XiaoMi-AI文件搜索系统
World File Search System数据保护

适用于 AI 应用程序的 Dell 数据保护
AI 模型依赖于用于模型训练的数据,这最终决定了模型的准确性和整体实用性。为了创建符合其个人需求的强大 AI 应用程序,组织将利用自己的私有数据来训练或微调模型,这些数据通常来自许多不同的数据源。IT 组织应该了解哪些数据源被用于训练他们的 AI 模型,并验证这些数据源是否具有备份和恢复策略,以确保训练过程中的数据可用性。在考虑组织的现有数据时,重要的是检查现有的数据保护策略是否满足 AI 模型训练的恢复点目标([RPO] 或可以容忍的数据丢失量)和恢复时间目标([RTO] 或恢复所需的时间长度)所需的服务级别。

人工智能对数据保护和隐私的影响简介
人工智能 (AI) 是指能够执行过去只有人类才能完成的复杂任务(如推理、决策或解决问题)的计算机系统 1 ,它有可能影响社会的各个方面。如今,人工智能在非洲的数字化进程中发挥着关键作用,包括那些正在建设所谓“智慧城市”的国家。2 然而,非洲还没有关于人工智能的具体法律。埃及、加纳、肯尼亚、毛里求斯和卢旺达等国现有的努力仅仅是政策或战略计划。3 尽管如此,数据保护立法条款(例如禁止自动决策的条款)与人工智能的使用有关。因此,重要的是探讨人工智能对数据保护和隐私的影响,以及非洲各国政府如何准备应对人工智能以检查数据和隐私泄露。

将数据保护原则应用于生成人工智能
生成式人工智能 (genAI) 系统已经问世,并将持续存在,支持个人和企业用户大规模快速地生成音频、代码、图像、文本和视频内容。在 genAI 工具广泛用于公众的短时间内,我们见证了世界各地个人和组织的广泛采用。OpenAI 的 ChatGPT 现在每周拥有超过 2 亿活跃用户,1 微软的 Github Copilot 拥有超过一百万付费用户,2 根据麦肯锡技术委员会 2024 年的一项研究,65% 的全球组织已在至少一个业务功能中采用了 genAI 系统。3 一般而言,genAI 系统依赖于通用人工智能 (AI) 模型(也称为基础模型 4),这些模型通常使用大量数据进行训练以实现各种目的。例如,大型语言模型使用来自多种来源的数十亿字节文本数据进行训练,例如来自网络的公开数据(其中可能包括个人数据)、许可数据以及学术和行业数据集。 5 从这些庞大而多样化的数据集中,genAI 模型经过训练,能够识别单词与其他数据(如图像、视频和音频)之间的统计关系,以响应各种用户提示,并做出概率预测,从而生成有用的输出。 6 此外,genAI 模型可以进一步“微调”和个性化,使用专门策划的数据,以便更好地完成特定目的。例如,genAI 模型可以使用医疗数据进行微调,以协助医生和医护人员做笔记和临床记录。 7 模型还可以个性化,以在客户参与或个性化辅导环境中回答新问题。 GenAI 系统要求用户输入提示以获得生成的输出,输入和输出有时可能包括个人甚至敏感信息。 8 在部署期间,genAI 模型可能会泄露或披露来自训练数据集的个人数据,并生成与个人相关的不准确数据(也称为“幻觉”),恶意行为者可以使用各种方法绕过为避免泄露 genAI 模型中的个人数据而设置的保护栏。因此,数据保护机构、其他监管机构以及研究人员越来越多地讨论数据保护法是否以及如何适用于 genAI 工具,这些系统可能给数据保护带来哪些新的风险,以及如何解决某些数据保护原则与 genAI 之间的潜在紧张关系。本讨论文件考虑了以下关键的隐私和数据保护概念,并探讨了如何将它们有效地应用于 genAI 模型和系统的开发和部署:
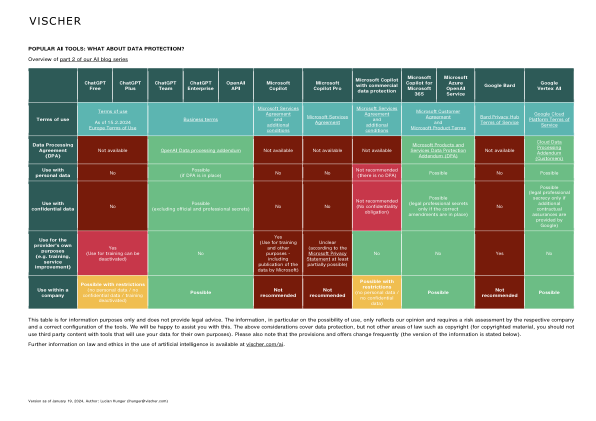
AI 工具 - 数据保护(英文概述)
此表仅供参考,不提供法律建议。信息(尤其是有关使用可能性的信息)仅反映我们的意见,需要相关公司进行风险评估并正确配置工具。我们很乐意为您提供帮助。上述考虑涵盖数据保护,但不涉及版权等其他法律领域(对于受版权保护的材料,您不应将第三方内容与将使用您的数据用于其自身目的的工具一起使用)。另请注意,条款和要约经常更改(信息版本如下所述)。

