XiaoMi-AI文件搜索系统
World File Search System字母表

基于量子弦比较器的某些弦问题的量子算法
用于搜索的算法在 [29] 中进行了描述。利用这种思想,我们获得了几个问题的量子算法。第一个问题是字符串排序问题。假设我们有 n 个长度为 k 的字符串。众所周知 [30],没有量子算法可以比 O(nlogn) 更快地对任意可比较对象进行排序。同时,一些研究人员试图改进隐藏常数 [31,32]。其他研究人员研究了空间有界的情况 [33]。我们专注于对字符串进行排序。在经典情况下,我们可以使用一种比任意可比较对象排序算法更好的算法。对于有限大小的字母表,基数排序具有 O(nk) 查询复杂度 [34]。它也是经典(随机或确定性)算法的下限,即 Ω(nk)。我们的字符串排序问题的量子算法的查询复杂度为 O(n(logn)·√


增强型飞行终止系统研究第一阶段
特别报告附录(分布 D)中包含以下附录:附录 II-E – 方法 #1:双相频移键控方法附录 II-F – 方法 #2:双相电平 PCM/FM 技术 (CPFSK)附录 II-G – 方法 #3:增强高字母表附录 II-H – 方法 #4:增强安全 FTS 技术附录 II-I – 方法 #5:非相干 3/13 音调消息附录 II-J – 方法 #6:伪随机码技术附录 II-K – 方法 #7:可扩展 3-DES 加密 BPSK 技术附录 III-F – EFTS 范围调查报告附录 III-G – 调制格式选择比较分析附录 III-H – 消息格式和协议操作影响分析附录 IV-G – 应用于 EFTS 的范围操作场景/程序附录 IV-H – 机载飞行终止系统调查报告

增强型飞行终止系统研究第一阶段
在特别报告补编(分布 D)中可以找到以下附录: 附录 II-E – 方法 #1:双相频移键控方法 附录 II-F – 方法 #2:双相电平 PCM/FM 技术(CPFSK) 附录 II-G – 方法 #3:增强型高字母表 附录 II-H – 方法 #4:增强型安全 FTS 技术 附录 II-I – 方法 #5:非相干 3/13 音调消息 附录 II-J – 方法 #6:伪随机码技术 附录 II-K – 方法 #7:可扩展 3-DES 加密 BPSK 技术 附录 III-F – EFTS 范围调查报告 附录 III-G – 调制格式选择比较分析 附录 III-H – 消息格式和协议操作影响分析 附录 IV-G – 应用于 EFTS 的范围操作场景/程序 附录 IV-H – 机载飞行终止系统调查报告

通用综合征解码问题的经典和量子算法以及对李度量的应用
摘要。基于代码的密码学的安全性通常依赖于汉明权重的综合征解码 (SD) 问题的难度。最好的通用算法都是 Prange 旧算法的改进,它们被称为信息集解码 (ISD) 算法。这项工作旨在通过改变 SD 的底层权重函数和字母表大小来扩展 ISD 算法的范围。更准确地说,我们展示了如何在 ISD 框架中使用 Wagner 算法来解决各种权重函数的 SD。我们还计算了 ISD 算法的渐近复杂度,包括经典和量子情况。然后,我们将结果应用于目前备受关注的李度量。通过提供解码似乎最难的李权重的 SD 参数,我们的研究可以有多种应用,用于设计基于代码的密码系统及其安全性分析,尤其是针对量子对手。
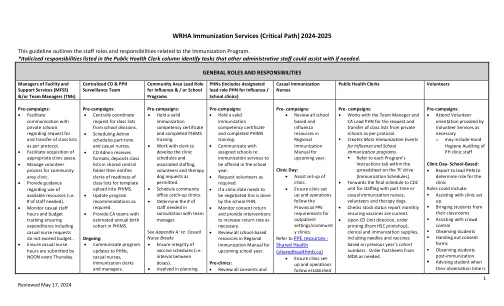
WRHA免疫服务(关键路径)2024-2025
基于学校的:• *当CD单元通知时,从共享中央文件夹中访问类列表,将列表上传到PHIMS,管理拒绝的文件并更新质量免疫事件。•管理基于学校计划的学生转移 / out流程。临床前(基于学校和流感):▪安排交货和接送同意。▪字母表同意书,按教室组织,并由Yes and No分开。▪确认与PHN发生的事件所需的疫苗。▪更新大规模免疫事件(疫苗批次#'S&Sufts)。▪与PHN合作准备和包装包括疫苗在内的免疫诊所供应。▪根据WRHA政策,根据需要使用快递服务将供应往返诊所。▪在每个诊所前一周一周的学校领先PHN或PHC-以确保分配免疫提醒笔记

