XiaoMi-AI文件搜索系统
World File Search System实例

一种新颖性检测分类方法
新颖性检测技术是一种概念学习方法,其通过识别概念的正实例而不是区分其正实例和负实例来进行。因此,新颖性检测方法需要很少的负训练实例(如果有的话)。本文介绍了一种特殊的新颖性检测分类方法,该方法使用基于 [Gluck & Myers,1993] 海马模型的冗余压缩和非冗余区分技术,海马是大脑中与学习和记忆密切相关的部分。具体而言,这种方法包括训练自动编码器在输出层重建正输入实例,然后使用该自动编码器识别新颖的实例。训练后可以进行分类,因为预计正实例将被准确重建,而负实例则不能。本文的目的是将实现该技术的系统 HIPPO 与 C4.5 和前馈神经网络分类在几个应用上进行比较。

使用实例和实体中心分割损失函数
在本文中,我们提出了一种新型的两组分损失,用于生物医学图像分割任务,称为实例和实例中心(ICI)损失,这是一种损失函数,在使用像素损失功能(例如骰子损失)时,通常会遇到实例不平衡问题。实例组件改善了具有大型和小实例的图像数据集中的小实例或“斑点”的检测。实体中心组件提高了整体检测准确性。我们使用ATLAS R2.0挑战数据集的Miccai 2022。与其他损失相比,ICI损失提供了更好的平衡分段,并以改进1的改善而显着超过了骰子损失。7-3。7%,斑点损失为0。6-5。0%的骰子相似性系数在验证和测试集中,这表明ICI损失是实例不平衡问题的潜在解决方案。关键字:实例和实体中心细分损失,细分损失。

夸克:量子应用重构内核
一般来说,首先要实现一个实例,即问题定义参数的容器,如图 2 中的单元格 2 所示。从该实例构建 ConstrainedObjective,它是一个处理实例数据以获取目标函数和约束集合的工厂,参见单元格 3。然后可以将后者自动转换为相应的惩罚目标项,这些惩罚目标项与实际目标函数一起包含在 ObjectiveTerms 中。目标项的加权和形成 Objective,即最终的 Ising/QUBO 问题。上述步骤均在单元格 5 中执行,从使用单元格 4 中定义的参数实例化具体实例开始。

算法配置问题-LIX
•π:由A(电支)无限的实例组成的决策/优化问题。每个实例是问题的输入字符串;在实例数据可用的许多编码中,最常见的是离散/连续值的向量,其中包含实例的最重要属性。在以下内容中,我们假设可以有效地将几个编码彼此转移(即,没有太多信息丢失),我们将π称为编码实例集。 •C A:A的参数配置集,即不同类型的数据数组(布尔,数字,分类),通常由continusus和/或离散/分类值的向量编码。并非所有可能的参数值都可以接受,这是由于有关多个参数的逻辑条件。因此,为简单起见,我们假设C A仅包含可行的算法配置; •A:

Joseph博士早期Joseph博士早期
·通过多个实例学习国际学习表征会议(ICLR)固有可解释的时间序列分类(2024。·扩展场景到斑点模型:多分辨率的地球观察环境数据科学的多个实例学习(期刊),2023。·一种基于风险的AI监管方法:系统分类和可解释的AI实践脚本:法律,技术与社会杂志,2023年。·通过可解释的多个实例学习神经信息处理系统(Neurips)的轨迹标签的非马尔可奖奖励建模,2022。·用于多个实例学习国际学习表征的不可解释性(ICLR),2022。·场景到点地球观察:通过机器学习(Neurips Workshop)来应对气候变化的多个实例学习,2022年。

分级品质
1在整个论文中,我们都以“质量”为中立的术语来谈论什么实体。特定的本体论概念(例如属性,trope,set或Fusion)在我们将在本文中提出的针对性分级质量的形而上学说明中使用。2请注意,罗素等同于具有中等学位的质量等同于它的确定相关对象是否具有质量。我们认为这是需要进一步论据的实质性假设。第3节中引起的形而上学评分的三种理论在这一点上是中性的。3 Lewis(1986),p。 53。 请注意,在引用的注释中,刘易斯针对属性的相对实例化,而不是实例化等级。 他确实在引用备注后立即提到了“接受学位的属性”,但是从上下文中可以明显看出,他所说的是具有“内部度结构”的属性,例如质量,而不是可以在中等程度上实例化的属性。 当然,这并不会破坏他的引用索赔规定的观点,即有某些属性是在一定程度上实例化的。3 Lewis(1986),p。 53。请注意,在引用的注释中,刘易斯针对属性的相对实例化,而不是实例化等级。他确实在引用备注后立即提到了“接受学位的属性”,但是从上下文中可以明显看出,他所说的是具有“内部度结构”的属性,例如质量,而不是可以在中等程度上实例化的属性。当然,这并不会破坏他的引用索赔规定的观点,即有某些属性是在一定程度上实例化的。

