XiaoMi-AI文件搜索系统
World File Search System收集

机器学习的数据收集和标签技术
1引言机器学习领域(ML)近年来经历了一段空前的增长。这种显着的进步可以归因于两个关键因素:计算能力的指数增长和广泛数据集的不断增加[1-3]。然而,这一进展基础的基础是数据收集和标签 - 提出了重大挑战,可以阻碍ML模型的功效和道德实施[4-8]。本评论论文介绍了复杂的数据收集和标签机器学习的世界,并借鉴了数据管理和机器学习社区的见解。机器学习的变革潜力在许多域中显而易见。从疾病诊断和个性化医学[9]革命性医疗保健[10]和在供应链中优化物流[11]中,ML算法正在迅速重塑我们的世界。这些进步的核心在于ML模型从数据,识别模式学习并根据其暴露的信息进行预测的能力。用于训练这些模型的数据的质量和数量对于它们的成功至关重要。高质量,多样化和标记的数据对于构建可在现实世界中有效性能的强大且可推广的ML模型至关重要[12,13]。但是,收集和标记机器学习数据的过程远非直接。此外,关于数据隐私和数据集中潜在偏见的道德考虑训练复杂模型所需的庞大数据可能令人生畏,并且对每个数据点进行精心标记的任务可能非常耗时且昂贵。

脑疾病研究基础设施数据收集和探索 (BRIDGE) 平台简介
1,100 1. 一天内发布数据 2. 数据包括昂贵且难以获取的 MRI、PET 和遗传学 3. 受试者为阿尔茨海默病和轻度认知障碍 (MCI) 患者以及健康志愿者。 4. AIBL 的研究也是第一个在实验设计中使用计算机化认知评估的研究。 5. 可在 ADNI LONI 网站上免费下载,供全球研究人员使用。 6. 数据协调与共享:AIBL 数据已提供给全球阿尔茨海默病协会互动网络 (GAAIN),并安装了软件,从而使 GAAIN 用户能够查询元数据并接收队列摘要,随后用户可以在需要时通过提交意向书 (EoI) 请求更多信息(以及生物流体样本;血液和脑脊液)。

神经病学诊所中的多模式数字行为表型分析:Neurobooth 平台的开发和前两年的数据收集
定量分析人类行为对于客观描述神经系统表型、早期发现神经退行性疾病以及开发更敏感的疾病进展测量方法以支持临床试验和将新疗法转化为临床实践至关重要。复杂的计算建模可以支持这些目标,但需要大量信息丰富的数据集。这项工作引入了 Neurobooth,这是一个可定制的平台,用于时间同步的多模态人类行为捕获。在两年的时间里,集成到临床环境中的 Neurobooth 实施促进了从 470 名个人(82 名对照者和 388 名患有神经系统疾病的人)的多个行为领域收集数据,这些个人参加了总共 782 次会议。多模态时间序列数据的可视化表明,在一系列疾病中都存在丰富的表型体征。这些数据和开源平台为增进我们对神经系统疾病的理解和促进治疗方法的发展提供了潜力,并且可能是研究人类行为的相关领域的宝贵资源。

带有随机样本大小和部分恢复的标签优惠券收集器问题
I。 [8] - [12]。最近已将其用于DNA中数据存储的组合编码研究[13] - [17]。最初以从统一和独立样本收集不同的优惠券来构建,CCP研究了收集所有不同优惠券所需的样品数量的分布。传统上,CCP涉及n个不同的均衡优惠券,在每个样本中,单个优惠券都会重复。在这种情况下,至少一次对每个优惠券进行采样所需的预期样本数为n·hn≈nlog n,其中h n是n -th谐波数。CCP的变体已出现以建模复杂的现实世界系统。 这样的变体[7]是每个优惠券具有其自己的采样概率p i的位置。 另一种变体是仅重新要求r差异优惠券[18] - [21],而不是所有n张优惠券。 此问题称为部分CCP,在几种情况下进行了探索,特别是用于优化收集过程或估计优惠券亚集的概率。 对于该变体,已知样品的预期数为[19]:n·p r - 1 i = 0 1 n -i = n·(h n -h n -h n -n -r)。 部分恢复也与DNA中数据存储的RAM实现有关[22] - [24]。 我们已出现以建模复杂的现实世界系统。这样的变体[7]是每个优惠券具有其自己的采样概率p i的位置。另一种变体是仅重新要求r差异优惠券[18] - [21],而不是所有n张优惠券。此问题称为部分CCP,在几种情况下进行了探索,特别是用于优化收集过程或估计优惠券亚集的概率。对于该变体,已知样品的预期数为[19]:n·p r - 1 i = 0 1 n -i = n·(h n -h n -h n -n -r)。部分恢复也与DNA中数据存储的RAM实现有关[22] - [24]。我们此问题的另一个概括是带有组图的CCP [25] - [27]。这种概括考虑了场景,在这种情况下,每个样本中没有收集单个优惠券,而是收集优惠券的随机子集。每个样品的大小可能是恒定k或随机变量(RV)k。一个人有兴趣表征所需的子集数量的分布,直到在这些样本中至少有一个优惠券中绘制每个优惠券为止。

