XiaoMi-AI文件搜索系统
World File Search System句法结构
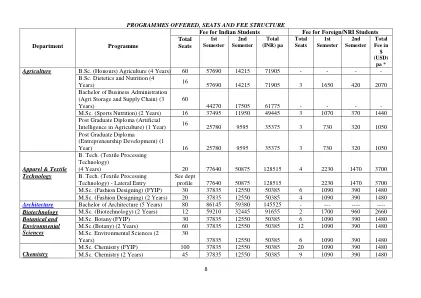
费用结构
M.Sc. 动物学(2年)60 68550 25075 93625 12 1950 750 2700 M.Sc. 动物学(FYIP)30 68550 25075 93625 6 1950 750 2700注:i)选定的学生将必须在相关部门的公告委员会显示出座位上显示座位的座位空缺并在候补名单上分配给候选人的座位后的公告委员会失败后的两个工作日内存入费用。 但是,学生选择了为B.Tech./B.Arch。 计划在咨询时必须在现场存入费用。 ii)除了上述计划费用外,入院时还将收取考试费(如适用)。 外国/NRI学生可以在印度卢比支付考试费。 iii)学费的折扣可以向主要GNDU校园的各种计划的“外国/NRI学生类别”下的应得的学生提供。 iv)**这些程序将由I.T.中心运行。 解决方案。M.Sc.动物学(2年)60 68550 25075 93625 12 1950 750 2700 M.Sc.动物学(FYIP)30 68550 25075 93625 6 1950 750 2700注:i)选定的学生将必须在相关部门的公告委员会显示出座位上显示座位的座位空缺并在候补名单上分配给候选人的座位后的公告委员会失败后的两个工作日内存入费用。但是,学生选择了为B.Tech./B.Arch。计划在咨询时必须在现场存入费用。ii)除了上述计划费用外,入院时还将收取考试费(如适用)。外国/NRI学生可以在印度卢比支付考试费。iii)学费的折扣可以向主要GNDU校园的各种计划的“外国/NRI学生类别”下的应得的学生提供。iv)**这些程序将由I.T.中心运行。解决方案。

信息受限的神经语言模型揭示不同大脑区域对语义、句法和上下文的敏感性
神经语言学的一个基本问题涉及语音理解过程中涉及句法和语义处理的大脑区域,包括词汇(文字处理)和超词汇层面(句子和话语处理)。这些区域在多大程度上是分离的或交织的?为了解决这个问题,我们引入了一种新方法,利用神经语言模型生成分别编码语义和句法信息的高维特征集。更准确地说,我们在文本语料库上训练词汇语言模型 GloVe 和超词汇语言模型 GPT-2,我们从中选择性地删除了句法或语义信息。然后,我们评估从这些信息受限模型中得出的特征在多大程度上仍然能够预测人类聆听自然文本的 fMRI 时间过程。此外,为了确定参与超词汇处理的大脑区域的整合窗口,我们操纵提供给 GPT-2 的上下文信息的大小。分析表明,虽然大多数参与语言理解的大脑区域对句法和语义特征都很敏感,但这些影响的相对大小在这些区域有所不同。此外,与语义或句法特征最相符的区域在左半球比在右半球在空间上分离得更开,而右半球对较长的上下文的敏感性高于左半球。我们方法的新颖之处在于能够通过操纵训练集来控制模型嵌入中编码的信息。这些“信息受限”模型补充了以前使用语言模型探索语言神经基础的研究,并为其空间组织提供了新的见解。

人类大脑结构左右不对称的遗传结构
人类大脑的特点是其左右轴 1 存在各种人群水平的不对称,包括左半球相对于右半球向后和向腹侧延伸的整体“扭矩”,额枕叶皮质厚度梯度的左右差异 2 ,以及大脑侧裂周围半球的形态差异 3 。许多大脑功能也是侧化的,包括手部运动控制和语言,大约 85% 的人表现出左半球占主导地位 4 – 13 。据报道,各种认知和精神障碍都出现了大脑或行为不对称的改变 7、14 – 17 ,这表明人群典型的不对称与人类大脑的最佳功能有关。大脑的行为和解剖不对称在子宫内就已明显 1,18-20 ,这表明大脑左右轴形成的早期遗传发育程序 21,22 。内脏器官发育(心脏、胃、肝脏等)的研究表明,群体水平不对称的产生需要早期胚胎中至少三个重要步骤 23,24 :(1)打破双侧对称性,创建相对于前后轴和背腹轴具有一致方向的左右轴,(2)在早期胚胎结构的左侧和右侧触发不同的基因表达模式,(3)不对称基因表达转化为侧化形态和器官位置。原则上,建立胚胎的左右轴需要某种程度的手性,即关键的生物分子或细胞结构只以两种可能的镜像形式存在。地球上的生命以 L 型氨基酸而非镜像 D 型氨基酸为基础,这种手性延续到初级纤毛 25,26 的宏观结构和运动中,这有助于在胚胎中形成内脏器官的左右轴 25。然而,当内脏器官因突变而发生内脏内位逆位(即内脏器官在左右轴上的位置颠倒)时,语言和手部运动控制的半球优势通常不会逆转