国防部网络、系统和数据保护战略
2011 年 7 月,国防部 (DoD) 发布了《国防部网络空间作战战略》(DSOC),该战略源于《2010 年四年期国防评估》和《2010 年国家安全战略》中概述的战略主线。DSOC 规定网络空间是一个作战领域,国防部应将工作重点放在任务保证和关键作战能力的保护上。DSOC 的战略计划 2(采用新的国防作战概念保护国防部网络和系统)呼吁实施不断发展的国防作战概念,以实现国防部的网络空间任务要求。国防部的《网络、系统和数据防御战略》响应了该要求以及其他相关的 DSOC 计划,并确定了确保国防部网络资产的保护、完整性和保障的战略要务。该战略的目标是:• 确定重点关注和转变国防部网络安全和网络防御行动所需的战略要务• 重塑国防部网络文化、技术、政策和流程,以专注于实现作战人员的任务和需求• 确保网络和系统能够在有争议的网络环境中运行• 使国防部能够履行其在保卫国家免受网络攻击方面的职责

偏见评估 - 欧洲数据保护委员会
4. 汇总偏差:当数据集来自整个人口时,可能会对个人或小群体得出错误的结论。这种偏差最常见的形式是辛普森悖论(Blyth,1972),当只考虑整个人口的汇总数据时,小群体数据中观察到的模式就会消失。最著名的例子来自 1973 年加州大学伯克利分校的录取(Bickel 等人,1975)。根据汇总数据,女性申请者被拒绝的次数似乎明显多于男性。然而,对部门级数据的分析显示,大多数部门男性的拒绝率更高。汇总数据未能揭示这一点,因为女性申请总体录取率低的部门的比例高于申请录取率高的部门的比例。

人道主义行动中的数据保护手册
• SaaS – 软件即服务 • 敏感数据是指个人数据,如果披露,可能会导致对相关个人的歧视或压制。通常,与健康、种族或民族、宗教/政治/武装团体隶属关系或基因和生物特征数据有关的数据被视为敏感数据。所有敏感数据都需要加强保护,尽管属于敏感数据范围的不同类型的数据(例如不同类型的生物特征数据)可能具有不同的敏感程度。鉴于人道主义组织工作的具体情况以及某些数据元素可能导致歧视的可能性,列出人道主义行动中敏感数据类别的明确清单毫无意义。数据的敏感性以及适当的保障措施(例如技术和组织安全措施)必须根据具体情况进行考虑。

数据保护影响评估(DPIA)决定...
•隐形处理:在控制者认为符合第14条(提供隐私通知)的情况下,未直接从数据主题获得的个人数据处理或涉及不成比例的努力处理时,您不会直接从个人手中获得其他个人数据,而您本身并不直接从某人那里获得个人数据,并且由您提供隐私条款14的第14条。该处理是“不可见的”,因为即使您在网站上发布隐私通知,个人也不知道您正在收集和使用其个人数据。此处理会导致个人利益的风险,因为它们无法对您使用数据的使用进行任何控制。尤其是,如果他们不了解处理权,他们将无法使用其数据保护权。即使处理本身不太可能产生任何负面影响,这也是如此。,如果处理或任何结果可能不会被个人合理地预测,您也可能有违反第一个数据保护原则的公平和透明度要求的风险。

欧洲数据保护条例是否足以……
摘要 神经科学领域的研究驱动技术发展提出了一些有趣且可能复杂的问题,这些问题与数据有关,尤其是脑数据。脑记录产生的数据与姓名和地址不同,它可能来自大量非自愿脑活动的处理,可以针对不同目的进行处理和再处理,而且非常敏感。由于这些因素,同意特定类型或特定目的的脑记录变得复杂。脑数据的收集、保留、处理、存储和销毁都具有高度的伦理重要性。这让我们不禁要问:目前的欧洲数据保护条例是否足以处理与神经技术相关的新兴数据问题?在脑机接口 (BCI) 领域快速发展的背景下,这个问题尤其紧迫,通过记录的脑信号发挥作用的设备正在从研究实验室扩展到医疗治疗,甚至扩展到消费市场,用于娱乐用途。我们在此提出的一个观点是,在脑部记录方面,可能不存在琐碎的数据收集,尤其是在涉及算法处理的情况下。本文对与神经技术(尤其是 BCI)相关的一些特定数据保护问题进行了分析和讨论。特别是,BCI 驱动的应用程序中使用的脑部数据是否以及如何以与个人数据相关的方式算作个人数据

意见 3/2020 - 欧洲数据保护监督员
鉴于数据汇集将方便许多不同参与者访问,因此,数据主体能够确定他们的数据被谁做了什么。因此,一些控制者仍然采用的常规透明度方法是冗长的隐私声明,这些声明以抽象或模棱两可的术语表达,这违反了 GDPR 的要求,即“以简洁、透明、易懂和易于访问的形式,使用清晰明了的语言”提供信息。12 。在此背景下,尤其是考虑到技术发展,EDPS 提醒,根据 GDPR 第 12(7) 和 (8) 条,向数据主体提供的信息可以使用标准化和机器可读的图标,以便提供易于查看、易懂和有意义的预期处理概述。委员会应在 2022 年之前通过授权法案确定所需信息将如何以此类标准化图标呈现。17. 个人信息管理系统 (PIMS) 正在成为有前途的平台,