托盘处理类似汽车的机器人的自动货运收集的停车姿势生成
摘要:本文着重于用于使用车辆中安装的托盘处理机器人自动收集货运的电动货车的自主导航。除了自动驾驶汽车导航外,车辆自治的主要障碍是货运的自主集合,无论货运方向/位置如何。这项研究重点是为车辆产生停车位,而不论货运以其自主收集而定向。货运方向是通过通过板载传感器捕获货运来计算的。之后,此信息使用数学方程式以及对车辆和货运收集限制的知识创建停车位。根据装载舱的可用性,生成了单独的停车位,用于车辆的单独装载湾。最后,将结果捕获和验证,以确定货运的不同方向以结束研究。

针对 AEFI 收集的数据元素
1. 支持区域、省级和(如有必要)国家级的信号检测和触发调查。 2. 识别不常见、罕见和严重或不寻常的不良事件以供审查,包括以前未识别的事件。 3. 审查事件并向经历过 AEFI 的疫苗接种者提供建议,以进一步调查(如适用)并进行未来的疫苗接种。 4. 确保在 BC 观察到的 AEFI 符合基于临床试验数据和其他司法管辖区上市后使用的预期情况,并能够告知疫苗接种者在 BC 使用的产品的疫苗安全性。 5. 参与国家和国际疫苗安全监测,以告知在加拿大销售的疫苗的安全性。 6. 保持公众对疫苗安全性的信心。要报告的数据元素(即最低数据集)

MSD收集详细信息手册
成人教育参与者 - 在学校人口统计学成分中,在“ 20年级”(成人教育)的“ 20年级”(成人教育)中报告了学生。早期的童年参与者 - 在学校人口统计组成部分中,学生的年级或设定特征是“ 30年级”(幼儿)的报告。这包括参加幼儿特殊教育计划或服务或服务早期的残疾儿童。非公开学生 - 在成员组成部分的学生居住特征中,该学生用“ 04”(非居民非公立学校学生)或“ 08”(居民非公立学校学生)报告了该学生。家庭教育的学生 - 在会员部分中,学生居住特征中有“ 07”(家庭教育的非居民)或“ 15”(家庭学校居民)的代码报告。在本学年开始之前离开学区的学生 - 报告学生的当前学年9月1日的地区退出日期。
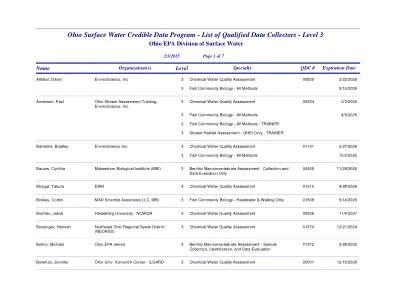
合格的数据收集器列表 - 级别3
Miller,Michael 3 Chemical Water质量评估U.辛辛那提部的生物科学,Rivers,Rivers Unlimited,Green Umbrella Cinci Streambank,Oxbow Inc,Mill Creek Patershed Council

核心收集和开发核心收集的方法
P.O. Box 2003,埃塞俄比亚的亚的斯亚贝巴摘要农业的特征是由于人类和自然事件而导致栽培植物的多样性急剧下降。 植物育种通过扩展遗传均质品种和促进少数广泛适应的品种而导致农作物多样性的减少。 种质收集的大小经常限制对它们的访问,因此它们在植物育种和研究中的使用。 因此,如果选择有限数量的遗传多样化的加入作为核心收集,则可以增强种质收集的管理和使用。 因此,本文旨在审查核心收集建立的方式及其在育种计划中的影响。 核心收集是大型种质收集的子集,该子集涉及选择代表收集遗传多样性的加入。 核心收集的目标是改善种质收集的使用和管理。 创建核心收集是具有挑战性的,并且可以花费时间来进行时间,并且可以为任何种质收集而完成。 通常,将配件分组,并在这些分组内部/内部进行选择以创建核心收集。 创建核心集合的基本过程可以分为四个步骤,其中包括域的定义,组中的划分,条目分配和登录选择。 核心集合提供了可管理的样本量,该样本大小是结构化的,并且比整个集合都小。P.O.Box 2003,埃塞俄比亚的亚的斯亚贝巴摘要农业的特征是由于人类和自然事件而导致栽培植物的多样性急剧下降。植物育种通过扩展遗传均质品种和促进少数广泛适应的品种而导致农作物多样性的减少。种质收集的大小经常限制对它们的访问,因此它们在植物育种和研究中的使用。因此,如果选择有限数量的遗传多样化的加入作为核心收集,则可以增强种质收集的管理和使用。本文旨在审查核心收集建立的方式及其在育种计划中的影响。核心收集是大型种质收集的子集,该子集涉及选择代表收集遗传多样性的加入。核心收集的目标是改善种质收集的使用和管理。创建核心收集是具有挑战性的,并且可以花费时间来进行时间,并且可以为任何种质收集而完成。通常,将配件分组,并在这些分组内部/内部进行选择以创建核心收集。创建核心集合的基本过程可以分为四个步骤,其中包括域的定义,组中的划分,条目分配和登录选择。核心集合提供了可管理的样本量,该样本大小是结构化的,并且比整个集合都小。通常,通过简化在基因库运营,基础研究和教育中的种质使用来改善作物的核心收集至关重要。关键词:核心收集,种质,种质收集,遗传资源,遗传多样性。