蛋白质结构预测,结构生物信息学和深度学习
蛋白质结构预测对于理解蛋白质稳定性和相互作用至关重要。它具有巨大的药物发现和蛋白质工程潜力。然而,尽管结构生物信息学和人工智能方面取得了进步,但仍需要确定结构预测的标准化模型。即使像Alphafold这样的突出模型也经常发生建筑变化。为了解决这一差距,已经介绍了最新进展和深度学习蛋白质结构预测的挑战的全面细节。此外,还引入了用于用户提供的蛋白质序列的结构预测和可视化的基准系统。,人们已经引入了有效,准确的方法来破译蛋白质结构及其生物学作用,而已引入了葡萄蛋白。该模型利用了变压器结构的有效表示学习能力,可以直接预测整数编码的氨基酸序列的次级和三级结构。结果证明了摄取蛋白在二级结构预测中的作用。对于增强其在预测高阶结构方面的性能是必要的进一步完善。现在

定量语义中对称性的分析
从线性逻辑,定量语义中汲取灵感旨在代表有关程序及其执行的定量信息:它们包括关系模型及其众多扩展,游戏语义和句法方法,例如非互动交叉点类型以及taylor的扩展。这些模型的关键特征是将程序解释为消耗资源“袋子”的证人。“袋子”通常被视为有限的多人,即商结构。在关系模型的分类中通常看到的另一种方法是使用无关紧要的结构(例如secience)与此处称为符号的显式形态有关,表达资源的交换。对称性显然是这些分类模型的核心,但我们认为它们的兴趣超出了这些模型,尤其是,在某些非分类的定量模型(例如加权关系模型或泰勒的扩展)中,对称性泄漏在数字形式下的组合解释形式并不总是清晰。在本文中,我们建立在一个最近的生物模型的基础上,称为Clairambault和Forest介绍的类似薄的群。不明确,细跨度具有对称性分解为两种偏光和负对称性的亚组。我们首先根据序列而不是家庭构建薄跨度原始指数的变体。然后,就刚性相交的类型和刚性资源术语而言,我们对薄跨度简单类型的the的解释进行了句法表征。最后,我们将薄跨度与加权的相对模型和广义结构物种相关联。这使我们能够展示这些模型中的某些数量如何反映两极分化的符号:特别是我们表明,加权的关系模型是从一般结构物种中计数的证人,除以一组正对称性的基本主教。

在听故事中使用词语上下文语义进行 MEG 编码
大脑编码是将刺激映射到大脑活动的过程。关于功能性磁共振成像 (fMRI) 的语言大脑编码,有大量与句法和语义表征相关的文献。脑磁图 (MEG) 具有比 fMRI 更高的时间分辨率,使我们能够更精确地观察语言特征处理的时间。与 MEG 解码不同,使用自然刺激的 MEG 编码研究很少。现有的关于故事聆听的研究侧重于音素和简单的基于单词的特征,而忽略了上下文、句法和语义方面等更抽象的特征。受先前 fMRI 研究的启发,我们使用基本的句法和语义特征,以不同的上下文长度和方向(过去与将来)对 8 名听故事的受试者的数据集进行 MEG 大脑编码研究。我们发现 BERT 表示可以显著预测 MEG,但不能预测其他句法特征或词向量(例如 GloVe),这使我们能够在听觉和语言区域随时间以分布式方式对 MEG 进行编码。特别是,过去的背景对于获得显著的结果至关重要。索引术语:大脑编码、人机交互、MEG、句法、语义、上下文长度

2025年生物信息学与计算生物学国际学术会议
基因组学和疾病研究、高通量数据分析、网络生物学、计算遗传学、模型解释和可视 化、生物数据挖掘、比较基因组学、机器学习和医学影像分析、蛋白质结构与功能预测、 宏基因组学与微生物组、知识图谱构建、生物信息学工具开发、转录组学和表达谱的分析、 药物发现与设计、遗传流行病学、蛋白质组学、个性化医疗与精准医学、生物医学工程、 结构生物信息学、计算工具和软件开发、进化生物信息学、系统生物学、环境与生态计算 生物学和流行病学、计算生态学、序列分析、模式识别与生物信号处理、生物信息学与统 计分析、下一代测序技术、计算生物学与人工智能的融合、生物数据挖掘、处理与分析、 计算医学与临床应用、代谢组学、生物信息学工具与网络科学。

密歇根州聋哑或听力障碍学生交流计划 (DHH)
交流和语言是学习的基础。聋哑或听力障碍 (DHH) 学生的交流方式多种多样。语言是一种使用单词(口头、书面或手语)的系统,具有语法、句法和语用结构和规则。交流方式是支持语言习得和/或提供更完整语言途径的技巧、策略和理念。交流方式本身并不是语言。此交流计划是一种工具,可以促进围绕学生独特需求进行有意义的讨论。

自动机理论和形式语言的半群
I.引言Semigroups是抽象代数中基本代数结构的基本代数结构,在数学和计算机科学的各个领域都有重要的应用。半群是配备了关联二进制操作的集合,使其成为代数中最简单但最通用的结构之一。半群的重要性不仅限于纯数学,而是扩展到理论计算机科学,尤其是在自动机理论和正式语言中[1,2,3]。Automata理论,理论计算机科学的基础区域,研究摘要机器及其解决的问题。有限的自动机是最简单的计算模型之一,通过句法半群的概念与半群密切相关,这些概念是自动机识别的语言[4,5]。具体来说,有限自动机的状态可以解释为半群的元素,并且状态之间的过渡是由半群操作定义的。自动机和半群之间的这种相互作用为理解计算过程和语言识别提供了一个强大的框架[6,7]。在正规语言的研究中,半群在形式语言理论中的应用尤其明显,这正是有限自动机识别的语言类别。普通语言可以通过正则表达式描述,又可以将其映射到有限的自动机。每种普通语言都有相关的句法半群,这是一个封装