XiaoMi-AI文件搜索系统
World File Search System参考材料

参考材料8391
(HG-002)此参考材料(RM)用于验证,优化和过程评估目的。它由一个来自个人基因组项目(ID HUAA53E0)的东欧Ashkenazi犹太血统的男性全人基因组样本组成,可以用来评估基因组测序的变体呼叫的性能。RM 8391的单位由一个含有人类基因组DNA的小瓶组成,该小瓶从单一的大生长人类淋巴母细胞系GM24385(标记为HG-002)中提取,从科里尔医学研究所(Camden,NJ)中提取。小瓶含有大约10 µg的基因组DNA,DNA在Te缓冲液中(10 mM Tris,1 mM EDTA,pH 8.0)。该材料旨在通过获得真实阳性,假阳性和假阴性的估计来评估人类基因组测序变体的性能。测序应用可以包括整个基因组测序,整个外显子组测序以及更多靶向测序,例如基因面板。该基因组DNA旨在以与实验室处理和分析提取的DNA相同的方式进行分析。由于RM是提取DNA的,因此它对于评估诸如DNA提取等分析前步骤没有用,但是它确实挑战了测序库制备,测序机以及映射,对齐和变体调用的生物信息学步骤。此RM并非旨在评估随后的生物信息学步骤,例如功能或临床解释。信息值:为单核苷酸变化(SNV),小插入和缺失(Indels)和纯合参考基因型提供信息值。v3.3.2基准集覆盖了GRCH37组件的88%,使用参考文献1中描述的方法。一个信息值被认为是对RM用户感兴趣和使用的值,但是信息不足以评估与该值相关的不确定性。我们使用当前可用的数据和方法来描述和传播对基因型的最佳,最自信的估计。随着新的数据积累,测量和信息学方法的可用,这些数据和基因组特征将随着时间的流逝而保持。HG-002的数据可以在国家生物技术信息中心(NCBI)序列读取存档中的BioSample SAMN03283347下找到。信息值作为一个变体调用文件(VCF),其中包含基准SNV和小indels,以及描述基准区域的TAB划分的“床”文件,其中任何其他变体在基准VCF中没有任何其他变体都应是错误。信息值不能用来建立计量学可追溯性。本报告中引用的文件可在国家生物技术信息中心(NCBI)托管的FTP站点的基因组中获得。基准VCF和基准区域的FTP站点中的基因组是:


外来病毒检测参考材料...
• 病毒检测的敏感性未知 • 检测取决于动物物种对病毒感染的敏感性 • 基于复制病毒引起的可测量病理效应 • 样本相关干扰 • > 18 天的观察期,具体取决于物种 • 全球不鼓励使用动物(3R 倡议!)

easi-tab™ 微生物质控/参考材料
如果您需要的生物或水平不在我们的上述标准产品范围内,请发送咨询至 axiopt@lgcgroup.com,说明所需的生物、所需水平(以每瓶/片 cfu 表示)、第一批所需数量、所需供应的任何规律以及要交付的国家/地区列表,并确认每个地点都拥有进口和接收该生物所需的所有特殊当地许可证。请注意,一些国家/地区要求填写海关表格。我们将确定是否可以获得适当的培养物、定制生产的成本和预计时间。请注意,将有最低订购量(单一类型 40 包)。


标准参考材料2372a 人类 DNA...
目的:该标准参考材料 (SRM) 用于人类基因组脱氧核糖核酸 (DNA) 定量材料的值分配,主要用于定量聚合酶链式反应 (qPCR)。注意:有关可识别的私人信息,请参阅第 2 页的“使用和隐私协议”。描述:一个 SRM 2372a 单位包含三种特征明确的人类基因组 DNA 材料,溶于 pH 8.0 水性缓冲液中。这些成分来自人类白膜样本,标记为 A、B 和 C。成分 A 包含来自单个男性供体的基因组 DNA。成分 B 包含来自单个女性供体的基因组 DNA。成分 C 包含基因组 DNA 的重量混合物(1 份男性供体和 3 份女性供体)。一个 SRM 单位包含每个成分一个 0.5 mL 无菌小瓶,每瓶约含有 50 µL DNA 溶液。每个小瓶都贴有标签,并用彩色编码的螺帽密封。认证值:认证值列于下表。这些认证值是根据 8 条染色体上的 10 个独特靶标的液滴数字聚合酶链式反应 (ddPCR) 检测计数、稀释因子和液滴体积测量值确定的。NIST 认证值是 NIST 对其有最高信心的值,因为已考虑了所有已知或可疑的偏差来源 [1]。拷贝数值在计量学上可追溯到自然单位计数 1 和比率 1 以及国际单位制 (SI) 得出的体积单位。DNA 质量浓度值在计量学上可追溯到自然单位计数和比率 1 以及 SI 得出的质量和体积单位。

