XiaoMi-AI文件搜索系统
World File Search System拉语

2023年8月5日,Harbin,Chin CCL教程摘要...
近 年 来 , 预 训 练 语 言 模 型 已 逐 渐 成 为 自 然 语 言 处 理 领 域 的 基 座 模 型 。 相 关 实 验 现 象 表 明 , 预 训 练 语 言 模 型 能 够 自 发 地 从 预 训 练 语 料 中 学 到 一 定 的 语 言 学 知 识 、 世 界 知 识 和 常 识 知 识 , 从 而 在 知 识 密 集 型 任 务 上 获 得 出 色 的 表 现 ( AlKhamissi et al., 2022 ; Safavi and Koutra, 2021 ; Petroni et al., 2019 ) 。 然 而 , 预 训 练 语 言 模 型 中 的 知 识 隐 式 地 存 储 在 参 数 之中 , 难 以 显 式 地 对 预 训 练 语 言 模 型 中 的 知 识 进 行 分 析 和 利 用 。 同 时 , 预 训 练 语 言 模 型在 知 识 和 推 理 上 的 表 现 并 不 可 靠 , 常常 会 出 现 “ 幻 觉 ” 现 象 ( Ji et al., 2022 ) , 给 出 与 知 识 冲 突 的 预 测 结 果 。 这 些 因 素 阻 碍 了 预 训 练 语 言 模 型 提 供 可 靠 的 知 识 服 务 。 因 此 , 探 究 模 型 掌握 知 识 的 机 理 、 研 究 如 何 提 取 和 补 充 语 言 模 型 中 的 知 识 成 为 近 期 的 研 究 热点 。 本 次 讲 习 班 主 要 内 容 包 括 预 训 练 语 言 模 型 中 的 知 识 分 析 、 预 训 练 语 言 模 型 的 知 识 萃 取 、 知 识 增 强 的 预 训 练 语 言 模 型 三个 部 分 , 听 众 将 在 本 次 讲 习 班 中了 解 到 近 期 研 究 中 对 预 训 练 语 言 模 型 掌握 知 识 情 况 的 认识 、 从 预 训 练 语 言 模 型 中 提 取 符 号 知 识 的 实 现 方 案 、 利 用 外 部 知 识 增 强 模 型 弥 补 缺 陷 的 各 类 方 法 。

语言和经济
本卷包含 2019 年 10 月 9 日至 11 日在爱沙尼亚塔林举行的第 17 届 EFNIL 年会上的演讲。此次会议由爱沙尼亚语言学院、爱沙尼亚语言理事会、教育和研究部、塔林市政府、母语学会和欧盟委员会翻译总司 (DGT) 和 EFNIL 合作举办。在会议上提交的论文中,以不同的方式强调了“语言与经济”这一主题。本卷的第一篇文章基于会议上的主旨演讲,从一种或多种语言的经济权重的角度来理解语言的经济权重问题。本文主要从英语在世界范围内的重要性来讨论语言的经济权重问题。尽管经济效益与语言使用之间的联系的考虑构成了本书第一部分的基调,但它们与对经济(即有效和适当)语言使用及其与经济因素关系的思考相关。本书第一章中的论文讨论了如何将经济学家的观点系统地融入语言论述中,以及如何在现代欧洲社会中有效利用人力资本“语言”,以及在日益发展的语言产业领域中产生的实际影响。会议副标题中讨论的最后一个方面,即语言产业,指的是多语言互动的实际挑战,并提出了相当多的具体问题。管理多语言结构最明显的后果之一是专业翻译和口译的必要性,本书第二章将讨论这个问题。解决这些问题的问题——例如在欧盟机构中——无疑具有经济方面;这样的解决方案提供了经济机会,是成本效益计算的对象。下一部分是关于在多语言环境中掌握和使用多种语言的好处(以及某些语言技能的局限性)。文章举例说明了多种语言是否以及在何处使用有效且具有经济优势。在关于简单语言作为另一种经济交流方式的论文中,讨论了近年来越来越明显的一个方面。使用简单语言可以减少误解,这一事实也产生了经济效益。本节中的论文展示了经济问题和包容性和多样性的民主概念如何重叠。


