XiaoMi-AI文件搜索系统
World File Search System字典

利用 SAT 技术构造最小完美哈希函数
最小完美哈希函数 (MPHF) 用于有效访问大型字典 (键值对集) 的值。发现构建 MPHF 的新算法是一个活跃的研究领域,尤其是从存储效率的角度来看。MPHF 的信息论极限为 1 ln 2 ≈ 1.44 位/键。当前最佳实用算法的范围是每个键 2 到 4 位。在本文中,我们提出了两种基于 SAT 的 MPHF 构造。我们的第一个构造产生的 MPHF 接近信息论极限。对于这种构造,当前最先进的 SAT 求解器可以处理字典包含多达 40 个元素的情况,从而优于现有的 (蛮力) 方法。我们的第二个构造使用 XOR-SAT 过滤器来实现一种实用方法,每个键的长期存储量约为 1.83 位。

一种用于跨领域脑电情绪分类的领域自适应稀疏表示分类器
脑机接口(BCI)解读人脑在意识活动过程中的生理信息,建立大脑与外界之间的直接信息传输通道。脑电图(EEG)作为最常见的非侵入式BCI模式,在BCI的情绪识别中起着重要作用;然而,由于EEG信号的个体差异性和非平稳性,针对不同受试者、不同会话和不同设备构建基于EEG的情绪分类器是一个重要的研究方向。领域自适应利用来自多个领域的数据或知识,专注于将知识从源域(SD)转移到目标域(TD),其中EEG数据可能来自不同的受试者、会话或设备。在本研究中,提出了一种新的领域自适应稀疏表示分类器(DASRC)来解决基于EEG的跨域情绪分类问题。为了减少域分布的差异,利用局部信息保留标准将来自SD和TD的样本投影到共享子空间中。在投影子空间中学习一个通用的领域不变字典,从而在 SD 和 TD 之间建立内在联系。此外,还利用主成分分析 (PCA) 和 Fisher 标准来提升学习字典的识别能力。此外,还提出了一种优化方法来交替更新子空间和字典学习。CSFDDL 的比较表明,该方法对于跨受试者和跨数据集的基于 EEG 的情绪分类问题具有可行性和竞争性性能。

最短公共超弦的量子算法......
在本文中,我们考虑了文本组装问题的两个版本。给定一个总长度为 L 的字符串序列 s 1 , . . . , sn ,它是一个字典,以及一个长度为 m 的字符串 t ,它是一个文本。第一个版本的问题是从字典中组装 t。第二个版本是“最短超弦问题”(SSP)或“最短公共超弦问题”(SCS)。在这种情况下,t 是未知的,我们应该构造一个最短的字符串(我们称之为超弦),其中包含给定序列中的每个字符串作为子字符串。这些问题与从小片段重建长 DNA 序列的序列组装方法有关。对于这两个问题,我们提出了比经典算法更好的新量子算法。在第一种情况下,我们提出了一种量子算法,其复杂度为 O ( m +log m √


增援令牌 |卡斯蒂利亚语
1 名义团体。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 3 2 外邦人。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 4 3 尖音词、平音词和近音词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 5 4 所有格。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 6 5 谚语。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 7 6 尖锐的言辞。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 8 7 指示词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 9 8 前缀。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 10 9 简单的话。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 11 10 数字。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 12 11 不确定的。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 13 12 后缀。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 14 13 副词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 15 14 动词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 16 15 字典中的名词和形容词。 。 。 。 。 。 。 17 16 以 v 结尾的形容词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 18 17 动词的数和人称。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 19 18 前缀in-、des-。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 20 19 以 -ger 和 -gir 结尾的动词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 21 20 动词时态。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 22 21 前缀 sub- 和 inter- 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 23 22 动词中的 y。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 24 23 第一个动词变位。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 25 24 后缀-ista 和-dor。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 26 25 动词中的 b。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 27 26 第二种变位。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 28 27 后缀-oso。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 29 28 动词中的 v。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 30 29 第三变位。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。字典中的 31 30 个动词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 32 31 以 -bir 结尾的动词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 33 32 复合时态。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 34 33 语义场。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。三十五


基于脑肿瘤MRI图像识别的监督多层词典学习
人工智能(AI)是自动脑肿瘤MRI图像识别的有效技术。AI模型的培训需要大量标记的数据,但是医疗数据需要由专业临床医生标记,这使数据收集变得复杂且昂贵。传统的AI模型要求训练数据和测试数据必须遵循独立且分布相同的分布。为了解决这个问题,我们在本文中提出了一个基于监督多层词典学习(TSMDL)的转移模型。借助从相关领域学到的知识,该模型的目标是解决转移学习的任务,而目标域只有少数标记的样本。基于多层词典学习的框架,所提出的模型了解了每一层中的源和目标域的共享词典,以探索不同域之间的内在连接和共享信息。同时,通过充分利用样品的标签信息,引入了Laplacian正则化项,以使类似样本的字典编码尽可能接近,并尽可能地对不同类样本的字典编码进行编码。大脑MRI图像数据集Rembrandt和Figshare上的识别实验表明,该模型的性能优于竞争状态。

用于测试 Open Quantum Safe for TLS 服务器的框架
FUNCTION start_multiprocessing(number_of_processes, worker_function, return_processing_function, *additional_arguments) # 创建用于进程通信的共享数据结构 shared_dictionary <- create_shared_dictionary() process_list = [] FOR i <- 0 TO number_of_processes - 1 process <- create_process(worker_function, (i, shared_dictionary, number_of_processes, return_dictionary, additional_arguments)) process_list.append(process) start_process(process) ENDFOR # 等待所有进程完成 FOR process IN process_list wait_for_process_completion(process) ENDFOR # 处理共享字典中的结果 result <- return_processing_function(shared_dictionary) RETURN result ENDFUNCTION
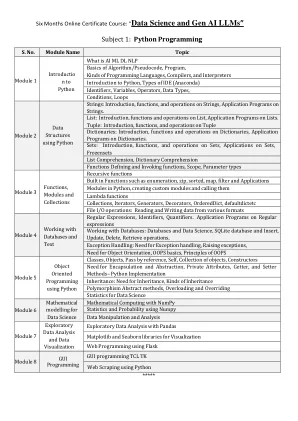
主题1:Python编程
字符串:在字符串上的引言,功能和操作,在字符串上的应用程序。列表:列表上的简介,功能和操作,列表上的应用程序。元组:元组词典上的简介,功能和操作:词典上的简介,函数和操作,词典上的应用程序。集合:集合的简介,功能和操作,集合上的应用程序,frozensets列表理解,字典理解函数定义和调用功能,范围,参数类型

基于脑电图的脑机接口系统控制假肢手指运动
研究 脑信号 手指数量 信号处理链 准确度(%) [11] EEG 4 CWD&2LCF 43.5 [12] EEG 5 RF&LDA&SVM&KNN 54 [13] EEG 5 LSTM&CNN&RCNN 77 [14] EEG 5 PCA&PSD&SVM 77 [15] MEG 5 SVM 83 [16] MEG 5 BPF&频谱图&SVM 57 [17] ECOG 5 CNN&RNN&LSTM 49 [18] ECoG 4 BPF&Morlet小波字典&STMC 85 [19] ECoG 5 CSP&SVM 86.30 [20] fNIRS 2 SVM 62.05 [21] EMG 1小波&自回归&SVM 76