XiaoMi-AI文件搜索系统
World File Search System技术预测
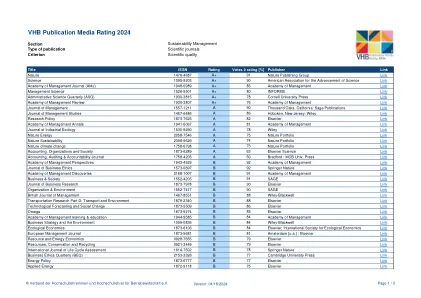
VHB 出版物媒体评级 2024
标题 ISSN 评分 投票数 ≥ 评分 [%] 出版商 链接 Nature 1476-4687 A+ 91 Nature Publishing Group 链接 Science 1095-9203 A+ 90 美国科学促进会 链接 Academy of Management Journal (AMJ) 1948-0989 A+ 85 Academy of Management 链接 Management Science 1526-5501 A+ 80 INFORMS 链接 Administrative Science Quarterly (ASQ) 1930-3815 A+ 78 Cornell University Press 链接 Academy of Management Review 1930-3807 A+ 76 Academy of Management 链接 Journal of Management 1557-1211 A 90 Thousand Oaks, California: Sage Publications 链接 Journal of Management Studies 1467-6486 A 86 Hoboken, New Jersey: Wiley 链接 Research Policy 1873-7625 A 82 Elsevier 链接 Academy of Management Annals 1941-6067 A 81 管理学院链接 工业生态学杂志 1530-9290 A 78 Wiley 链接 自然能源 2058-7546 A 75 自然投资组合链接 自然可持续性 2398-9629 A 74 自然投资组合链接 自然气候变化 1758-6798 A 73 自然投资组合链接 会计、组织与社会 1873-6289 A 63 Elsevier Science 链接 会计、审计与问责杂志 1758-4205 A 50 布拉德福德:MCB 大学Press Link 《管理学院展望》 1943-4529 B 92 管理学院 Link 《商业伦理学杂志》 1573-0697 B 92 Springer Nature Link 《管理学院发现》 2168-1007 B 91 管理学院 Link 《商业与社会》 1552-4205 B 91 SAGE Link 《商业研究杂志》 1873-7978 B 90 Elsevier Link 《组织与环境》 1552-7417 B 90 SAGE Link 《英国管理杂志》 1467-8551 B 88 Wiley-Blackwell Link 《交通研究 D 部分:交通与环境》 1879-2340 B 88 Elsevier Link 《技术预测与社会变革》 1873-5509 B 86 Elsevier Link Omega 1873-5274 B 85 Elsevier Link 《管理学院学习与教育》 1944-9585 B 84 管理学院链接 商业战略与环境 1099-0836 B 84 Wiley-Blackwell Link 生态经济学 1873-6106 B 84 Elsevier;国际生态经济学会链接 欧洲管理杂志 1873-5681 B 81 阿姆斯特丹 [ua] : Elsevier 链接 资源与能源经济学 0928-7655 B 79 Elsevier 链接 资源、保护和回收利用 0921-3449 B 79 Elsevier 链接 国际生命周期评估杂志 1614-7502 B 78 Springer Nature 链接 商业伦理季刊 (BEQ) 2153-3326 B 77 剑桥大学出版社链接 能源政策 1873-6777 B 77 Elsevier 链接 应用能源 1872-9118 B 75 Elsevier 链接

基于多目标增强学习的同时主题和预测模型...
