XiaoMi-AI文件搜索系统
World File Search System描述符

遗传相似性与遗传祖先作为人类遗传学样本描述符
样本标签研究人员选择适用于下游分析的人类基因组数据形状以及其他人如何解释结果。一些样本标签,例如种族或种族,以模棱两可和不一致的方式应用(Panofsky和Bliss,2017年; Popejoy等人。,2020年; BYEON等人。,2021)。今天,样本描述符通常还包括对样品基因组数据分析的标签。研究人员使用的一个常见的遗传样本描述是“遗传血统群体”:例如,将生活在美国的个体标记为具有“欧洲遗传血统”或“非洲遗传血统”。由于这些标签是基于统计方法,因此它们似乎比根据社会分组分配的标签要少。但是,使用流行基因组学方法来分配人群描述符,其自身相交的挑战。的确,遗传血统标签显然是混乱的根源,范围和遗传标签之间的滑倒与社会标签之间的底漆(参见Mathieson和Scally,2020年; Lewis等; Lewis等,2022年,最近呼吁对我们的遗传血统的含义更加准确。从这个角度来看,我认为人类遗传学的领域应远离使用遗传血统作为样本描述符。这样的术语是不精确的且潜在的误导性,并且对于大多数应用,研究人员都使用它们来指示与某些预定的样本集的遗传相似性或相关性。许多在大多数应用中,人类遗传学家实际上与控制遗传相似性,地理和环境的比较有关,而不是祖先人群的某些模糊概念。
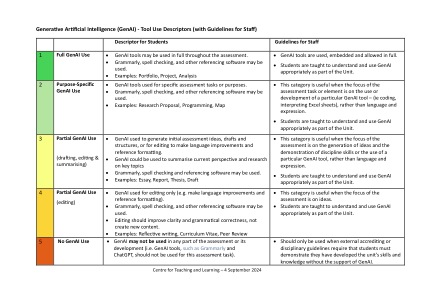
生成人工智能 (GenAI) - 工具使用描述符(附员工指南)
GenAI 用于生成初步评估想法、草稿和结构,或用于编辑以改进语言和参考格式。 GenAI 可用于总结当前对关键主题的观点和研究 可以使用 Grammarly、拼写检查和引用软件。 示例:论文、报告、论文、草稿

基于新型特征描述符和特征选择技术预测谷氨酸棒状杆菌启动子
启动子是重要的非编码DNA调控元件,与RNA聚合酶结合激活下游基因的表达。工业上人工精氨酸主要由谷氨酸棒杆菌合成,特定启动子区域的复制可增加精氨酸的产量,因此需要对谷氨酸棒杆菌中的启动子进行准确定位。在湿实验中,启动子的识别依赖于sigma因子和DNA剪接技术,这是一项费力的工作。为了快速方便地识别谷氨酸棒杆菌中的启动子,我们发展了一种基于新型特征表示和特征选择的方法来完成这项任务,通过多种理化性质的统计参数描述DNA序列,结合方差分析和层次聚类过滤冗余特征,其预测准确率高达91.6%,灵敏度91.9%可以有效识别启动子,特异性91.2%可以准确识别非启动子。此外,我们的模型可以在400个独立样本中正确识别181个启动子和174个非启动子,证明了所开发的预测模型具有良好的稳健性。

受阻表面态作为预测无机晶体材料催化活性位点的描述符
设计高活性催化剂的关键是确定活性的来源。然而,这仍然是一个挑战。[8,9] 特定催化剂的活性传统上与其表面性质有关。因此,具有大表面积、良好导电性和高迁移率的材料被认为是良好的催化剂,因为它们具有丰富的活性位点,有利于氧化还原反应中中间体的吸附和电子转移。这是广泛使用的催化剂合成策略的动机,例如纳米结构化、掺杂、合金化或添加缺陷。每种方法都旨在暴露优先晶体表面或对其进行工程改造以提高其活性。[10–12] 然而,从设计的角度快速准确地确定活性位点的位置仍然是一项艰巨的任务,这使得从许多潜在的有趣材料中发现高性能催化剂成为一项挑战。拓扑材料具有稳健的表面态和高迁移率的无质量电子。 [13–15] 此外,无论是从理论还是实验角度,许多最先进的催化剂(如 Pt、Pd、Cu、Au、IrO 2 和 RuO 2 )都被认为具有拓扑衍生的表面态 (TSS)。[16,17] 因此,有证据表明 TSS 在催化反应中发挥着重要作用。[18,19] 此类状态主要由

一种统一的方法和描述符,用于二维过渡金属二分法单层的热膨胀
我们介绍了使用各种实现技术和语言构建的裸机服务器的验证,该技术根据机器代码,网络数据包和椭圆形曲线密码学的数学规范来针对全系统输入输出规范。我们在整个堆栈中使用了非常不同的形式性技术,范围从计算机代数,符号执行和验证条件生成到对功能程序的交互式验证,包括用于C类和功能性语言的编译器。所有这些组件规格和特定于领域的推理技术都是针对COQ证明助手中常见的基础定义和合理的。连接这些组件是一种基于功能程序和简单对象的断言,无所不知的程序执行和基本分离逻辑,用于内存布局。此设计使我们能够将组件以最高级别的正确性定理汇总在一起,而无需理解或信任内部接口和工具而可以进行审核。我们的案例研究是一款简单的加密服务器,用于通过公开验证的网络消息翻转一些状态,其证明显示了总功能正确性,包括内存使用方面的静态界限。本文还描述了我们使用的特定验证工具的经验,以及对我们经历的工具和任务组合之间经历的生产力差异的原因的详细分析。


