XiaoMi-AI文件搜索系统
World File Search System推荐人
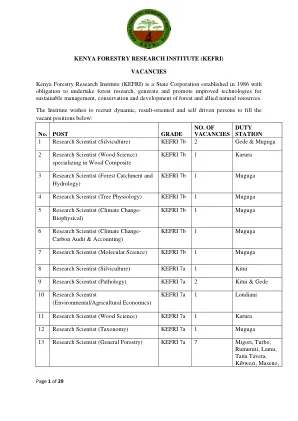
肯尼亚林业研究所(kefri)
除在线申请外,申请人还应发送纸质申请表,并附上个人简历、相关专业/学术证书和国民身份证的复印件。他们还应提供白天和晚上的电话号码、电子邮件地址以及三名推荐人的姓名和地址,以便在 2021 年 12 月 6 日星期一之前联系 KEFRI 主任。


报价请求(“rfq”)- EWSeta
推荐信是之前成功开展技能发展干预相关项目管理服务的证据。所做的工作必须包括项目启动、监控、报告和财务管理。(注意:推荐信不得超过 5 年前,以之前服务过的客户为抬头,并且至少应反映客户姓名、项目描述、开展年份、完成年份、可联系的推荐人姓名和联系方式)

2025年研究生招生简章
指导老师/推荐人必须在学生完成学业之前提前通过系主任申请由院务委员会任命的外部考官。学生完成学位论文并且指导老师/推荐人认为可以提交考试后,指导老师会向学生发出信函,允许学生提交表明提交意向的表格。候选人应在计划提交手稿供审查的至少三个月前,并且不迟于计划毕业典礼前一年的 9 月 30 日,通过指导老师向系主任提交一份表明提交手稿供审查的意向的表格,以及不超过 500 字的手稿内容的英文描述(摘要)。系主任应将表格和摘要提交给院长。最后,学位论文将通过院长提交给考试办公室,然后考试官员负责将学位论文按照院务委员会的批准发送给外部考官。考试官收到考官的报告后,会联系院长,召开考试委员会会议。在任何情况下,考官的报告在送达考试委员会之前都不得让任何人知晓。

被告人的付款计划申请
被告同意并理解,上述标准付款计划已提供,并可按上述增量每月支付至少 100 美元。如果被告无法满足规定的付款协议条款,则可出庭。除非被告未能按照本计划成功付款,否则法院不会联系推荐人。被告理解,应在本判决后的第 31 天支付并收取额外的 25.00 美元付款费。

生成探索 - 开发:使用LLM优化器对生成推荐系统进行无培训优化
推荐系统被广泛用于吸引参与内容,大型语言模型(LLMS)引起了生成推荐人。这样的系统可以直接构成项目,包括用于诸如问题建议之类的开放设定任务。虽然LLMS的世界知识启动了好的建议,但是通过用户反馈改善生成的内容却是一项挑战,因为持续细微的LLM持续昂贵。我们提出了一种无培训方法,可以通过将用户反馈循环与基于LLM的优化器连接起来来优化生成推荐人。我们提出了一种生成探索探索方法,该方法不仅可以利用具有已知高参与度的生成的项目,而且可以积极地探索并发现隐藏的人群偏爱以提高建议质量。我们在两个域(电子商务和一般知识)中评估了问题生成的方法,并使用单击“速率”(CTR)对用户反馈进行了模型。实验表明,我们基于LLM的探索探索方法可以依靠地提高建议,并同意增加CTR。消融分析表明,生成探索是学习用户偏好的关键,避免了贪婪的仅剥削方法的陷阱。人类评估强烈支持我们的定量发现。

2024 年 1 月
1955 年《基本商品法》。自 2010 年 4 月 1 日起生效。旨在为每公斤营养素的肥料提供补贴。NBS 下符合条件的主要营养素:氮 (N)、磷酸盐 (P)、钾 (K) 和硫 (S)。推荐人:部长级委员会 (IMC),秘书 (肥料) 担任主席。肥料公司必须将 MRP 连同适用的补贴一起印在肥料袋上。
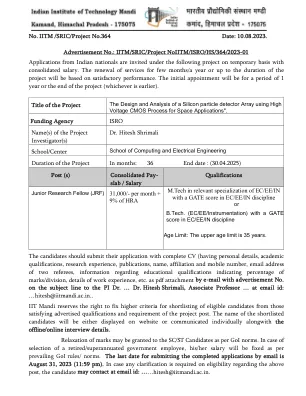
IITM/SRIC/项目编号IITM/ISRO/HS/364/2023-01
候选人应将完整的简历(包含个人详细信息、学历、研究经历、出版物、姓名、所属机构和手机号码、两名推荐人的电子邮件地址、有关教育资格的信息(表明分数/部门百分比)、工作经验详情等)作为 pdf 附件通过电子邮件发送申请,并在主题行中注明广告编号,发送给 PI Dr. ... Dr. Hitesh Shrimali,副教授... 电子邮件 ID:...hitesh@iitmandi.ac.in。

生成AI驱动的语义通信网络
强化学习(RL)的推荐系统在基于会话和序列的推荐任务中表现出了有希望的性能。现有的基于RL RL的顺序推荐方法面临的挑战是从环境中获得有效的用户反馈。为用户状态开发模型并为推荐提供适当的奖励仍然是一个挑战。在本文中,我们利用语言理解能力并将大型语言模型(LLMS)作为环境(LE)来增强基于RL的推荐人。LE是从用户项目交互数据的子集中汲取的,从而重新提出了对大型培训数据的需求,并且可以通过以下方式综合用户反馈以:(i)充当一个状态模型,以实现高质量的状态,从而使用户表示丰富的高质量状态以及(ii)作为奖励模型的准确捕获NUChice用户的奖励模型。此外,LE允许我们发电以增强有限的离线培训数据的积极行动。我们使用增强动作和历史用户信号,通过共同优化监督组件和RL策略来进一步提高建议性能,以进一步提高建议性能。我们将LEA,状态和奖励模型与最先进的RL推荐人结合使用,并在两个公开可用的数据集上报告实验结果1。

使用反事实机器人
近年来,对在线平台的批评提出了人们对推荐算法扩大有问题内容的能力的担忧,并具有潜在的激进后果。但是,试图评估推荐人的效果的尝试遭受了缺乏适当的反事实的困扰 - 在没有算法建议的情况下,用户会看待的是什么,因此无法将算法的影响从用户的意图中解散。在这里,我们提出了一种我们称为“反事实机器人”的方法,以估计算法建议在YouTube上摄入高度党派内容的作用。通过比较将真实用户的消费模式与遵循基于规则的轨迹的“反事实”机器人进行比较,我们表明,平均而言,仅依靠YouTube推荐人会导致党派消费较少,在这种情况下,这种效果最为明显。按照类似的方法,我们还表明,如果党派消费者切换到中等内容,YouTube的侧边栏建议在大约30个视频中“忘记”他们的党派偏好,而不论其先前的历史记录如何,而主页建议则更逐渐地转向中等内容。总的来说,我们的发现表明,至少自YouTube在2019年实施的算法变化以来,个人消费模式主要反映了个体偏好,算法建议在其中扮演的角色(如果有的话)是一个调节角色。