[1] Shuo Xu,Liyuan Hao,Guancan Yang,Kun Lu和Xin An。基于主题模型的框架,用于检测和预测新兴技术。技术预测和社会变革,第1卷。162,p。 120366,2021。[2] Xing Yi和James Allan。信息检索的Uti-Lizing主题模型的比较研究。在Mohand Boughanem,Catherine Berrut,Josiane Mothe和Chantal Soule-Dupuy,编辑中,信息检索的进步,pp。29–41,柏林,海德堡,2009年。Springer Berlin Heidel-Berg。[3] Shixia Liu,Michelle X. Zhou,Shimei Pan,Yangqiu Song,Weihong Qian,Weijia Cai和Xiaoxiao Lian。tiara:主动,基于主题的视觉文本摘要和分析。acm trans。Intell。 Syst。 技术。 ,卷。 3,编号 2,2012年2月。 [4] David Blei,Andrew Ng和Michael Jordan。 潜在的dirich-让分配。 在T. Dietterich,S。Becker和Z. Ghahra mani中,编辑,《神经信息处理系统的进步》,第1卷。 14。 MIT出版社,2001。 [5] Yishu Miao,Edward Grefenstette和Phil Blunsom。 涵盖神经变异性推断的离散潜在主题,2017年。 [6] Akash Srivastava和Charles Sutton。 主题模型的自动编码变量推断,2017年。 [7] Maarten Grootendorst。 bertopic:基于类的TF-IDF程序的神经主题建模,2022。 [8] David M. Blei和John D. La效应。 动态主题模式。Intell。Syst。技术。,卷。3,编号2,2012年2月。[4] David Blei,Andrew Ng和Michael Jordan。潜在的dirich-让分配。在T. Dietterich,S。Becker和Z. Ghahra mani中,编辑,《神经信息处理系统的进步》,第1卷。14。MIT出版社,2001。[5] Yishu Miao,Edward Grefenstette和Phil Blunsom。涵盖神经变异性推断的离散潜在主题,2017年。[6] Akash Srivastava和Charles Sutton。主题模型的自动编码变量推断,2017年。[7] Maarten Grootendorst。bertopic:基于类的TF-IDF程序的神经主题建模,2022。[8] David M. Blei和John D. La效应。动态主题模式。在第23届机器学习国际会议论文集中,ICML '06,p。 113–120,纽约,纽约,美国,2006年。计算机协会。[9] c´edric f´evotte和j´erˆome idier。算法,用于beta-Divergence,2011年。 [10] Silvia Terragni,Elisabetta Fersini,Bruno Giovanni Galuzzi,Pietro Tropeano和Antonio Candelieri。 八八张:对主题模型进行组合和优化很简单! 在Dimitra Gkatzia和Djam´e Seddah中,编辑,第16届会议论文集算法,用于beta-Divergence,2011年。[10] Silvia Terragni,Elisabetta Fersini,Bruno Giovanni Galuzzi,Pietro Tropeano和Antonio Candelieri。八八张:对主题模型进行组合和优化很简单!在Dimitra Gkatzia和Djam´e Seddah中,编辑,第16届会议论文集
