XiaoMi-AI文件搜索系统
World File Search System数据操作

从计算和神经教育方法建模创造性解决问题的任务
摘要:创造力是一个复杂的过程,已在不同领域进行了研究,在任务类型、背景和评估方法方面具有高度的多样性。在本研究中,我们专注于定义不明确的个人创造性问题解决 (CPS) 任务,目的是创建一个基于 CPS 调节过程的计算模型,该模型受到相关认知过程和人工认知架构的神经科学知识的启发。模型操作化考虑了学习者在解决定义不明确的任务时所采用的路径的突发特性以及该路径在描述任务的问题空间内的几何化。然后根据创造力背后的计算过程区分基于刺激和目标导向的创造性行为。通过计算和神经教育方法,该研究引入了创造性问题解决任务的模型,并提供了问题解决任务的操作几何定义,强调了与定义不明确的问题相关的挑战。我们完成了关于创造力作为一种语义基础过程的讨论,重点是数据表示,以及使用推理和度量空间算法进行符号数据操作。
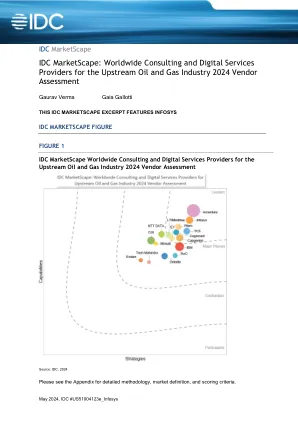
IDC MarketScape:2024 年上游石油和天然气行业全球咨询和数字服务提供商供应商评估
IDC MarketScape 为全球石油和天然气公司提供了有关 IT 服务供应商在石油和天然气价值链上游领域咨询和数字服务领域的当前能力和未来战略的见解。它评估服务提供商结合其咨询能力(包括创造力、战略、设计、体验设计和以人为本的产品开发)、创新加速器技术方面的专业知识和领导力以及 IT 服务(如 IT 咨询、系统集成、应用程序开发、业务外包和 IT 外包)提供复杂的咨询主导的数字化转型 (DX) 服务的能力。这些服务提供商的产品使上游最终用户能够将创新的数字用例变为现实,从而更有效、更高效地执行 E&P 流程。本报告重点关注数字用例,因为它们与改善上游石油和天然气业务流程有关,涉及智能勘探、G&G 数据操作化、实时和集成碳氢化合物生产管理、连接油田资产管理和智能工作流优化等宏观领域。IDC MarketScape 评估了以下数字用例:

SpaceX Falcon9使用机器学习登陆预测
该项目工作的目的是使用数据科学和机器学习算法预测SpaceX Falcon 9火箭着陆系统的成功或失败。此项目所需的数据是从SpaceX API收集的。以下工具和技术用于数据预处理和分析:用于数据操作和分析的PANDA和NUMPY,用于探索性数据分析的数据可视化以及用于预测的机器学习算法。该项目涉及以下步骤:从SpaceX API中收集数据,使用Pandas和Numpy进行预处理数据,并使用数据可视化技术,功能工程来提取预测模型的相关功能,构建机器学习模型,以预测Falcon 9 Rocket登陆的成功或使用适当的模型的表现,并使用适当的Metrics进行了预测。该项目使用机器学习算法来预测Falcon 9火箭着陆的成功或故障。该模型对历史数据进行了培训,并对新数据进行了测试以评估其性能。该项目旨在洞悉导致Falcon 9火箭登陆的成功或失败的因素。

使用等级顺序集群算法作为部分机器...
摘要 - 由J.R. King开发的等级顺序集群(ROC)算法在过去五十年中已经取得了重大进步,并在包括制造的各种领域中广泛使用用于机器和零件的分组。本研究研究了ROC算法在细胞制造系统(CMS)中的利用,以优化机细胞和部分家族的创建,目的是提高生产效率。该研究提出了采用二元零件机器人矩阵的全面分析,并利用Microsoft Excel进行数据操作。通过迭代重新排列的行和列基于二进制值,ROC算法有效地将机器和零件分为相交的机器单元和非交流零件系列。涉及16×10二元零件机器人基质的案例研究证明了ROC算法的实际实现。研究结果表明,尽管ROC算法提供了一种结构化的细胞形成方法,但其有效性可能会有所不同。这项研究强调了ROC算法在改善制造布局优化和过程管理方面的潜力,从而铺平了

勒克瑙综合大学
UNIT-I 微处理器的演变,RISC 与 CISC 的比较 8085 简介:微处理器发起的操作和总线组织、内部数据操作、8085 寄存器、外部发起的操作、存储器组织、映射和类型 - I/O 寻址类型、存储器映射 I/O、功能块、引脚图、指令和时序、指令分类。(10)UNIT-II 编程与架构、8085 指令集、编程技术、堆栈和子程序、中断及其类型、简单的说明性程序。(8)UNIT-III 数据传输方案、可编程外围设备简介(8255A、8257、PIC 8259、USART 8251)以及 PPI 8255 与 8085 处理器的接口。(8)UNIT-IV 8086 简介、架构、寻址模式、引脚图及其最小/最大配置。 (6) 先进处理器简介(386、486 和奔腾处理器)简介 - MMX 技术。UNIT-V 微处理器、微控制器和嵌入式系统、8051 微控制器之间的比较:引脚图、架构、寻址模式、指令集、微控制器的应用。嵌入式系统的内部和外部存储器。 (8) 教科书:1. Ramesh Goanker,《微处理器与接口 - 编程与硬件》。

