XiaoMi-AI文件搜索系统
World File Search System并行性

硅光子学的自由空间应用:综述
摘要:硅光子学最近已将其应用扩展到提供自由空间发射以检测或操纵外部物体。最显著的例子是硅光学相控阵,它可以引导自由空间光束以实现芯片级固态激光雷达。其他例子包括自由空间光通信、量子光子学、成像系统和光遗传学探针。与由体光学元件组成的传统光学系统相比,硅光子学将光学系统小型化为具有许多功能波导元件的光子芯片。通过利用成熟的单片 CMOS 工艺,硅光子学实现了大批量生产、可扩展性、可重构性和并行性。在本文中,我们回顾了基于硅光子学的光束控制技术的最新进展,包括光学相控阵、焦平面阵列和色散光栅衍射。还讨论了用于产生准直、聚焦、贝塞尔和涡旋光束的各种光束整形技术。最后,我们展望了硅光子学在自由空间应用的前景和挑战。

用于推理的脑启发硬件解决方案......
由于浮点运算需要大量资源,使用传统计算范式在贝叶斯网络中实现推理(即计算后验概率)在能源、时间和空间方面效率低下。脱离传统计算系统以利用贝叶斯推理的高并行性最近引起了人们的关注,特别是在贝叶斯网络的硬件实现方面。这些努力通过利用新兴的非易失性设备,促成了从数字电路、混合信号电路到模拟电路的多种实现。已经提出了几种使用贝叶斯随机变量的随机计算架构,从类似 FPGA 的架构到交叉开关阵列等受大脑启发的架构。这篇全面的评论论文讨论了考虑不同设备、电路和架构的贝叶斯网络的不同硬件实现,以及解决现有硬件实现问题的更具未来性的概述。

使用 Python 进行遗传算法实践
第 1 章:遗传算法简介 8 什么是遗传算法? 9 达尔文进化论 9 遗传算法的类比 10 基因型 10 种群 11 适应度函数 11 选择 11 交叉 12 突变 12 遗传算法背后的理论 13 模式定理 14 与传统算法的区别 15 基于种群 16 遗传表示 16 适应度函数 16 概率行为 17 遗传算法的优势 17 全局优化 18 处理复杂问题 19 处理缺乏数学表示的情况 19 抗噪声能力 19 并行性 20 持续学习 20 遗传算法的局限性 20 特殊定义 21 超参数调整 21 计算密集型 21 过早收敛 21 没有保证的解决方案 22 遗传算法的用例 22 总结 23 进一步阅读 23 第 2 章:理解遗传算法的关键组成部分 24 遗传算法的基本流程 25 创建初始种群 26

论 NISQ 时代及以后的量子图卷积神经网络设计
摘要 — 图卷积神经网络 (GCN) 的大小快速增长,在传统计算平台(例如 CPU、GPU、FPGA 等)上遇到了计算和内存瓶颈。另一方面,量子计算为计算提供了极高的并行性。尽管最近对量子神经网络进行了研究,但对量子图神经网络的研究仍处于起步阶段。这里的关键挑战是如何将图拓扑信息和 GCN 的学习能力集成到量子电路中。在这项工作中,我们利用 Givens 旋转及其量子实现来编码图信息;此外,我们采用广泛使用的变分量子电路来引入可学习参数。在此基础上,我们提出了一种全量子设计的图卷积神经网络,即“QuGCN”,用于图结构数据的半监督学习。实验结果表明,我们的设计在 Cora 子数据集上的节点分类准确率方面可与经典 GCN 相媲美。更重要的是,我们展示了当特征数量增加时,所提出的量子 GCN 设计可以实现的潜在优势。

一种受大脑启发的低维计算分类器,用于微型设备推理
通过模仿类似大脑的认知并利用并行性,超维计算 (HDC) 分类器已成为实现高效设备推理的轻量级框架。尽管如此,它们有两个根本缺点——启发式训练过程和超高维度——导致推理精度不理想且模型尺寸过大,超出了资源受限严格的微型设备的能力。在本文中,我们解决了这些根本缺点并提出了一种低维计算 (LDC) 替代方案。具体而言,通过将我们的 LDC 分类器映射到等效神经网络,我们使用原则性训练方法优化我们的模型。最重要的是,我们可以提高推理精度,同时成功地将现有 HDC 模型的超高维度降低几个数量级(例如 8000 对 4/64)。我们通过考虑不同的数据集在微型设备上进行推理来进行实验以评估我们的 LDC 分类器,并且在 FPGA 平台上实现不同的模型以进行加速。结果表明,我们的 LDC 分类器比现有的受大脑启发的 HDC 模型具有压倒性优势,特别适合在微型设备上进行推理。