![B'Against心血管疾病和各种人群中的全因死亡率[4,6,7]。因此,由于人口寿命增加的相关性很大,CF的连续测量可以被视为生命体征,因此,这应该是公共卫生的优先事项[8];但是,CF的定义和评估方式是矛盾的[9 \ XE2 \ x80 \ x93 11]。通常通过测量最大氧气吸收(_ vo 2 Max)来评估CF,作为在心肺运动测试(CPET)中获得的最大有氧力量指数[11 \ XE2 \ x80 \ x93 13]。 _ vo 2 max分别反映了肺,心血管和代谢系统分别捕获,运输和利用氧气的最大能力,这直接受CF的影响[13,14]。但是,CPET期间的_ VO 2最大测量需要受过训练的专业人员和昂贵的设备[15 \ XE2 \ X80 \ X93 17],并且很少用作一般人群中的预防工具。因此,在CPET期间通过_ VO 2 Max评估的CF均未为所有人群提供,并且无法连续获得。因此,考虑到执行CPET的困难,但是考虑到评估心血管适应性的高临床价值,需要进行连续评估CF的新方法。这些方法在日常生活的无监督活动中,如果在实验室外部进行,则所有人口都可以更现实,毫不动摇,并且可以使用所有人口。](/simg/6\60221f81dd15cb179822a059b2fd30afcae0ffe8.webp)
B'Against心血管疾病和各种人群中的全因死亡率[4,6,7]。因此,由于人口寿命增加的相关性很大,CF的连续测量可以被视为生命体征,因此,这应该是公共卫生的优先事项[8];但是,CF的定义和评估方式是矛盾的[9 \ XE2 \ x80 \ x93 11]。通常通过测量最大氧气吸收(_ vo 2 Max)来评估CF,作为在心肺运动测试(CPET)中获得的最大有氧力量指数[11 \ XE2 \ x80 \ x93 13]。 _ vo 2 max分别反映了肺,心血管和代谢系统分别捕获,运输和利用氧气的最大能力,这直接受CF的影响[13,14]。但是,CPET期间的_ VO 2最大测量需要受过训练的专业人员和昂贵的设备[15 \ XE2 \ X80 \ X93 17],并且很少用作一般人群中的预防工具。因此,在CPET期间通过_ VO 2 Max评估的CF均未为所有人群提供,并且无法连续获得。因此,考虑到执行CPET的困难,但是考虑到评估心血管适应性的高临床价值,需要进行连续评估CF的新方法。这些方法在日常生活的无监督活动中,如果在实验室外部进行,则所有人口都可以更现实,毫不动摇,并且可以使用所有人口。
B'Against心血管疾病和各种人群中的全因死亡率[4,6,7]。因此,由于人口寿命增加的相关性,CF的连续测量可以被视为生命体征,因此,这应该是公共卫生的优先事项[8];但是,CF的定义和评估方式是矛盾的[9 \ XE2 \ x80 \ x93 11]。CF,作为在心肺运动测试(CPET)期间获得的最大有氧功率指数[11 \ XE2 \ X80 \ X93 13]。_ vo 2 max分别反映了肺,心血管和代谢系统分别捕获,运输和利用氧气的最大容量,该系统直接受CF的影响[13,14]。但是,CPET期间的_ VO 2最大测量需要训练有素的专业人员和昂贵的设备[15 \ XE2 \ X80 \ X93 17],并且很少用作一般人群中的预防工具。因此,在CPET期间由_ VO 2 MAX评估的CF均不能为所有人群提供,并且无法连续获得。因此,考虑到执行CPET的困难,但是鉴于评估心血管健身的高临床价值,需要进行连续评估CF的新方法。在无监督的日常生活活动(ADL)的活动期间,如果在实验室外部进行的所有人口(ADL)[18],这些方法可能更现实,无障碍和可供所有人口访问。最近,在医学中使用了可解释的模型来更好地证明预测模型的决策[26]。可穿戴传感器和生命信号融合可能代表连续推断CF的独特可能性,从而允许将来使用该技术来预测NCD,尤其是心血管疾病[6,7]。此外,越来越多的研究结合了使用磨损和机器学习技术来监测NCD患者的使用,尤其是在心脏呼吸型领域[19,20]。实际上,来自可穿戴设备的纵向数据似乎包含足够的信息,可以预测来自Com-Plex机器学习算法的无监督ADL的健康志愿者[21 \ XE2 \ X80 \ X93 25]。然而,尽管可穿戴设备和机器学习之间存在着巨大的潜力,但仍然缺乏使用这些技术预测NCD患者的CF的证据,尤其是在糖尿病,慢性肺部疾病和心血管疾病中。此外,了解这些模型如何通过机器学习算法训练,可以将重要信号转换为_ VO 2 Max可能会提供有关志愿者之间CF差异的复杂机械见解。由于_ vo 2最大词语算法的复杂性,基于从可穿戴技术获得的功能[25],纵向生命信号的解释能力被转换为_ vo 2 max的纵向范围非常低[26] [26],因为对给定模型的解释性及其性能之间的预期折衷是可以预测的健康及其健康的折算[27]。在本文中,我们调查了Shapley来评估CF预测问题中特征的重要性。众所周知,可穿戴传感器对于可以与机器学习技术相关的连续生物数据采集很有用,例如随机森林回归,神经网络和支持向量回归机器可预测CF [21,25]。因此,理解这些模型还可能表明人类\ Xe2 \ x80 \ x9cblack box \ xe2 \ x80 \ x80 \ x9d生理系统如何与环境相互作用,近似这些复杂算法的解释能力,即我们在使用简单的方法中所体验的内容,例如在线性性回归模型中所体验的内容。Shapley添加说明(SHAP)是一种源自Cociational Game理论的宝贵方法,该方法可用于解释根据从生物学数据获得的监督机器学习方法构建的复杂模型[26,28]。其使用的主要动机依赖于(1)其成为模型不可知论的能力(即,与任何模型相关的解释方法,以提取有关预测过程的额外信息'

