XiaoMi-AI文件搜索系统
World File Search System图像生成

改进基于能量的模型的对比散度训练
对比散度是一种常用的基于能量的模型训练方法,但众所周知,它在训练稳定性方面存在困难。我们提出了一种改进对比散度训练的改进方法,即仔细研究一个难以计算且经常为了方便而被忽略的梯度项。我们表明,这个梯度项在数值上是显著的,在实践中对于避免训练不稳定很重要,同时易于估计。我们进一步强调了如何使用数据增强和多尺度处理来提高模型的鲁棒性和生成质量。最后,我们通过实证评估了模型架构的稳定性,并在一系列基准测试和用例(如图像生成、OOD 检测和组合生成)上展示了改进的性能。

夸克和胶子喷流产生的量子扩散模型
扩散模型在图像生成方面表现出色,但它们的计算量大且训练耗时。在本文中,我们介绍了一种新型扩散模型,该模型受益于量子计算技术,可以减轻计算挑战并提高高能物理数据的生成性能。全量子扩散模型在前向过程中用随机酉矩阵取代高斯噪声,并在去噪架构的 U-Net 中引入变分量子电路。我们对来自大型强子对撞机的结构复杂的夸克和胶子喷流数据集进行了评估。结果表明,全量子和混合模型在喷流生成方面可与类似的经典模型相媲美,凸显了使用量子技术解决机器学习问题的潜力。


Imagen 3 -Googleapis.com MTR V3:2024 Waymo Open DataSet挑战的第一名解决方案 - 运动预测 Gemma 3技术报告-Googleapis.com 2025年1月的学期清单-Googleapis.com
文本对图像(T2I)模型驱动了许多用例,例如在图像生成和编辑中以及场景理解。在此技术报告中,我们概述了Google Imagen家族中最新模型的培训和评估,Imagen3。在其默认配置下,Imagen 3以1024×1024分辨率生成图像,然后可以进行2×,4×或8×UPS采样。我们对其他最先进的T2I模型描述了我们的评估和分析。我们发现Imagen 3比其他模型更优选。特别是,它在光真相和遵守长而复杂的用户提示方面表现良好。部署T2i模型引入了许多新的挑战,我们详细描述了专注于了解与该模型家族相关的安全性和责任风险,以及我们为减少潜在危害的努力。

守法的人工智能与人权(AI权利)的契合
摘要:本文考虑了人工智能的协调问题,以维护法律和人工智能的人权(AI 权利)。本文提出了(1)合规架构和(2)超级清洁架构作为两种遵守法律的架构,并提出了(1)合规 AI、(2)体面 AI 和(3)超级数据清理作为与这两种架构相关的三个概念。本文展示了图像生成 AI 中合规架构和超级清洁架构的示例,以遵守版权法。本文讨论了当人工智能获得一定程度的自主权时与通用人工智能的人权(AI 权利)相关的 AI 协调问题。本文提倡技术和法律考虑之间的跨学科解决方案。

生成式人工智能:斯坦福大学人工智能研究所的观点
5.4 亿年前,动物物种数量在很短的时间内激增。关于当时发生的事情有很多理论,但其中一种理论引起了我的注意:视觉的突然出现和随后的进化。今天,视觉感知是一种主要的感觉系统,人类的大脑可以识别世界上的模式,并根据这些模式生成模型或概念。赋予机器这些能力,即生成能力,一直是许多代人工智能科学家的梦想。生成模型的算法尝试历史悠久,进展程度各不相同。1966 年,麻省理工学院的研究人员开发了“夏季视觉项目”,以利用技术有效地构建“视觉系统的重要部分”。这是计算机视觉和图像生成领域的开端。

白皮书《物流中的人工智能》
在过去的几年中,人工智能 (AI) 已成为许多报纸文章、专家小组、论坛以及商界的主要话题(即使不是主要话题)。尤其是随着生成式人工智能领域的最新发展和发布迅速占领市场并改变经济,例如 OpenAI 的聊天机器人 ChatGPT* 和 Midjouney**, Inc. 的图像生成工具 Midjourney,关于人工智能在所有私营和工业领域的潜力的讨论已经获得了新的关注。欧盟通过建立一个名为《欧盟人工智能法案》的监管框架来支持这些创新技术的开发和使用。《人工智能法案》的目标是确保欧盟使用的人工智能系统安全、透明、可追溯、非歧视性和环保,并在 2023 年底前就新法律达成协议 [1]。
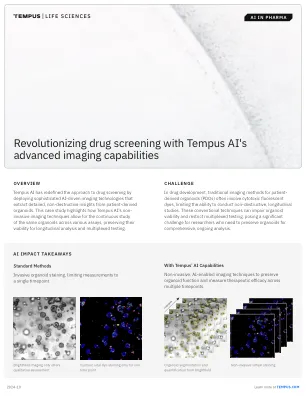
利用 Tempus AI 的先进成像功能彻底改变药物筛选
Tempus AI 开发了一种基于神经网络的模型,可将光学显微镜图像转换为虚拟荧光图像,从而无需使用细胞毒性染料。此外,该模型更引人注目的扩展比虚拟染色更进一步,可以预测药物对光学显微镜图像中存在的所有类器官的疗效,从而实现对药物反应的时间监测。该模型称为正则化条件对抗 (RCA) 网络,是生成对抗网络 (GAN) 的创新扩展,专为图像生成和生存力预测而量身定制。RCA 网络在多种癌症类型的 29,000 多对图像的多样化数据集上进行训练,可准确复制荧光信号并直接从明场图像评估药物反应。
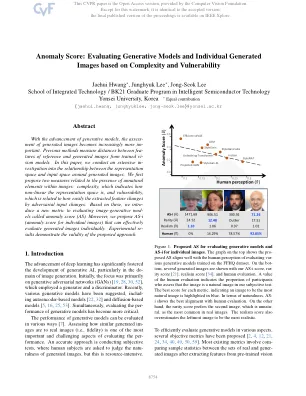
异常得分:根据复杂性和脆弱性评估生成模型和个体生成的图像
随着生成模型的发展,生成图像的评估变得越来越重要。先前的方法测量参考文献和从训练有素的VI-SION模型产生的图像之间的距离。在本文中,我们对表示图像周围的表示空间与输入空间之间的关系进行了广泛的影响。我们首先提出了与图像中不自然元素存在有关的两项措施:复杂性,这表明表示空间的非线性和脆弱性是与对抗性输入变化的轻易变化相关的脆弱性。基于这些,我们为评估称为异常评分的图像生成模式(AS)进行了新的指标。此外,我们提出了可以有效地评估生成的图像的AS-I(单个图像的异常得分)。实验性依据证明了所提出的方法的有效性。

Statstalk -Africa:经济学和统计中的生成AI应用 - 第1部分
生成人工智能(Genai)是人工智能(AI)最具变革性的分支之一。是指基于从现有数据中学到的模式,可以创建新内容,例如文本,图像,音乐甚至代码。与主要旨在识别模式并做出预测的传统AI系统不同,生成的AI模型可以生成类似于培训的输入数据的新型输出。使用一些更熟悉的生成AI工具用于:生成文本(OpenAi的GPT-4);发声(Openai Jukebox),DeepMind的Wavenet;图像生成(Openai的DALL-E);时间序列生成(Amazon Web服务的TimeGan),视频生成(Sora - OpenAI的文本对视频模型);和代码生成(Openai和Github,OpenAI Codex的GitHub Copilot)。