量子扇出:电路优化和技术建模
摘要 — 指令调度是量子计算中一个关键的编译器优化,就像它对于经典计算一样。当前的调度程序通过允许同时执行指令来优化数据并行性,只要它们的量子位不重叠。然而,在许多量子硬件平台上,重叠量子位上的指令可以通过全局交互同时执行。例如,虽然传统量子电路中的扇出从逻辑层面来看只能按顺序实现,但物理层面的全局交互允许一步实现扇出。我们利用这种同时扇出原语来优化 NISQ(嘈杂中型量子)工作负载的电路合成。此外,我们引入了基于扇出的新型量子存储器架构。我们的工作还解决了扇出原语的硬件实现问题。我们对捕获离子量子计算机进行了真实的模拟。我们还展示了使用超导量子位扇出的实验概念验证。我们在实际噪声模型下对 NISQ 应用电路和量子存储器架构进行了深度(运行时)和保真度估计。我们的模拟结果表明,结果令人满意,运行时具有渐近优势,错误率降低了 7-24%。

Pigeonhole排序的平行化用于有效的数据排序
摘要 - 对并行排序算法的需求是由对大规模数据集有效处理的越来越多的需求所驱动的。Pigeonhole分选是在线性时间内携带排序的分类算法之一。本研究的重点是通过采用并行编程技术专门消息传递界面(MPI)和计算统一设备体系结构(CUDA)来提高提高孔分选方法的功效来提高算法的性能。主要目的是开发和评估鸽子孔分选的并行解决方案,以优化数据密集型应用中的排序效率。开始对Pigeonhole排序算法的顺序设计进行全面分析,该工作将使用CUDA进行图形处理单元(GPU)加速器和MPI创建并行实现,以进行分布式内存并行性。这项工作有助于将Pigonhole分类算法适应平行背景的宝贵见解。这些发现强调了平行化在减少总体计算时间方面的潜在优势。索引术语 - 伪造台面,并行编程,消息传递接口,计算统一设备体系结构,图形处理单元,加速
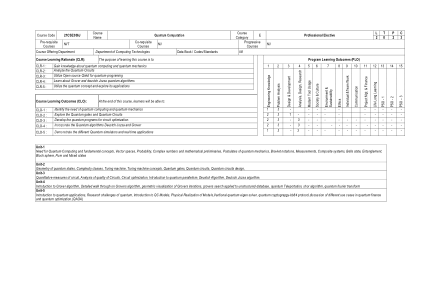
课程代码 21CSE306J 课程名称 量子...
单元 1 量子计算需求和基本概念、向量空间、概率、复数和数学预备知识、量子力学假设、Bra-ket 符号、测量、复合系统、贝尔态、纠缠、布洛赫球、纯态和混合态 单元 2 量子态的几何形状、复杂性类、图灵机、图灵机概念、量子门、量子电路、量子电路设计 单元 3 电路的定量测量、电路质量分析、电路优化、量子并行性简介、Deustch 算法、Deutsch Jozsa 算法 单元 4 Grover 算法简介、Grovers 算法详细介绍、Grovers 迭代的几何可视化、Grovers 搜索应用于非结构化数据库、量子隐形传态、Shor 算法、量子傅里叶变换 单元 5 量子应用简介、量子研究挑战、QC 模型简介、模型的物理实现、变分量子特征求解器、量子密码学-bb84协议,讨论量子金融和量子优化中的不同用例。(QAOA)
用于量子化学的可扩展神经量子态架构
摘要 量子态神经网络表示的变分优化已成功应用于解决相互作用的费米子问题。尽管发展迅速,但在考虑大规模分子时仍存在重大的可扩展性挑战,这些分子对应于由数千甚至数百万个泡利算子组成的非局部相互作用的量子自旋哈密顿量。在这项工作中,我们引入了可扩展的并行化策略来改进基于神经网络的变分量子蒙特卡罗计算,以用于从头算量子化学应用。我们建立了 GPU 支持的局部能量并行性来计算潜在复杂分子哈密顿量的优化目标。使用自回归采样技术,我们展示了实现耦合簇所需的挂钟时间的系统改进,其中基线目标能量高达双激发。通过将所得自旋哈密顿量的结构纳入自回归采样顺序,性能得到进一步增强。与经典近似方法相比,该算法实现了令人鼓舞的性能,并且与现有的基于神经网络的方法相比,具有运行时间和可扩展性优势。

一种受大脑启发的低维计算分类器,用于微型设备推理
通过模仿类似大脑的认知并利用并行性,超维计算 (HDC) 分类器已成为实现高效设备推理的轻量级框架。尽管如此,它们有两个根本缺点——启发式训练过程和超高维度——导致推理精度不理想且模型尺寸过大,超出了资源受限严格的微型设备的能力。在本文中,我们解决了这些根本缺点并提出了一种低维计算 (LDC) 替代方案。具体而言,通过将我们的 LDC 分类器映射到等效神经网络,我们使用原则性训练方法优化我们的模型。最重要的是,我们可以提高推理精度,同时成功地将现有 HDC 模型的超高维度降低几个数量级(例如 8000 对 4/64)。我们通过考虑不同的数据集在微型设备上进行推理来进行实验以评估我们的 LDC 分类器,并且在 FPGA 平台上实现不同的模型以进行加速。结果表明,我们的 LDC 分类器比现有的受大脑启发的 HDC 模型具有压倒性优势,特别适合在微型设备上进行推理。