乌尔都语词汇
本书是我在加州大学圣克鲁斯分校开始学习阿拉伯语、印地语-乌尔都语、波斯语和梵语 16 年的成果,之后我在美国印度研究所、德里大学和德克萨斯大学奥斯汀分校继续学习。我的第一位印地语-乌尔都语老师约翰·莫克 (John Mock) 一直是我的主要灵感来源。我同样感谢美国乌尔都语研究所勒克瑙分校项目的所有老师,感谢他们的耐心,感谢他们带我进入乌尔都语文学的世界。我特别感谢与 Fahmida Bano、Wafadar Husain、Ahtesham Khan 和 Sheba Iftikhar 一起讨论乌尔都语单词的大量时间。在威斯康星大学麦迪逊分校,我有幸协助和观察已故的 Qamar Jalil,他的教学见解反映在本书中。在德克萨斯大学奥斯汀分校,我有幸与世界上一些最伟大的语言和文学教师一起学习。 Syed Akbar Hyder 为我提供了广泛而严格的乌尔都语文学指导。Michael Hillmann 花费数年时间训练我精通波斯语。本书阿拉伯语和波斯语单元中的许多想法和见解都直接源自他的指导。我还要感谢 Rupert Snell,我跟随他学习印地语八年,他让我领略了印地语-乌尔都语词汇的诸多乐趣以及应用语言文学的知识回报。本书也是我在加州大学伯克利分校、德克萨斯大学奥斯汀分校和威斯康星大学麦迪逊分校教授乌尔都语十一年的成果。我最初于 2008 年在威斯康星大学麦迪逊分校的南亚暑期语言学院构思了这个项目,并从与学生和同事的交谈中受益匪浅,包括 Qamar Jalil 和 Faraz Sheikh。我在德克萨斯大学奥斯汀分校的印地语-乌尔都语旗舰课程任教期间开发了这些单元的基本结构和许多课程的初稿。多年来,我在那里教过许多才华横溢的学生,但我特别感谢 Ayana D'Aguilar 和 Courtney Naquin 的反馈,他们在我研究生最后一年与我一起完成了许多练习的初稿。过去四年,我一直在加州大学伯克利分校开发和教授这些材料。他们的反馈启发了我进行无数轮的修改。特别感谢以下学生,他们在本书准备出版的最后阶段参与了本书的大部分工作:Hammad Afzal、Khudeeja Ahmed、Hammad Ali、Aparajita Das、Elizabeth Gobbo、Salil Goyal、Shazreh Hassan、Caylee Hong、Zain Hussain、Talib Jabbar、Maryam Khan、Adeel Pervez、Omar Qashoa、Adnan Rawan、Ahmad Rashid Salim、Nawal Seedat 和 Fatima Tariq。还要特别感谢 Sally Goldman 对梵文单元的有益反馈和建议,以及我的朋友和同事 Walter Hakala 在修订后期对这些单元的精辟评论。他们的反馈大大提高了本书的质量。当然,所有错误和疏忽都是我一个人的错。



人工智能设备和印地语
Error 500 (Server Error)!!1500.That’s an error.There was an error. Please try again later.That’s all we know.

匈牙利语和罗马尼亚语的比较...
欧盟和 PESCO 采用了各自的国家安全战略。上述两个国家都需要新的国防战略,因为近年来出现了新的挑战和威胁,如吞并克里米亚、乌克兰局势动荡以及移民危机。这些文件描述了两国在国际体系中的地位,列出了对其安全的威胁和挑战,并最终根据其可能性和能力尝试给出解决方案。这些战略还向邻国、盟友和未来的竞争对手传达了信息。该文件的目的是保护核心国家价值观。在本文中,我的目标是概述战略文件,并首先分析罗马尼亚国防战略。匈牙利国家安全战略,最后强调相似之处并找出不同之处,如国家主权、保护基督教价值观或欧洲军队的重要性。两份安全文件中都出现了新旧威胁,如恐怖主义、气候变化、移民问题、混合战争、武器和贩毒。每项战略都是官方沟通工具,是向影响国家安全的不同层次和不同类型的外部和内部行为者发出的官方政策信息。为了实现我的目标,我使用了文档分析和内容分析的方法对主要来源进行分析。研究的目的是比较两个邻国的战略,以及它们如何应对国家威胁。

ALS426:语言和语言学
本课程是对语言和语言学研究的介绍。它向学生介绍了语言和语言学的基本概念,原则和理论。它提供了一些背景信息,有关语言的起源,动物和人类语言之间的差异,语言获取/学习和语言学重要,其中包括语音,语音学,形态学,语法,语义,语义,语用学。它还教会学生根据电影/报告/纪录片分析某些语言问题,并撰写有关与语言有关的问题的项目论文。
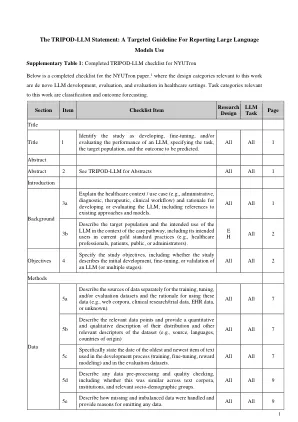
报告大语的目标指南...
llm =大语言模型; M = LLM方法; d = de novo llm开发; E = LLM评估; H =医疗保健设置中的LLM评估; C =分类; =结果预测; QA =长形式提问; ir =信息检索; DG =文档生成; SS =摘要和简化; MT =机器翻译; EHR =电子健康记录。