSTM 的性能进行了比较。实验结果表明,我们提出的 CNN-GRU-TCN 混合模型在 LiFePO4 电池的 SOC 估计方面优于其他模型。'

一种基于计算机视觉的航空视频中准确提取车辆轨迹的方法
车辆轨迹数据拥有有价值的信息,用于高级驾驶开发和交通分析。虽然无人机(UAV)提供了更广泛的视角,但视频框架中小规模车辆的检测仍然遭受低精度的折磨,甚至错过了。本研究提出了一个全面的技术框架,以进行准确的车辆轨迹提取,包括六个主要组成部分:视频稳定,车辆检测,车辆跟踪,车道标记检测,坐标转换和数据denosing。为了减轻视频抖动,使用了冲浪和绒布稳定算法。仅一旦使用X(Yolox)进行多目标车辆检测,就只能看一下一个增强的检测器,并在检测头中包含一个浅特征提取模块,以提高低级和小规模特征的性能。有效的通道注意力(ECA)模块在颈部之前集成,以进一步提高表现力。此外,在输入阶段还应用了滑动窗口推理方法,以防止压缩高分辨率的视频帧。Savitzky-Golay过滤器用于轨迹降低。验证结果表明,改进的Yolox的平均平均精度(地图)为88.7%,比原模型的增强5.6%。与Advanced Yolov7和Yolov8模型相比,所提出的方法分别将MAP@50增加到7.63%和1.07%。此外,已经开发了车辆轨迹数据集,并且可以在www.cqskyeyex.com上公开访问。大多数跟踪(MT)轨迹度量达到98.9%,单侧定位的根平方误差约为0.05 m。这些结果证实,所提出的框架是交通研究中高准确性车辆轨迹数据收集的有效工具。