使用多模态 MRI 的放射纹理特征描述符来区分复发性脑肿瘤与放射性坏死
尽管采取了化学放射疗法和手术切除等多模式积极治疗,多形性胶质母细胞瘤 (GBM) 仍有可能复发,这被称为复发性脑肿瘤 (rBT)。在多种情况下,良性和恶性病变在放射影像上可能看起来非常相似。其中一个例子就是放射性坏死 (RN)(放射治疗的中度良性影响),在结构磁共振成像 (MRI) 上,它们在视觉上几乎与 rBT 无法区分。因此,需要在常规获取的脑部 MRI 扫描中识别可靠的非侵入性定量测量:对比前 T1 加权 (T1)、对比后 T1 加权 (T1Gd)、T2 加权 (T2) 和 T2 液体衰减反转恢复 (FLAIR),可以准确区分 rBT 和 RN。在这项工作中,复杂的放射纹理特征用于在多模式 MRI 上区分 rBT 和 RN,以进行疾病表征。首先,提取随机多分辨率放射组学描述符,该描述符可捕获体素级纹理和结构异质性以及强度和直方图特征。随后,这些特征用于机器学习设置,以从四个 MRI 序列(包含 30 个 GBM 病例(12 个 RN,18 个 rBT)的 155 个成像切片)中表征来自 RN 的 rBT。为了减少准确度估计的偏差,我们使用留一交叉验证 (LOOCV) 和分层 5 倍交叉验证与随机森林分类器来实现模型。在本研究中,我们的模型使用多分辨率纹理特征区分 rBT 与 RN,对于 LOOCV 提供 0.967 ± 0.180 的平均准确度,对于分层 5 倍交叉验证提供 0.933 ± 0.082 的平均准确度。我们的研究结果表明,与文献中的其他研究相比,复杂的纹理特征可以更好地区分 MRI 中的 rBT 和 RN。关键词:复发性脑肿瘤,放射性坏死,放射组学特征,多模态磁共振成像

铝制硅酸盐眼镜的结晶行为:从结构描述符到定量结构 - 基于财产关系(QSPR)的预测模型
成功地解码了控制多组分功能玻璃中结晶的结构描述符,可以为从试用方法和玻璃/玻璃陶瓷组成设计的过渡和经验建模铺平道路,从而朝着更合理和科学严格的定量结构 - 结构 - 实用关系(QSPR)模型。然而,由于多组分玻璃的组成和结构复杂性以及与成核相关的时间和长度尺度的较长,QSPR模型的发展和验证仍在其婴儿期。本文中提出的工作是通过结合实验和计算材料科学的优势来解码化学结构驱动因素,以促进或抑制碱/碱性 - 碱性 - 钙化型Alu Minoborosilicate在基于QSPR模型的开发中,促进或抑制成核和晶体的增长的化学结构驱动因素,从而促进或抑制核的成核和晶体生长,从而使基于基于QSPR模型的开发(PAWER M.DAWAID)促进成核和晶体生长。结果揭示了以下两个描述符,这些描述符在功能玻璃中特定的铝硅酸盐相位的成核和结晶:(1)SIO 4和ALO 4单元之间的混合程度,即Si - O - a-o - al链接,以及(2)(2)在玻璃结构中的镜头阶段之间的差异(2)差异。基于已建立的组成 - 结构 - 结晶行为关系,基于聚类分析的QSPR模型已经开发(并进行了测试),以预测所研究玻璃中尼索线(和氧化足)结晶的倾向。该模型已经在目前和以前的研究中对几个组成进行了测试,并成功预测了所有玻璃成分的结晶倾向,即使在先前的经验和半经验模型失败的情况下,即使是在此情况下。


超高性能色谱中多环化合物的定量结构 - 保留关系分析
摘要:进行了比较定量结构 - 保留关系(QSRR)研究,以预测使用分子描述符的多环芳烃(PAHS)的保留时间。分子描述符是由软件龙生成的,并用于构建QSRR模型。还考虑了色谱参数的影响,例如流量,温度和梯度时间。使用人工神经网络(ANN)和部分最小二乘回归(PLS-R)来研究保留时间(以响应为响应)和预测因子之间的相关性。通过遗传算法选择了六个描述符,以开发ANN模型:分子量(MW);环描述符类型NCIR和NR10;径向分布功能RDF090U和RDF030M;以及3D-MORSE的描述符MOR07U。PLS-R模型中最重要的描述符是MW,RDF110U,MOR20U,MOR26U和MOR30U;边缘邻接Indice SM09_AEA(DM);基于3D矩阵的描述符spposa_rg;和逍遥布H7U。构建模型用于预测校准集中未包含的三个分析物的保留。考虑到预测集的统计参数RMSE(分别为PLS-R和ANN模型的0.433和0.077),该研究证实了与色谱参数相关的QSRR模型可以通过非线性方法更好地描述。