XiaoMi-AI文件搜索系统
World File Search System并行性

通过粗粒分量并发提高地球系统模型的可伸缩性 - 与图标v2.6.5建模系统的案例研究
摘要。在Exascale计算时代,具有前所未有的计算能力的机器可用。使这些大规模平行的机器有效地使用了数百万个核心,提出了一个新的挑战。需要多级和多维并行性来满足这种挑战。粗粒分量并发性提供了一个差异的并行性维度,该维度通常使用了通常使用的并行化方法,例如域分解和循环级别的共享内存方法。虽然这些主教化方法是数据并行技术,并且它们分解了数据空间,但组件并发是一种函数并行技术,并且分解了算法MIC空间。并行性的额外维度使我们能够将可扩展性扩展到由已建立的并行化技术设置的限制之外。,当通过添加组件(例如生物地球化学或冰盖模型)增加模型复杂性时,它还提供了一种方法来提高性能(通过使用更多的计算功率)。此外,货币允许每个组件在不同的硬件上运行,从而利用异质硬件配置的使用。在这项工作中,我们研究了组件并发的特征,并在一般文本中分析其行为。分析表明,组件并发构成“并行工作负载”,从而在某些条件下提高了可扩展性。这些通用考虑是

本文全面分析了分布的高性能计算方法,以加速深度学习培训。我们探索进化o
本文全面分析了分布的高性能计算方法,以加速深度学习培训。我们探讨了分布式计算体系结构的演变,包括数据并行性,模型并行性和管道并行性及其混合实现。该研究深入研究了对大规模训练至关重要的优化技术,例如分布式优化算法,梯度压缩和自适应学习率方法。我们研究了沟通效率高的算法,包括戒指所有减少变体和分散培训方法,这些方法应对分布式系统的可伸缩性挑战。研究研究了硬件加速度和专业系统,重点是GPU群集,自定义AI加速器,高性能互连以及针对深度学习工作负载的优化的分布式存储系统。最后,我们讨论了该领域的挑战和未来方向,包括可伸缩性效率折衷,容错性,大规模培训中的能源效率以及新兴趋势等新兴趋势,例如联合学习和神经形态计算。我们的发现突出了高级算法,专业硬件和优化的系统设计之间的协同作用,以突破大规模深度学习的边界,为未来的人工智能突破铺平了道路。关键字:分布式计算,深度学习加速,高性能系统,通信 -

一个基于晶格的高效晶格后加密处理器,用于物联网应用
•基于定制的晶格PQC处理器,用于效率,硬件资源和灵活性•使用SIMD并行性进行效率计算•具有双标志路径的效率存储器访问•通过精细粒度重复资源的灵活性

在自定义RISC-V ASIPS上嵌入机器学习的挑战
Solution: End-to-End TinyML Deployment and Benchmarking Flow • [MLIF] (Machine Learning Interface) • Framework/target-independent abstraction layers for Target SW • [MLonMCU] • Provides support for • 15+ targets (mainly RISC-V simulators) • 6 backends ([TVM] and TFLM) • Handling of Dependencies • Analysis and Exploration methods • Designed with并行性/可重复性

ML云GPU短缺培训:跨区域是答案吗?水管工
摄入和转换输入数据的b缩合输入管道是训练机学习(ML)模型的重要组成部分。然而,实施有效的输入管道是一项挑战,因为它需要有关并行性,异步和可变性信息的可变性的推理。我们对Google数据中心中超过200万ML职位的分析表明,大量的模型培训工作可能会从更快的输入数据管道中受益。同时,我们的分析表明,大多数作业都不饱和主机硬件,指向基于软件的瓶颈的方向。是由这些发现的动机,我们提出了水管工,这是一种在ML输入管道中找到瓶颈的工具。水管工使用可扩展且可解释的操作分析分析模型来自动调整并行性,预取,并在主机资源约束下进行缓存。在五个代表性的ML管道中,水管工的速度最高为47倍,用于误导的管道。通过自动化缓存,水管工的端到端速度超过50%,与最先进的调谐器相比。
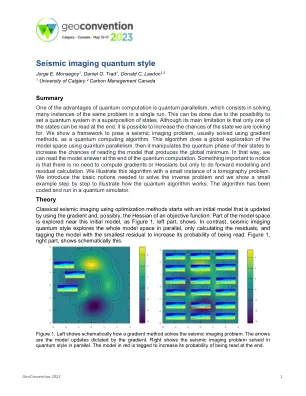
地震成像量子样式
量子计算的优点之一是量子并行性,它在于在单个运行中解决许多相同问题的实例。这可以通过在状态叠加中设置量子系统,因此可以执行此操作。尽管其主要限制是最终只能阅读其中一个州,但有可能增加我们正在寻找的国家的机会。我们展示了一个框架来提出一个地震成像问题,通常是使用梯度方法作为量子计算算法解决的。该算法使用量子并行性对模型空间进行全局探索,然后操纵其状态的量子阶段,以增加读取产生全局最小值的模型的机会。这样,我们可以在量子计算结束时阅读模型答案。重要的是要注意的是,不需要计算梯度或黑姐妹,而只需进行正向建模和剩余计算。我们用层析成像问题的小实例说明了这种算法。我们介绍了解决逆问题所需的基本概念,我们逐步展示了一个小示例,以说明量子算法如何工作。该算法已被编码并在量子模拟器中运行。