Ratten, V.、Hasan, R.、Kumar, D.、Bustard, J.、Ojala, A. 和 Salamzadeh, Y. (2024)。向人工智能研究人员学习有关国际商业影响的知识。《Thunderbird 国际商业评论》,66(2),211-219。https://doi.org/10.1002/tie.22374
Aminov, KI、Krikukhin, IY 和 Zakharova, AV (2023)。人工智能在国际业务中应用的主要障碍和方向。经济与管理,29 (3),280 – 287。https://doi.org/10.35854/1998-1627-2023-3-280-287 Autio, E.、Mudambi, R. 和 Yoo, Y. (2021)。动荡世界中的数字化与全球化:离心力和向心力。全球战略杂志,11 (1),3 – 16。https://doi.org/10.1002/gsj.1396 Bahoo, S.、Cucculelli, M. 和 Qamar, D. (2023)。人工智能与企业创新:回顾与研究议程。技术预测与社会变革,188,122264。Bhatti, WA、Vahlne, J.-E.、Glowik, M. 和 Larimo, JA (2022)。工业 4.0 对 2017 年版乌普萨拉模型的影响。国际商业评论,31 (4),1 – 14。https://doi.org/10.1016/j.ibusrev.2022。101996 Borges, AFS、Laurindo, FJB、Spínola, MM、Gonçalves, RF 和 Mattos, CA (2021)。数字时代人工智能的战略性使用:系统文献综述和未来研究方向。国际信息管理杂志,57,102225。https://doi.org/10.1016/j.ijinfomgt.2020.102225 Choudhury, P.、Starr, E. 和 Agarwal, R. (2020)。机器学习与人力资本互补性:偏见缓解的实验证据。战略管理杂志,41 (8),1381 – 1411。https://doi.org/10.1002/smj.3152 Coviello, N.、Kano, L. 和 Liesch, PW (2017)。将乌普萨拉模型应用于现代世界:宏观背景和微观基础。国际商业研究杂志,48 (9),1151 – 1164。https://doi.org/10。 1057/s41267-017-0120-x Cuypers, IRP、Hennart, J.-F.、Silverman, BS 和 Ertug, G. (2021)。交易成本理论:过去的进展、当前的挑战和对未来的建议。管理学院年鉴,15 (1),111 – 150。https://doi.org/10.5465/annals.2019.0051 Davenport, T.、Guha, A.、Grewal, D. 和 Bressgott, T. (2020)。人工智能将如何改变营销的未来。 《市场营销科学院杂志》, 48 , 24 – 42。Dell'Acqua, F.、McFowland, E.、Mollick, ER、Lifshitz-Assaf, H.、Kellogg, K.、Rajendran, S.、Krayer, L.、Candelon, F. 和 Lakhani, KR (2023)。驾驭崎岖的技术前沿:人工智能对知识工作者生产力和质量影响的现场实验证据。哈佛商学院技术与运营管理部门工作论文 (24-013)。Eloundou, T.、Manning, S.、Mishkin, P. 和 Rock, D. (2023)。Gpts 就是 Gpts:大型语言模型对劳动力市场影响潜力的初步研究。arXiv。arXiv:2303.10130。 Eriksson, T.、Bigi, A. 和 Bonera, M. (2020)。和我一起思考,还是替我思考?人工智能在营销战略制定中的未来作用。《全面质量管理杂志》,32 (4),795 – 814。