XiaoMi-AI文件搜索系统
World File Search System峰值噪声

Neuroxplorer的性能特征,下一代人脑PET/CT成像器
耶鲁大学,加利福尼亚大学,戴维斯大学和联合成像医疗保健的合作成功地开发了神经脱落者,这是一家专门的人脑宠物成像仪,具有高空间分辨率,高灵敏度和内置的3维相机,用于无标记的无效运动跟踪。它具有较高的相互作用和交流时间的分辨率,以及52.4厘米的横向视野(FOV)和扩展的轴向FOV(49.5厘米),以增强灵敏度。在这里,我们介绍了神经解释器的身体表征,性能评估和第一个人类图像。方法:对空间分辨率,灵敏度,计数率性能,能量和时序的测量以及图像质量进行了遵守国家电子制造商协会(NEMA)NU 2-2018标准。通过对Hoffman 3维脑幻影和迷你Derenzo phanmom的成像研究来证明该系统的性能。提出了来自健康志愿者的最初18个F-FDG图像。结果:通过过滤后的反射重建,径向和tan量的空间分辨率(最大宽度为一半)平均为1.64、2.06和2.51mm,轴向分辨率为2.73、2.89,2.89和2.93 mm的径向偏移量为1、10和20cm,相应的距离。平均交流分辨率为236 PS,能量分辨率为10.5%。NEMA敏感性分别为46.0和47.6 kCPS/MBQ,分别为10 cm偏移。在FOV中心达到了11.8%的敏感性。在58.0 kBQ/mL时,峰值噪声等效率为1.31 mcps,在5.3 kbq/mL时的散射分数为36.5%。峰值噪声当量计数率在峰值等效率下的最大计数率少于5%。在3次迭代时,NEMA图像质量对比度恢复系数从74.5%(10毫米球)到92.6%(37毫米球)不等,背景可变性在4.0:1的对比度为3.1%至1.4%。一个例子人脑18 F-FDG图像表现出很高的分辨率,在皮质和皮层结构中捕获了复杂的细节。结论:神经塑料提供了高灵敏度和高空间分辨率。具有长的轴向长度,它还可以实现高质量的脊髓成像和颈动脉的图像衍生的输入功能。这些绩效增强能力将大大扩大人脑宠物范式,方案的范围,从而扩大临床研究应用。
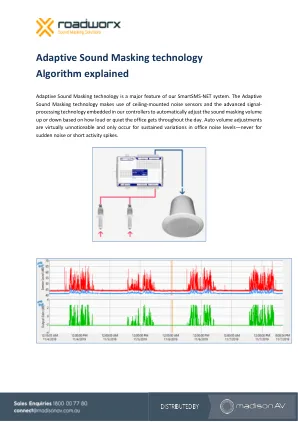
自适应声音掩蔽技术算法解释
在幕后,自适应声音掩蔽系统算法非常复杂。它提供了很大的灵活性,可以避免“动态”声音掩蔽系统的许多潜在缺陷。无反馈、自平衡系统:自适应声音掩蔽技术每 15 秒进行一次调整。该算法将测量该期间的峰值噪声水平 (L10%),并将其与背景噪声水平 (L95%) 进行比较。当这两个值之间的差距很小时,这意味着空间很安静,算法将默认使用 0.5 dB 的步长略微降低增益。当峰值和背景之间的差距增加时,这意味着空间中的活动更多,因此系统将略微增加声音掩蔽增益。几分钟后,这将倾向于增加由自然背景(活动 + 通风)和声音掩蔽组成的整体背景噪声水平。背景噪声水平 (L95%) 的增加将因此减少峰值和背景之间的差距,并且掩蔽噪声增加将停止。结果是系统不会自我反馈,在任何条件下都能自我平衡。对背景水平变化做出适当反应:适当的声音掩蔽系统应该对语音噪音做出反应,但当建筑物中的自然背景噪音水平增加时(通风增加、交通噪音增加),不应增加。为了实现这一目标,自适应声音掩蔽系统有一个“语音过滤器”,一个 200 到 3000Hz 之间的带通滤波器,用于关注人声。