XiaoMi-AI文件搜索系统
World File Search System商学

Aaron M. Schecter-特里商学院 - UGA
Brunswicker,S。&Schecter,A。(2019)。连贯性还是灵活性?开发人员在开放平台上的数字创新轨迹的变化悖论。研究政策,48(8),103771。Hukal,P.,Berente,N.,Germonprez,M。,&Schecter,A。(2019)。机器人在开源软件项目中协调工作。计算机,52(9),52-60。Schecter,A.,Pilny,A.,Leung,A.,Poole,M.S。,&Contractor,N。(2018)。逐步:通过关系事件序列捕获工作团队过程的动态。组织行为杂志,39(9),1163-1181。Pilny,A.,Schecter,A.,Poole,M.S。,承包商,N。(2016年)。关系事件模型的例证,用于分析组交互过程。小组动态:理论,研究和实践,20(3),181-195。


与列日卢森堡高等商学院合作开设的在线课程 2025 年 2 月至 6 月
本课程由卢森堡列日高等商学院 (HEC Liège Luxembourg) 为卢森堡金融技术之家 (Luxembourg House of Financial Technology) 提供支持,为学员提供了一个实践机会,帮助他们制定有效的人工智能战略,并在组织内管理人工智能战略。课程将对人工智能的采用和组织变革所带来的挑战和机遇提供具体的见解,学员将了解人工智能在营销、客户分析、金融和未来工作领域的变革潜力。学员还将探索道德考量、负责任的实践以及分析性和批判性思维。学员将探索人工智能如何推动创新、增强决策能力并为组织创造价值。
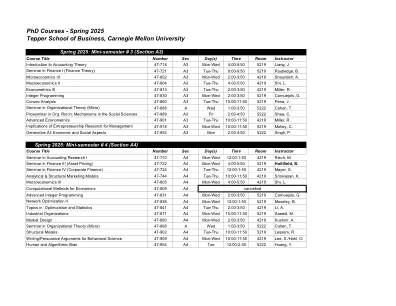
博士课程 - 卡内基·梅隆大学(Carnegie Mellon University)2025年春季特珀商学院
凸分析47-860 A3 TUE-TUE-THU 10:00-11:50 5219 PENA,J。组织理论研讨会(Micro)47-888 A Wed 1:00-3:50 5222 Cohen,Cohen,T。Proseminar in org in org in org。rsrch:社会科学中的机制47-889 A3星期五2:00-4:50 5222 Shea,C。

Kathryn M. Holmstrom,博士,CPA-常春藤商学院
工作论文Holmstrom,K。M.和C. P. H. Peters。生成的AI自动化如何影响审计人的动机和判断质量?•接受2024 PCAOB/ TAR注册报告会议。•在会计审查中修订第3轮注册报告过程。Griffith,E。E.,K。M. Holmstrom和C. Malone。多样性,公平和审计行业的包容性。可在ssrn.com上找到。•在会计,组织和社会上进行第二轮修订。Holmstrom,K。M.审计师对不透明审计方法的依赖:审核员所有权和任务知识的影响。可在ssrn.com上找到。•基于论文(共同主席:Kathryn Kadous和Kathy Rupar)•修订以提交会计研究杂志。•被授予审计质量访问审计人员赠款中心。Holmstrom,K。M.,S。Jackson和K. Rennekamp。 投资者对首席执行官性别和公司绩效的反应。 •修订手稿Holmstrom,K。M.,S。Jackson和K. Rennekamp。投资者对首席执行官性别和公司绩效的反应。•修订手稿

商学院物流与供应理学硕士...
证明:我特此证明,据我所知,本申请中包含的信息真实无误。我可能需要提供额外的证明文件以便稍后核实此信息。我同意将我在佛罗里达国际大学的任何记录信息(包括成绩和GPA)披露给任何联邦、州或私人机构,以便管理奖学金项目。我理解,如果我获得奖学金或豁免,但如果我未能保持学术水平、未能修满学位课程所需的学分、转出商学院、退出佛罗里达国际大学或商学院院长认定的其他正当理由(包括但不限于本申请中的信息失实),奖学金或豁免可能会被撤销。尽管有上述规定,根据与经济援助资格相关的适用法律,我理解我



迈克尔·F·普莱斯商学院
Ty Anderson,财务和运营执行董事 Ron Bolen,Sooner Launch Pad 执行董事 Ronald Davidson,医疗保健业务中心执行董事 Eddie Edwards,MBA 项目执行董事 Dipankar Ghosh,能源研究所执行董事 Shad Satterthwaite,航空航天和国防高管项目执行董事 David Kinsinger,创业法律诊所执行董事 Jared McDuffy,发展执行董事 Jeff Moore,I-CCEW 执行董事 Nick Tobey,高管教育执行董事 Erin Wolfe,研究生成功中心高级总监 Annaly Beck,留学和奖学金总监 Breea Clark,JCPenney 领导力中心总监 Adam Clinton,能源研究所运营总监 Sherad Cravens,学生成功中心总监 Joe Daves,第一年体验@Price 总监

JMU商学院建议清单
Class Credits Pre-Requisite(s) and/or Co-Requisite(s) COB 191 – Business Analytics I 1 3 Pre: MATH 155, calculus, or sufficient score on math placement exam COB 202 – Interpersonal Skills 3 Pre: Sophomore standing COB 204 – Computer Information Systems 3 COB 241 – Financial Accounting 3 Pre: Sophomore standing COB 242 – Managerial Accounting 3 Pre: COB 241 COB 291 - 业务分析II 3前:微积分和COB 191或同等的ECON 200 - 宏观经济概论2 3 ECON 201-微观经济学概论3 MATH 205或MATH 235 - 微积分3 3 3 Pre:MATH 135/155或在数学上足够的分数27