能量收集材料的发展路线图
Vincenzo Pecunia 1* , S. Ravi P. Silva 2* , Jamie D. Phillips 3 , Elisa Artegiani 4 , Alessandro Romeo 4 , Hongjae Shim 5 , Jongsung Park 6 , Jin Hyeok Kim 7 , Jae Sung Yun 8 , Gregory C. Bryon , Larson Bryon 19 rank 11 , Audrey Laventure 11 , Kezia Sasitharan 12 , Natalie Flores-Diaz 12 , Marina Freitag 12 , Jie Xu 13 , Thomas M. Brown 13 , Benxuan Li 14 , Yiwen Wang 15 , Zhe Li 16 , Bo Hou 17 , Behma and Emmay Emmay 18 . 20 , Veronika Kovacova 20 , Sebastjan Glinsek 20 , Sohini Kar-Narayan 21* , Yang Bai 22 , Da Bin Kim 23 , Yong Soo Cho 23 , Agnė Žukauskaitė 24 , Stephan Barth 24 , 25 Feng , Wenzhu , Costa Wenzhu , 26 28 , Javier del Campo 29,30 , Senentxu Lanceros-Mendez (27-30) , Hamideh Khanbareh 31 , Zhong Lin Wang 32 , Xiong Pu 33 , Caofeng Pan 33 , Renyun Zhang 34 , Jing Xu 35 , Xun Zhao 35 , Zhou Zhou 35 , Trinny Tat 35 , Il Woo Ock 35 , Jun Chen 35 , Sontyana Adonijah Graham 36 , Jae Su Yu 36 , Ling-Zhi Huang 37 , Dan-Dan Li 37 , Ming-Guo Ma 37 , JiKui Luo 38 , Feng Jiang 39 , Duol Lee , Duol 39 kateswaran Vivekananthan 2 , Mercouri G. Kanatzidis 40 , Hongyao Xie 40 , Xiao-Lei Shi 41 , Zhi-Gang Chen 41 , Alexander Riss 42 , Michael Parzer 42 , Fabian Garmroudi 42 , Ernst Bauer 42 , Madison Zali 43 , Madison 33 . , Muath Al Malki 43 , G. Jeffrey Snyder 43 , Kirill Kovnir 44,45 , Susan M. Kauzlarich 46 , Ctirad Uher 47 , Jinle Lan 48 , Yuan-Hua Lin 49 , Luis Fonseca 50 , Alex Morata 51 , Mariz Guillov , 53 David Berthebaud 54 , Takao Mori 55,56 , Robert J. Quinn 57 , Jan-Willem G. Bos 57 , Christophe Candolfi 58 , Patrick Gougeon 59 , Philippe Gall 59 , Bertrand Lenoir 58 , Deepak Venkatesh , Zhao Zhanner 266 , Gang Zhang 63 , Yoshiyuki Nonoguchi 64 , Bob C. Schroeder 65 , Emiliano Bilotti 66 , Akanksha K. Menon 67 , Jeffrey J. Urban 68 , Oliver Fenwick 66 , Ceyla Asker 66 , A. Alec Talin 69 , Ansi D. Thomas 177 . , Fabrizio Viola 71 , Mario Caironi 71 , Dimitra G. Georgiadou 72 , Li Ding 73 , Lian-Mao Peng 73 , Zhenxing Wang 74 , Muh-Dey Wei 75 , Renato Negra 75 , Max C. Lemme 74 , Mahmoud Bey 77 , Tao Beby , 277 feeq Ibn-Mohammed 78 , KB Mustapha 79 and AP Joshi 78