敏捷的无机认证参考材料和标准
所有敏捷光谱CRM均使用美国国家标准技术研究所(NIST)开发的高性能光谱方案1认证。认证的浓度和不确定性值都可以追溯到NIST标准参考材料(SRM),以确保最高准确性和完整的可追溯性。NIST使用高性能ICP-OE来证明其SRM 3100系列光谱单元解决方案标准。nist建议所有标准制造商都使用此技术来证明具有高精度,低不确定性和直接可追溯性的单一元素标准,并对NIST SRM 3100系列进行了可追溯性。
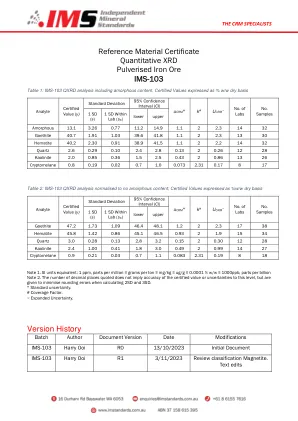
参考材料证书定量XRD粉碎...
•经过认证的价值是通过实验室平均值的平均分析物的平均值来确定的,没有实验室结果的分析物或实验室中位数中位数的中位数的平均值。•标准偏差是分析物确定扩散的度量,包括实验室间偏见,方法不确定性和材料同质性不确定性。使用相同分析方法的确定的约95%预计将在认证值的两侧两侧之间。标准偏差是根据经过验证的实验室数据数据计算得出的,较少的实验室和个体确定。•在实验室标准偏差(S W)内是确定值在报告实验室中的平均分布,较少的实验室和个体确定。这是由参与实验室组的单个因素方差分析计算得出的•置信区间(CI)是对材料在95%置信区间中对材料中的真实(不可知)分析物浓度的估计。例如,可以解释95%CI,因为有0.95的概率是真实值在认证值±CI之间。间隔越窄,认证值越精确。95%CI不应用于确定质量控制门。•标准不确定性(U CRM)是表征,同质性和稳定性研究的差异之和。表征的不确定性来自

熟练度测试(PT)和参考材料(RM)的一般信息
•我们的RM中的平均值和初步接受限是基于ISO和NMKL方法的分析。其他方法不一定总是在相同的间隔内给出结果。•我们始终建议您使用特定于实验室的控制图表,并具有特定于实验室的控制间隔。这尤其是如果您通常获得偏离RM指令中的平均值和初始控制限制的结果。•我们的RM经常在瑞典食品局的同质性上进行分析。这些常规测试中的结果应表明小瓶之间的不均匀性 - 或浓度偏离超过±2s 0(如说明中提供) - 我们将向购买受影响RM的所有实验室发送一封包含信息的电子邮件。

SRM NIST 标准参考材料 2018 年目录
IST 标准参考材料® (SRM) 被工业界、政府和学术界用来确保最高质量的测量。该目录列出了 NIST 生产和销售的 1200 多种单独的参考材料,每种材料的化学成分和物理性质都有精心指定的值。SRM 可用于校准仪器和确保质量保证计划的长期完整性。它们也是验证重要测量结果和开发新测量方法的关键机制。SRM 为用户提供了工具,以帮助建立测量结果与国际单位制 (SI) 的可追溯性。每个 SRM 都经过精心包装,并附带文档,其中包含指定值和规定的不确定性以及材料安全数据表(如果适用)。还包括有关使用、稳定性和 NIST 分析方法的详细信息。如需更多信息和价格,请联系我们:电话:(301) 975-2200 传真:(301) 948-3730 电子邮件:srminfo@nist.gov www.nist.gov/srm 请注意:表格是为了便于比较一系列材料,帮助客户根据自己的需求选择最佳 SRM。对于特定值和不确定性,证书是唯一的官方来源。本目录中提供的数据不断修订。如需了解最新信息,请访问我们的网站 https://www.nist.gov/srm。