XiaoMi-AI文件搜索系统
World File Search System扩散


RF扩散:通过时频扩散
摘要以及AIGC在CV和NLP中闪耀,其在无线领域中的潜力也近年来也出现了。然而,由于表示功能有限,现有面向RF的生成解决方案不适合生成高质量的时间序列RF数据。在这项工作中,受到CV和NLP扩散模型的稳定成就的启发,我们将其调整到RF域并提出RF扩散。为了促进RF信号的独特特征,我们首先引入了一种新颖的时频扩散理论,以启用原始扩散模型,使其能够在RF信号的时间,频率和复杂值域内利用信息。在此基础上,我们提出了一个层次扩散变压器,将理论转化为一种实用的生成DNN,通过跨越网络体系结构,功能障碍和复杂评估的操作员的精心设计,使RF-diffusion成为一种多功能的解决方案,以实现多种多样的解决方案。表现出了RF-Diffusion在合成Wi-Fi和FMCW信号中的出色性能。我们还展示了RF扩散在增强Wi-Fi传感系统和在5G网络中执行通道估计的多功能性。



从扩散MRI
结构性脑图通常仅限于定义节点为灰质区域,其边缘会反映在成对节点之间的轴突投影的密度。在这里,我们将脑面膜内的整个体素集成为高分辨率,主题特定图的节点。我们使用扩散张量和从扩散MRI数据得出的扩散张量和分布分布函数来定义局部体素至素连接的强度。我们在人类Connectome项目的数据上研究图形的Laplacian光谱特性。然后,我们通过codrustes验证方案评估Laplacian eigenmodes的受试者间变异性程度。fi-Nelly,我们证明了通过图信号处理的基本解剖结构来塑造功能性MRI数据的程度。图形拉普拉斯特征模式表现出高度分辨的空间pro文件,反映了与主要白色途径相对应的分布模式。我们表明,这种高分辨率图的特征空间的固有维度仅仅是图尺寸的一部分。通过在低频图lapla-cian eigenmodes上投射任务和静止状态数据,我们表明大脑活动可以通过一小部分低频组合的子集很好地近似。所提出的图形开放了研究大脑的新途径,无论是通过图形或光谱图理论探索其组织特性,还是将它们视为在内部层面上观察到大脑功能的脚手架。

RF扩散:通过时频扩散
摘要以及AIGC在CV和NLP中闪耀,其在无线领域中的潜力也近年来也出现了。然而,由于表示功能有限,现有面向RF的生成解决方案不适合生成高质量的时间序列RF数据。在这项工作中,受到CV和NLP扩散模型的稳定成就的启发,我们将其调整到RF域并提出RF扩散。为了促进RF信号的独特特征,我们首先引入了一种新颖的时频扩散理论,以启用原始扩散模型,使其能够在RF信号的时间,频率和复杂值域内利用信息。在此基础上,我们提出了一个层次扩散变压器,将理论转化为一种实用的生成DNN,通过跨越网络体系结构,功能障碍和复杂评估的操作员的精心设计,使RF-diffusion成为一种多功能的解决方案,以实现多种多样的解决方案。表现出了RF-Diffusion在合成Wi-Fi和FMCW信号中的出色性能。我们还展示了RF扩散在增强Wi-Fi传感系统和在5G网络中执行通道估计的多功能性。

扩散40年
扩散磁共振成像(MRI)的领域在过去40年中已经走了很长一段路,并且该研讨会庆祝已经取得的进步。从基本扩散测量技术的早期到当前最新的微观结构成像和拖拉术方法,扩散MRI已成为临床前和临床研究的必不可少的工具。研讨会将提供有关扩散史MRI史的全面概述,包括开发新的脉冲序列,建模,数据分析和图像处理的进步,包括AI,以及在生物医学研究的各个领域中的应用:从神经病学到精神病学到精神病学到肿瘤学。研讨会还将在该领域的开拓者和专家汇聚,以讨论在方法论发展和应用方面的扩散MRI的历史和最新进展。通过主题演讲,小组讨论和海报会议,与会者将有机会通过该领域的最新研究和最先进的技术来了解扩散MRI的当前现状,并了解未来正在为未来做饭。最后,该研讨会旨在弥合方法论发展与临床实践之间的差距,并在不久的将来为其整合提供道路。摘要提交截止日期:2024年12月6日| 23:59 UTC

