XiaoMi-AI文件搜索系统
World File Search System开销

分布式量子计算中的概率感知量子比特到处理器映射
量子计算具有令人兴奋的潜力,但当前的技术障碍在于单个处理器中的量子比特数量有限。解决这一挑战的一种方法是将小型、专用的量子处理器组装成一个更大的计算系统,称为分布式量子计算。在这项工作中,我们专注于分布式量子计算中的一个关键问题:如何将特定量子电路的逻辑量子比特映射到异构量子网络中的不同处理器,以尽量减少总体通信开销。为了解决这个问题,我们制定了一个概率感知的量子比特到处理器映射模型,其中每对处理器之间的通信开销是通过基于链路纠缠生成率的概率分析确定的。我们还在模型中引入了多流路由协议,以提高整体纠缠率。之后,我们采用多级混合模拟退火算法来最小化总通信开销。最后,我们进行了广泛的模拟,以展示我们的解决方案在各种系统设置下的优越性。

申请指南2024-开放竞争中的研究补助
附加信息:在这里,您指定是否要要求开销(最高5%),添加有关从Leo Foundation Durin G获得工资总数的信息,并估计项目的平均年度全日制等效物(FTE)为项目的平均年度全日制等效物(例如,例如,技术人员都可以在100%和技术人员工作的项目中添加1.5次。指定开销以更新预算计算后,请记住再次按“保存草稿”。应使用“现有全职员工的薪水”来解释为什么要求该小组的薪水,因为假定他们已经通过其他地方的资金来支付。

冷战期间的美国密码学,1945-1989
集中化的困境 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ... ... 371 波特信号和 TEBO 项目 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ........................................................................................................................................................................................................................................................................382 土耳其....................................................................................................................................................................................................................................................................................................................................................... ... . .... ... 393 海军 SIG INT 舰艇....................... ... . ... ... .. ....... ... .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. 401 开销 .. ...

导航不断发展的ALM技术景观
银行5的负担4。如果云解决方案焦点,则应检查所讨论的系统,以确定它是否仅仅是一个本地解决方案,即迁移到云到云(云已经准备就绪),甚至是云本地。可以通过云操作实现的优化水平在很大程度上取决于成熟的技术水平。云解决方案的起点效率较低,因为各种任务的分离会导致开销。但是,如果正确实施,它们可以增强可扩展性。具体优势包括通过容器化,增加的标准化,流式备份和恢复过程,提高过程效率以及更好地利用系统资源的简化和可重复的测试系统设置。结果,可以抵消初始开销。
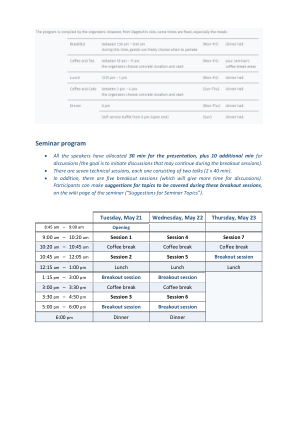
研讨会日程
我们展示了如何通过几何局部量子操作和高效的经典计算来实现涉及任意量子比特对之间门的通用量子电路。我们证明,对我们推导方案的不完美实现进行建模的电路级局部随机噪声等效于原始电路中的局部随机噪声。我们的构造导致量子电路深度增加常数倍,量子比特数增加多项式开销:为了在 𝑛 量子比特上执行任意量子电路,我们给出了一个涉及 𝑂(𝑛 3 2 ⁄ log 3 𝑛) 量子比特的 3D 量子容错架构,以及一个使用 𝑂(𝑛 2 log 3 𝑛) 量子比特的准二维架构。应用于最近的容错构造,这为具有局部操作、多项式量子比特开销和准多对数深度开销的通用量子计算提供了容错阈值定理。更一般地说,我们的变换省去了在设计容错量子信息处理方案时考虑操作局部性的需要。https://arxiv.org/abs/2402.13863



高能效率LSTM加速器体系结构
摘要:修剪和量化是加速LSTM(长短期内存)模型的两种常用方法。但是,传统的线性量化通常会遇到梯度消失的问题,而现有的修剪方法都有产生不希望的不规则稀疏性或大型索引开销的问题。为了减轻消失梯度的问题,这项工作提出了一种归一化的线性量化方法,该方法首先将操作数正常化,然后在局部混合最大范围内进行量化。为了克服不规则的稀疏性和大型索引开销的问题,这项工作采用了排列的块对角掩模矩阵来产生稀疏模型。由于稀疏模型高度规律,因此可以通过简单的计算获得非零权重的位置,从而避免了大型索引开销。基于由排列的块对角面胶质矩阵产生的稀疏LSTM模型,本文还提出了高能耐加速器的Permlstm,该材料全面利用了有关基质 - 载体乘积的重量,激活和产品的稀疏性,从而导致55.1%的动力减少。与先前报道的其他基于FPGA的LSTM加速器相比,与先前报道的其他基于FPGA的LSTM加速器相比,该加速器已在以150 MHz运行的ARRIA-10 FPGA上实现,并达到2.19×〜24.4×能量效率。

AlphaRouter:基于强化学习和树搜索的量子电路路由
摘要 — 量子计算机有可能在优化和数字分解等重要任务上超越传统计算机。它们的特点是连接性有限,这需要在程序执行期间将其计算位(称为量子位)路由到特定位置以执行量子操作。传统上,最小化路由开销的 NP 难优化问题已通过次优的基于规则的路由技术解决,而成本函数设计中嵌入了固有的人为偏见。本文介绍了一种将蒙特卡洛树搜索 (MCTS) 与强化学习 (RL) 相结合的解决方案。我们基于 RL 的路由器称为 AlphaRouter,其性能优于当前最先进的路由方法,并且生成的量子程序的路由开销减少了多达 20%,从而显著提高了量子计算的整体效率和可行性。

qprof:受 gprof 启发的量子分析器
由于可以将分析的程序直接运行在目标硬件上,“指令集模拟器”可用于在隔离且完全受控的环境中运行要分析的程序。使用这种技术的分析器的优点是十分准确,并且可以收集各种各样的指标,但是它们会给分析的程序运行时增加相当大的开销。某些分析器(如 gprof [19])使用的另一种技术是通过添加或修改代码的指令来检测代码,以收集有关其执行的数据。这类分析器可以收集的信息不如指令集模拟器方法那么详尽,但是它们给程序运行时执行增加的开销通常相对较低。最后,某些分析器使用静态分析来收集数据,甚至无需执行程序。对于传统计算机,由于当前传统处理器执行指令的方式非常复杂,这些分析器仅限于指令数及其变化等信息。