国际分子科学杂志
蛋白质是 DNA 复杂解码的产物,是遗传信息的终极体现。在细胞的繁忙范围内,这些分子主力承担着多方面的角色。它们多功能性的核心在于由四个字母的 DNA 字母表编写的极其优雅的代码。这种由氨基酸序列组成的代码决定了蛋白质的折叠和排列,形成令人眼花缭乱的结构阵列,每个结构都经过量身定制以实现特定功能。从为组织提供结构支撑的坚固胶原纤维到为细胞运动提供动力的灵活分子马达,蛋白质体现了基因组中编码的惊人多样性。本期特刊旨在汇集描述研究蛋白质结构科学进展的作品,包括酶、结构蛋白、膜和所有生物体。它也开放涉及四个结构层面的生物信息学和研究方法、这些物理层面之间的相互作用以及不同的免疫和抗原疫苗方面以及药物开发的工作。

使用近似误差校正接近量子单例界限
众所周知,没有任何速率为 푅 的量子纠错码能够纠正超过 ( 1 − 푅 )/ 4 部分符号的对抗性错误。但是,如果我们只要求我们的代码能够大致恢复消息呢?在这项工作中,我们针对接近量子单例界限 ( 1 − 푅 )/ 2 的对抗性错误率构建了可有效解码的近似量子码,对于任何恒定速率 푅 。具体来说,对于每个 푅 ∈( 0 , 1 ) 和 훾 > 0,我们构造速率为 푅 、消息长度为 푘 和字母表大小为 2 푂 ( 1 / 훾 5 ) 的代码,这些代码可以有效地解码 ( 1 − 푅 − 훾 )/ 2 分数的对抗性错误,并恢复高达反指数误差 2 − Ω ( 푘 ) 的消息。在技术层面,我们使用经典的鲁棒秘密共享和量子纯度测试将近似量子误差校正减少到合适的量子列表解码概念。然后,我们通过 (i) 引入折叠量子 Reed-Solomon 码和 (ii) 应用新的量子版本距离放大来实例化我们的量子列表解码概念。

自动文本识别
自动文本识别是一个困难但重要的问题。它可以概括为:如何使计算机能够识别预定义字母表中的字母和数字,可能使用上下文信息。已经进行了各种尝试来解决这个问题,使用不同的特征和分类器选择。自动文本识别系统在准确性方面已经达到了人类的表现,并且在单一大小、单一字体、高质量、已知布局、已知背景、文本的情况下,速度超过了人类的表现。当上述一个或多个参数发生变化时,问题变得越来越困难。特别是,尽管近四十年来不断进行研究,但要达到人类在识别不同大小、不同风格、未知布局、未知背景的草书方面的表现,远远超出了当今算法的范围。在本报告中,我们详细分析了该问题,介绍了相关困难,并提出了一个解决自动文本识别问题的连贯框架。

澳大利亚免疫登记册(AIR)COVID-19疫苗用户指南(医院)中心
An encounter can be recorded from either of the below screens: Identify Individual (Individual not found) Identify Individual (existing AIR record found) Select the Record Encounter option and record the following information in the New Encounter fields: Who performed the encounter : Select ‘ I performed this encounter ' This was performed at a School : Disregard this field Schedule: Disregard this field Date of service: Enter date vaccination given using free text or calendar function Date of service applied for all episodes:忽略此现场疫苗/品牌:从字母表的下拉菜单中选择疫苗或开始键入并让网站自动访问疫苗名称批号:输入疫苗批次序列号序列号:输入疫苗序列号:一旦您输入了所有信息,请选择“添加到下一步”或“取消下一步”或“取消”输出以放弃该条目。提示:屏幕上以红色星号( *)标记的字段表示强制性信息。如果丢失了此信息,您将无法记录相遇。