XiaoMi-AI文件搜索系统
World File Search System取药

开始使用您的 CVS Caremark® 药房福利计划
了解您的承保范围查明您的计划是否承保某种药物,查看低成本选项,比较在一家药房与另一家药房取药的费用,以及使用检查药品成本工具了解更多信息。 * 注意:如果您在网络外的药房取药,您的处方费用可能不包括在内。



健康计划比较表 符合医疗保险资格的退休人员
HealthSelect MA PPO 和 HealthSelect Secondary 包括通过 HealthSelect SM Medicare Rx 提供的全面处方药保险,由 Express Scripts Medicare ® 管理。您为药物支付的费用份额取决于药物等级、您购买的数量(30 天、60 天或 90 天的供应量)以及处方是在零售药房、延长日供应药房 (EDS) 还是邮购药房取药。一般来说,只有当您无法使用网络药房时,我们才会承保在网络外药房取药。请参阅承保证明,了解有关使用网络外药房时的承保的更多信息。非维持药物是为临时使用或短期疾病开具的药物。维持药物是针对长期疾病更定期服用的药物。

移动处方激活现已推出!
您现在已在 Kirk Pharmacy 以 QXXX 的身份登记。我们将处理过去 7 天内输入的处方。取药时您将收到短信。如果您在 3-4 小时内没有收到短信,请拨打 410-278-1936 联系药房。14 天内未取的处方将被退回。

医疗保险处方付款计划
它是如何运作的?选择加入后,您将照常取药,但您无需向配药药房支付费用。相反,您将从选择加入之日起收到一份基于处方索赔的药物或健康计划月结单。如果您对药物的费用分摊有疑问,请在将药物带回家之前咨询药房或联系您的 Cigna Healthcare 计划。该计划可能会帮助您管理每月的开支,但它不会为您省钱或降低您的药物成本。

领导信息网络连接 (LINC)
Q-Anywhere 将于 2023 年 1 月 9 日推出,减少您在药房等待新处方或续订处方的时间。使用 Q-Anywhere 远程药房签到,您可以通过手机上的一条简单短信激活您的处方。药房将处理您在过去 2 周内输入的所有新/续订处方(无续订),并在准备好取药时向您发送短信。通过使用 Q-Anywhere,您将能够绕过诊所签到并等待!号码和二维码将于 2023 年 1 月 9 日星期一发布

完整药品清单(处方集)2024
在等待例外情况期间,我能否获得药物?作为我们计划的新会员或现有会员,如果您的药物不在我们的药物清单上,或者有规则或限制,我们可能会承保您的临时药物供应。例如,您可能需要事先获得我们的授权才能取药。在获得临时供应期间,您应该与医生交谈,以确定药物清单上是否有类似的药物可以代替您服用。如果您和您的医生决定这是唯一适合您的药物,您需要申请例外情况。有关例外情况的更多信息,请查看您的承保证明。

完整药品清单(处方集)2024
在等待例外情况期间,我能否获得药物?作为我们计划的新会员或现有会员,如果您的药物不在我们的药物清单上,或者有规则或限制,我们可能会承保您的临时药物供应。例如,您可能需要事先获得我们的授权才能取药。在获得临时供应期间,您应该与医生交谈,以确定药物清单上是否有类似的药物可以代替您服用。如果您和您的医生决定这是唯一适合您的药物,您需要申请例外情况。有关例外情况的更多信息,请查看您的承保证明。
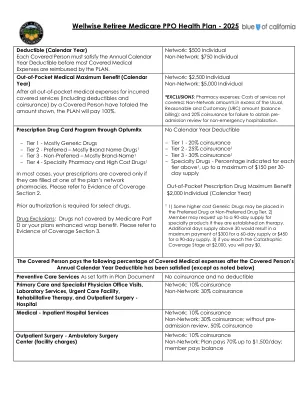
Wellwise 退休人员医疗保险 PPO 健康计划 - 2025 年
通过 OptumRx 的处方药卡计划 - 第 1 级 - 大部分为仿制药 - 第 2 级 - 首选 - 大部分为品牌药 1 - 第 3 级 - 非首选 - 大部分为品牌药 1 - 第 4 级 - 专科药房和高价药 1 在大多数情况下,只有在计划的网络药房之一取药时,您的处方才可获得承保。请参阅承保范围证明第 2 部分。部分药物需要事先授权。药物排除:Medicare Part D 或您的计划增强型综合福利未涵盖的药物。请参阅承保范围证明第 3 部分。