XiaoMi-AI文件搜索系统
World File Search System声音

芝加哥拉丁语关于环境和气候变化种族主义的声音
我们使用了一种混合方法,包括视力民族志,参与者观察和人群调查来获取数据。共有7个研究课程,每个研究大约需要90分钟才能完成人口调查,并用书面描述性故事创建他们的个人地图/艺术品。人口统计调查用于了解关键变量之间的关系,以揭示模式和相关性。所考虑的变量是:参与者的年龄,住所(在芝加哥,牺牲区/近乎牺牲区或芝加哥外郊区),出生于美国或移民(见图1)。我们收集了63套个人地图/艺术品和拉丁参与者的书面故事。在63名参与者中,有45位居住在芝加哥(牺牲区或附近的28个),在郊区18个,如图2所示。

Farzan的声音v。 Cleary PassFarzan的声音v。 Cleary Pass
2在法尔尚在重新考虑的动议中提出的一定程度,即地方法院在持续此事的情况下犯了错误,直到我们对法尔尚的相关行动的裁决,Farzan诉J.P. J.P. Morgan Chase Bank,N.A.,No./div>19-3925,2022 WL 17336211,at *2(3d cir。2022年11月30日),我们在法院的隐含决定中没有识别任何错误,不要重新考虑该裁决。参见Texaco,Inc。诉Borda,383 F.2d 607,608–09(3d Cir。1967)。3上诉人提出单独答复摘要的动议。

视觉变压器分割的视觉鸟声音denoising
音频denoising,尤其是在鸟类声音的背景下,由于持续的残留噪声,这仍然是一项具有挑战性的任务。传统和深度学习方法通常在人工或低频噪声中挣扎。在这项工作中,我们提出了VITV,这是一种新型的方法,利用了视觉变形(VIT)架构的力量。vitvs熟练地结合了分段技术,从而将清洁音频与复杂的信号混合物中解脱出来。我们的主要贡献涵盖了VITV的发展,引入了全面,远程和多规模的表示。这些贡献直接解决了常规方法固有的局限性。广泛的例子表明,VITV的表现要优于最先进的方法,将其定位为现实世界中鸟类声音降解应用的基准解决方案。源代码可用:https://github.com/aiai-4/vivts。索引术语:音频denoising,变压器,分段

rw-voiceshield:基于原始波形的对抗性攻击一声音conversion
近年来,单发语音转换(VC)取得了重大进步,使能够用一个句子改变说话者特征。但是,随着该技术的成熟并产生了越来越现实的说法,它很容易受到隐私问题的影响。在本文中,我们提出了RW-Voiceshield,以保护声音免于复制。这是通过通过使用基于原始波形的生成模型产生的不可察觉的噪声来有效攻击单发VC模型来实现的。使用最新的单发VC模型进行测试,我们进行了测试,在黑盒和白色盒子方案下进行主观和客观评估。我们的结果表明,VC模型产生的话语与受保护的说话者的话语之间的说话者特征存在显着差异。此外,即使在受保护的话语中引入了对抗性噪声,说话者的独特特征仍然可以识别。索引术语:语音转换,对抗性攻击,扬声器verification,扬声器表示

主动重新配置的分段空间声音调制器
高质量的声音 - 全外模式和图像,与3D显示器,声学和中间触觉等应用不可或缺的一部分需要精确的超声波分布以实现。此任务的基本工具是空间声音调节器(SSM),它控制组成元素以实现声音压力的动态分布。但是,由于高成本和许多小,紧密的单位,当前的超声SSM面临局限性。这项研究介绍了“分割的SSM”,即新型设备,这些设备将传统的声学跨表面像素单元组合到定制形状的分段元件中。这些分段的SSM降低了驱动成本和复杂性,同时保持压力分配质量。此方法包括一种自定义的相凝集算法(PAA),该算法是为用户选择的潜在分割解决方案的层次结构。使用OB-3D打印机和定制控制电子设备详细介绍了SSM制造方法,从概念到实现,完成了端到端方法。使用两个原型SSM设备验证了这种方法,它们使用动态分段元件将声波聚焦并悬浮聚苯乙烯珠。通过具有静态和动态元素的混合SSM设备探索了对技术的进一步增强。管道促进了各种应用程序跨不同应用的有效SSM构建,并邀请了以不同尺寸,用途和驱动机制的未来设备的成立。