从扩散MRI
摘要 - 目标:结构性大脑图通常仅限于定义节点,因为灰质区域是地图集的,边缘反映了淋巴结对之间的轴突投影的密度。在这里,我们将脑面膜内整个体素集成为高分辨率,主题特定图的节点。方法:我们使用扩散张量和从扩散MRI数据得出的扩散张量和方向分布函数来定义局部素至素连接的强度。我们在人类连接项目的数据上研究图形的拉普拉斯光谱特性。然后,我们通过Procrustes验证方案评估Laplacian本征模的受试者间变异性的程度。最后,我们证明了通过图形信号处理的基本解剖结构来塑造功能性MRI数据的程度。结果:图形拉普拉斯特征模式表现出高度分辨的空间专题,反映了与主要白质途径相对应的分布模式。我们表明,这种高分辨率图的特征空间的固有维度仅仅是图尺寸的一部分。通过在低频图Laplacian eigenmodes上投射任务和静止状态数据,我们表明大脑活动可以通过一小部分低频组件来很好地近似。结论:所提出的图形在研究大脑时开放了新的途径,无论是通过图或光谱图理论探索其组织特性,或者通过将它们视为在单个层面上观察到大脑功能的支架。

通过扩散扩散性
超明显点模式可以通过超均匀缩放指数α> 0进行分类,该指数α> 0,该指数符合结构因子s(k)的幂律缩放行为,这是波数k。| K |在起源附近,例如s(k)〜| K | α在s(k)随着k连续变化为k→0。在本文中,我们表明可传播性是确定s(k)不连续的准膜系统的有效方法,并由一组密集的bragg峰组成。它已在[Phys。修订版e 104,054102(2021)],对于有限α的培养基,可以将过剩可传播性s(∞)-s(t)的长时间行为拟合到形式t - (d-α) / 2的幂定律中,在其中d是空间维度,以准确提取α,以使α准确提取α。我们首先将准二极管和极限 - 周期点模式转换为两相介质,通过将它们映射到相同的非重叠磁盘的包装上,其中与磁盘的空间内部代表一个相位,并且在其外部空间代表了第二阶段。然后,我们计算包装的光谱密度〜χv(k),并最终计算其多余的散布性的长期行为。特别是我们表明,多余的传播性可用于准确提取一维(1D)极限 - 周期性倍加倍链(α= 1)和1D Quasicrystalline fibonacci链(α= 3)至0。02%的分析已知的确切结果。此外,我们获得α= 5的值。97±0。06对于二维penrose瓷砖,并提出了合理的理论参数,强烈表明α完全等于六个。我们还表明,由于此处检查的结构的自相似性,可以截断用于计算散布性并获得α准确值的散射信息的小k区域,并且与未截断的情况下的偏差很小,该案例随着系统尺寸的增加而降低。这强烈表明,可以从适度尺寸的有限样品中获得α的良好估计。此处描述的方法提供了一个简单而通用的过程,可以准确表征Quasrystalline中存在的大规模翻译顺序,并在任何自相似的空间维度中都具有极限 - 周期介质。此外,从编码〜χV(k)中编码的这些两相介质中提取的散射信息可用于估计其物理性质,例如它们的有效动态介电常数,有效的动态弹性常数和流动性。
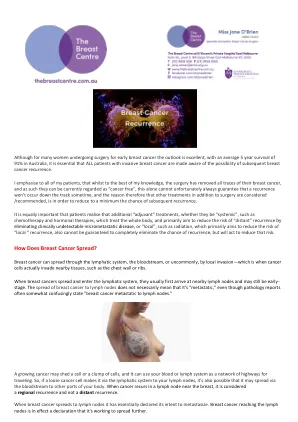
乳腺癌如何扩散?
局部和/或区域性复发:之前治疗过的乳腺癌复发,复发部位在乳房、胸壁或区域淋巴结内。 新的原发性乳腺癌:在一侧或另一侧乳房中出现不相关的新乳腺癌。这实际上根本不是局部复发,而是乳房中的新癌症(通常称为新原发性)。这通常发生在原发癌症发生多年后,并且发生在乳房的完全不同的区域。其病理通常不同,例如,小叶而不是导管。虽然它们在乳腺癌保留的统计数据中通常被算作复发,但它们应该被视为完全新的癌症,就像对侧乳房中的新癌症一样。 远处或全身性复发或转移:扩散到远处器官。这比局部或区域性复发严重得多,通常被称为“第 4 期”疾病。对于乳腺癌患者来说,最常见的扩散部位是骨骼、肝脏、肺和脑