可编程生物分子介导的处理器
每当提到“计算机”一词时,我们的直觉都会自动将其与监视器和键盘的图像相关联,或各种技术术语,例如中央程序单元(CPU)(CPU),随机访问存储器(RAM)和仅阅读内存(ROM)。这是因为我们已经习惯了通过使用通常称为数字计算机的设备来模拟计算的概念,这些设备包括在硅基板上组装的一系列功能性组件。自1970年代初期引入第一台数字计算机以来,提高了其计算能力 - 处理速度,并行性,最小化和能源效率 - 一直是最令人关注的问题。要满足对加工速度和并行性的不断增长的需求,必须减小单个晶体管元素的大小。,因此允许将其他处理单元包装在同一硅死亡上;但是,提高包装密度总是会带来问题,包括增加功耗和有问题的散热问题。此外,在制造数字计算机中,硅基质作为基础材料始终对健康和环境产生负面影响。1最重要的是,整个半导体行业正在迅速接近摩尔定律所预测的身体约束。2此外,基于


05 EES 141 电力系统仪表 05 EES ...
并行算法用于负载流分析、故障分析、意外事件评估和暂态稳定性研究。20 小时。参考书目:1. Vipin Kumar、Ananth Grama、Anshul Gupta 和 George Karypis - 并行计算简介 - 算法设计和分析,Benjamin/Cummings 出版公司,1994 年。2. MJQuinn - 并行计算 - 理论与实践,McGraw-Hill 出版公司,1994 年。3. Kai Hwang - 高级计算机体系结构 - 并行性、可扩展性、可编程性、

研究 CFD 量子电路模拟的硬件加速
在众多量子计算模型中,量子电路模型是与当前量子硬件交互的最著名和最常用的模型。量子计算机的实际应用是一个非常活跃的研究领域。尽管取得了进展,但对物理量子计算机的访问仍然相对有限。此外,现有机器容易受到量子退相干导致的随机误差的影响,并且量子比特数、连接性和内置纠错能力也有限。因此,在经典硬件上进行模拟对于量子算法研究人员在模拟错误环境中测试和验证新算法至关重要。计算系统变得越来越异构,使用各种硬件加速器来加速计算任务。现场可编程门阵列 (FPGA) 就是这样一种加速器,它是可重构电路,可以使用标准化的高级编程模型(如 OpenCL 和 SYCL)进行编程。 FPGA 允许创建专门的高度并行电路,能够模拟量子门的量子并行性,特别是对于可以同时执行许多不同计算或作为深度管道的一部分执行的量子算法类。它们还受益于非常高的内部内存带宽。本文重点分析了应用于计算流体动力学的量子算法。在这项工作中,我们介绍了基于模型格子的流体动力学公式的新型量子电路实现,特别是使用量子计算基础编码的 D1Q3 模型,以及使用 FPGA 对电路进行高效模拟。这项工作朝着格子玻尔兹曼方法 (LBM) 的量子电路公式迈出了一步。对于在 D1Q3 晶格模型中实现非线性平衡分布函数的量子电路,展示了如何引入电路变换,以促进在 FPGA 上高效模拟电路,并利用其细粒度并行性。我们表明,这些转换使我们能够在 FPGA 上利用更多的并行性并改善内存局部性。初步结果表明,对于此类电路,引入的变换可以缩短电路执行时间。我们表明,与 CPU 模拟相比,简化电路的 FPGA 模拟可使每瓦性能提高 3 倍以上。我们还展示了在 GPU 上评估相同内核的结果。