Fish, KE 和 Ruby, P. (2009)。一种针对小型企业的人工智能国外市场筛选方法。国际创业杂志,13,65 – 81。Fornes, G., & Altamira, M. (2023)。人工智能与国际商务。在数字化、技术和全球商业方面。Palgrave Pivot。https://doi.org/10.1007/978-3-031-33111-4_5 Gellweiler, C., & Krishnamurthi, L. (2020)。数字创新者如何实现客户价值。理论与应用电子商务研究杂志,15 (1),1 – 8。Glikson, E., & Woolley, AW (2020)。人类对人工智能的信任:实证研究回顾。 Academy of Management Annals,14 (2),627 – 660。https://doi.org/10.5465/annals.2018.0057 Grant, R., & Phene, A. (2022)。基于知识的观点和全球战略:过去的影响和未来的潜力。全球战略杂志,12 (1),3 – 30。https://doi.org/10.1002/gsj.1399

研究声明
是一个障碍。我们已经开发了许多具有概率正确性保证的不确定性量化技术。典型的不确定性定量技术使I.I.D.假设训练和测试分布是相同的(或密切相关的交换性假设);因此,我们还设计了用于检测和减轻分配转移影响的技术。最后,我们设计了受到离线增强学习技术启发的算法,该算法可以从大规模批处理数据中以安全的方式进行学习,而无需与环境进行潜在危险的互动。神经词系统的保形预测。共构预测是通过将基本模型改为输出标签而不是单个标签的统计量来量化预测不确定性的技术的集合[1]。这些算法具有覆盖范围的范围,尤其是在假设训练和测试分布相同的假设下,预测集可以保证包含具有很高概率的地面真相标签。用于建立值得信赖的神经符号程序,与更传统的不确定性量化技术相比,共形预测具有多个优势,这些技术预测了每个标签的概率(例如,校准预测)。首先,与概率相比,预测集往往更容易纳入存在的软件(例如,传统的机器人计划算法可以避免障碍的预测集,而在概率预测下的计划需要修改计划算法)。此外,覆盖范围保证通常直接转化为整个系统的安全保证(例如,可以保证机器人避免具有很高概率的障碍),而为预测概率提供的保证是易于解释的。我们最近的工作已经证明了如何使用学习理论的技术来设计可能带有近似正确(PAC)瓜素的共形算法[2]。我们的工作也是第一个证明了如何将保形预测应用于包括Resnet [3]在内的深神经网络,随后在结合形式预测和深度学习方面有很大一部分[4,5]。在后续工作中,我们已经证明了共形预测提供的覆盖范围保证是如何用于为更广泛的神经成像计划提供概率保证。例如,我们将其与模型预测性屏蔽结合在一起 - 我们在先前的工作中开发的安全强化学习算法[6,7,8]),以使从视觉观察结果获得安全的加强学习,其中强化学习代理使用DNN策略直接映射图像[9]。在另一项工作中,我们展示了如何为大型语言模型构建共形预测集,并构成它们以提供概率保证,以检索增强问题回答[10]。最后,在正在进行的工作中,我们通过使用抽象解释来通过程序传播预测集[11],致力于将这些技术扩展到一般程序组成。分布偏移下的不确定性定量。如果可以区分它们,则不确定性量化的传统算法,包括共形和校准预测,在很大程度上取决于I.I.D.训练和测试分布是相同的(或稍弱的交换性假设)。 在许多现实世界中,这些假设分解了 - 例如,在不断变化的环境中运行的机器人或部署在患者人群不同的新医院中的机器学习模型。 因此,除了量化I.I.D.下的不确定性外 假设,我们需要检测该假设何时失败。 我们考虑了无监督的域适应设置(即,我们从移位的测试分布中使用了未标记的示例),这在许多设置中都存在,因为系统可以观察到所需的预测输出的输入。 然后,我们建议使用基于分类器的测试来检测协变量分布的变化[12]。 直观地,想法是训练DNN以区分培训和测试输入。训练和测试分布是相同的(或稍弱的交换性假设)。在许多现实世界中,这些假设分解了 - 例如,在不断变化的环境中运行的机器人或部署在患者人群不同的新医院中的机器学习模型。因此,除了量化I.I.D.下的不确定性外假设,我们需要检测该假设何时失败。我们考虑了无监督的域适应设置(即,我们从移位的测试分布中使用了未标记的示例),这在许多设置中都存在,因为系统可以观察到所需的预测输出的输入。然后,我们建议使用基于分类器的测试来检测协变量分布的变化[12]。直观地,想法是训练DNN以区分培训和测试输入。