随着时代而移动的声音。
·通过USB音频提供的空间音频与HI-RES支撑24位96 kHz·Earsense™赔偿量的薪酬为适合您的合身的经验在设备之间平稳切换·自动打开和关闭·智能音频和呼叫路由·自动播放和暂停·直观控制的触觉拨号·应用程序中可自定义的控件
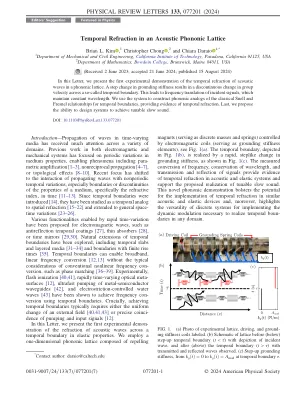
声音晶格中的时间折射
简介 - 随着时变媒体的传播在各种领域都引起了很多关注。电磁系统和机械系统的先前工作都集中在培养基中的周期性变化上,从而使现象包括副局部扩增[1-3],非互联性传播[4-7]或拓扑作用[8-10]。最近的焦点已转移到传播波与非周期性变化的相互作用,尤其是培养基特性的边界或不连续性,尤其是折射率,尤其是折射率[11-13]。由于引入了时间边界[14],因此已将它们作为空间折射的时间类似物研究[15-22],并扩展到一般的时空变化[23-26]。已经提出了通过快速的时间变化来实现电磁波的各种功能,例如抗反射颞涂层[27],薄吸收器[28]或时射镜[29,30]。已经探索了时间边界的自然扩展,包括时间板和分层介质[31 - 34]和有限上升时间的边界[35]。时间边界可以启用宽带,线性频率转换[12,13],而无需典型的考虑常规非线性频率con版本,例如相位匹配[36 - 39]。在实验上,闪光电离[40,41],迅速变化的光学元表面[12],金属 - 官方导体波导的超快泵送[42]和电纵向控制的水波[43] [43]已显示出使用颞界实现频率的频率。我们采用由排斥>组成的一维声音晶格至关重要的是,达到时间边界通常需要外部田地的均匀变化[40,41,43]或泵送和输入信号的精确重合[12]。在这封信中,我们介绍了弹性特性中的声波折射的第一个实验示例。

卓越冲刺 - 技术领导者的声音
网络安全预计将是重中之重。该调查强调了对组织和跨部门的网络安全措施的上升,因为它们将敏感数据存储在云中并使用互连系统。消费行业是优先考虑网络安全投资的领导者,其中31%的受访者优先考虑这一领域。er&i和LSHC是其他两个行业,其中21%的受访者更喜欢为网络安全分配大量资源。虽然FS和TMT部门继续在网络安全上花费,但考虑到这些部门目睹的监管任务和持续数字化,我们的调查表明,其他部门也在赶上数字化转型,并优先考虑安全投资以保持其企业的驻留。

探索噪声和降解对心脏声音分类模型的影响
近年来,数据驱动的心脏声音分类模型的发展一直是研究的活跃领域。首先要开发此类数据驱动的模型,需要使用信号采集设备捕获心脏声音信号。但是,由于大多数情况下存在内部和外部噪音,几乎不可能捕获无噪声的心声信号。心脏声音信号中的这种噪声和降解可能会降低数据驱动分类模型的准确性。尽管文献中已经提出了不同的技术来解决噪声问题,但心声信号中的噪声和降解在何种程度上影响了数据驱动的分类模型的准确性,但仍未得到探索。为了回答这个问题,我们制作了一个合成心脏声音数据集,包括正常和异常的心脏声音,这些声音被各种噪音和降解污染。我们使用此数据集研究了心脏声音记录中噪声和降解对不同分类模型的性能的影响。结果显示出不同的噪声和降解在不同程度上影响心脏声音分类模型的性能。有些对于分类模型更有问题,而另一些则不那么破坏性。将这项研究的发现与我们先前与一组临床医生进行的调查的结果进行比较,表明对分类模型更有害的噪声和降解也更具破坏性对准确的听诊。这项研究的发现可以利用以发展有针对性的心脏声音质量增强方法 - 根据心脏声音信号中噪声和降解的特征,可以适应质量增强的类型和侵略性。