一种解决人工智能规划难题的新型自动化课程策略
主算法(算法 1)首先从我们需要解决的目标 6 实例(算法 2)创建一个子实例任务池,并可能从其他未解决的实例中创建子实例以进一步提高性能(选项 MIX)。通常,任务池包含 100,000 个任务或子实例。8 在每次迭代中,采样器/老虎机从池中挑选一批任务子实例并将其传递给 9 RL 代理。一批通常有 500 个任务或子实例(算法 3)。10 基于蒙特卡洛树搜索(算法 4)的 RL 代理,借助神经网络(CNN 或 11 GNN)进行增强,尝试解决这些实例。对于批次中的每个实例,MCTS 都会在给定的资源预算下寻找一个解决方案,对于生成的每个成功解决方案,MCTS 还会为策略/价值深度网络(训练器)生成一系列新的训练数据,以进一步更新其网络参数。每个实例的 MCTS 成功/失败状态都会发送回采样器/老虎机以调整其权重。每次成功的尝试不仅会生成一个有效的解决方案,还会为训练器改进策略/价值数据,以训练代理的深度网络。训练器会保留一个大小为 100000 的池子,用于存储 MCTS 生成的最新训练数据,并训练网络。每个训练批次都会均匀随机抽样。所有实验均在配备 2x18 19 核 Xeon Skylake 6154 CPU 和 5 个 Nvidia Tesla V100 16GB GPU 的机器上完成,所有训练组件均使用学习率为 0 的 Adam。 002作为默认优化器。MCTS模拟次数R设置为1600,Exp3每次迭代采样的batch size M设置为500。

大脑限制的深度神经网络研究
语言影响认知和概念处理,但这种因果效应在人脑中实现的机制仍然未知。在这里,我们使用一个受大脑约束的类别形成和符号学习的深度神经网络模型,并在神经回路层面分析新兴模型的内部机制。在一组模拟中,向网络展示了类似的神经活动模式,这些模式对属于同一类别的对象和动作实例进行索引。生物学上真实的赫布学习导致形成分布在网络多个区域的实例特定神经元,此外,还形成响应所有类别实例的“共享”神经元的细胞组装回路——网络与概念类别相关。在两组独立的模拟中,网络学习了相同的模式以及单个实例的符号[“专有名称” (PN)]或与具有共同特征的实例类别相关的符号[“类别术语” (CT)]。学习专有名词显著增加了网络中共享神经元的数量,从而使类别表征更加稳健,同时减少了特定实例神经元的数量。相反,专有名词学习可以防止特定实例神经元的大幅减少,并阻止类别一般神经元的过度生长。表征相似性分析进一步证实,与使用 PN 和不使用任何符号的学习相比,类别术语学习后类别实例的神经活动模式变得更加相似。实验研究表明,这些基于网络的概念、PN 和专有名词机制解释了符号学习为何以及如何改变物体感知和记忆。
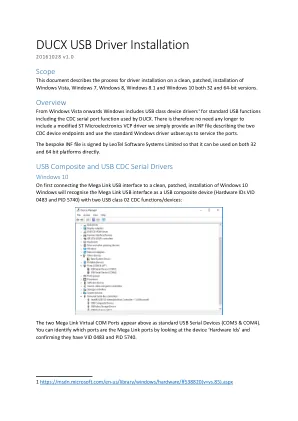
ducx USB驱动程序安装
方案#2首先将MEGA链接USB接口连接到干净,修补的Windows 8.1安装,Internet访问和设置以自动下载和安装Windows的驱动程序将识别Mega Link USB接口为单个“ stmicroelectronics virtualics virtual com port'实例'实例'实例(硬件ID ID vid 0483和PID 5740)。

CPT代码的先验验证更改
81513感染性疾病,细菌性阴道病,RNA标记的定量实时扩增对肥大的阴道,阴道gardnerella and gardnerella and ractobacillus物种,使用阴道流体标本,算法,算法是使用算法的,用于使用量子或阴性阴道的阳性或阴性阴道的阳性或负面的阴道症状,并实例性地实例性地实例性地实例性地实例化, DNA阴道,阴道上的DNA标志物,1型巨大阴道,细菌性阴道病相关细菌-2(BVAB-2)和乳酸菌种类(L. crispatus和L. jensenii)(L. crispatus and L. jensenii),用于使用阴道的较高的阴道,较高的阳性,质量为Ataginimenty,质量为Ataginimenty,质量较高的阳性,报道说,阴道和/或念珠菌物种(C. blopicalis,C。tropicalis,C。parapasilosis,C。dubliniensis),Candidaglabrata,Candida krusei。