西方国家的老年人的糖尿病自我管理教育(DSME):范围审查
1型糖尿病(T1D)的病因是一种以自身免疫性破坏胰腺β细胞为特征的复杂疾病[1]。目前尚无治疗方法或有效的预防策略,直到最近才进行了免疫干预措施,以延迟FDA批准(teplizumab)[2]。在没有完全阻塞T1D开始和发展为临床疾病的情况下,唯一的治疗方法是终身胰岛素治疗。因此,需要确定治疗干预的新目标。从遗传关联研究(例如T1D)的遗传关联研究可以提供对病原体的新见解,揭示了潜在的治疗靶标[3],并为前靶靶标提供了人类的遗传支持[4]。但是,将遗传发现转化为生物学和治疗见解存在主要障碍。遗传关联研究的结果对于许多科学而言是无法访问的,因为利用和解释大型遗传“摘要”文件需要在数据操作和域特异性生物信息学工具方面的知识方面的专业知识。此外,大多数T1D风险变体映射到非编码序列,其中基因组的详细功能注释对于预测受影响的细胞类型和基因是必要的[5]。最后,在细胞和动物模型中测试变体和基因功能仍然是一项实质性的事业,通常需要多年的工作。

原创研究论文人工智能运营模式:人工智能运营和部署的建议框架
摘要:新企业的核心是某种智能控制的决策工厂,涵盖所有活动。人工智能 (AI) 的一大前景是它能够显著提高公司(尤其是具有数字内涵的公司)接收、处理或生成的数据量。要带来巨大的变化,人工智能不必是科幻小说,而只需一种处理计算机化主题的新方法,无论是在设计、开发还是预期结果方面。应该注意的是,传统的 IT 解决方案呈现了一种称为“弱人工智能”的人工智能形式,而备受关注、炒作和转型承诺以及增长潜力的人工智能被称为“强人工智能”。本文旨在以教学方式介绍一种称为 D2MO(用于数据操作、ML 操作、模型操作和 AI 操作)的模型,允许公司以结构化的方式实施人工智能主题、活动和项目。我们的目标是通过这篇文章为 IT 和业务专家提供一个新框架,为组成基于 AI 的系统的不同模块和参与者提供完美的衔接,从而使他们能够在利用这项技术的同时和谐而敏捷地运作。关键词:人工智能、ML Ops、AI Ops、数据 Ops、模型 Ops 简介

2024-2025 届会议
单元 1:计算思维和编程 – 2 ● 复习 11 年级中涵盖的 Python 主题。 ● 函数:函数类型(内置函数、模块中定义的函数、用户定义函数)、创建用户定义函数、参数和形参、默认参数、位置参数、函数返回值、执行流程、变量的作用域(全局作用域、局部作用域) ● 异常处理:简介、使用 try-except-finally 块处理异常 ● 文件简介、文件类型(文本文件、二进制文件、CSV 文件)、相对路径和绝对路径 ● 文本文件:打开文本文件、文本文件打开模式(r、r+、w、w+、a、a+)、关闭文本文件、使用 with 子句打开文件、使用 write() 和 writelines() 将数据写入/附加到文本文件、使用 read()、readline() 和 readlines() 从文本文件读取、seek 和 tell 方法、文本文件中的数据操作 ● 二进制文件:二进制文件的基本操作:使用文件打开模式(rb、rb+、wb、wb+、ab、ab+)打开、关闭二进制文件、导入 pickle 模块、dump()和 load() 方法,在二进制文件中读取、写入/创建、搜索、附加和更新操作 ● CSV 文件:导入 csv 模块,打开/关闭 csv 文件,使用 writer()、writerow()、writerows() 写入 csv 文件并使用 reader() 从 csv 文件中读取 ● 数据结构:堆栈、堆栈上的操作(推送和弹出)、使用列表实现堆栈。

2024-2025 届会议
单元 1:计算思维和编程 – 2 ● 复习 11 年级中涵盖的 Python 主题。 ● 函数:函数类型(内置函数、模块中定义的函数、用户定义函数)、创建用户定义函数、参数和形参、默认参数、位置参数、函数返回值、执行流程、变量的作用域(全局作用域、局部作用域) ● 异常处理:简介、使用 try-except-finally 块处理异常 ● 文件简介、文件类型(文本文件、二进制文件、CSV 文件)、相对路径和绝对路径 ● 文本文件:打开文本文件、文本文件打开模式(r、r+、w、w+、a、a+)、关闭文本文件、使用 with 子句打开文件、使用 write() 和 writelines() 将数据写入/附加到文本文件、使用 read()、readline() 和 readlines() 从文本文件读取、seek 和 tell 方法、文本文件中的数据操作 ● 二进制文件:二进制文件的基本操作:使用文件打开模式(rb、rb+、wb、wb+、ab、ab+)打开、关闭二进制文件、导入 pickle 模块、dump()和 load() 方法,在二进制文件中读取、写入/创建、搜索、附加和更新操作 ● CSV 文件:导入 csv 模块,打开/关闭 csv 文件,使用 writer()、writerow()、writerows() 写入 csv 文件并使用 reader() 从 csv 文件中读取 ● 数据结构:堆栈、堆栈上的操作(推送和弹出)、使用列表实现堆栈。

数据科学与人工智能硕士 (MSc)。
深入了解数据结构和数据操作。了解监督和无监督学习模型,包括线性回归、逻辑回归、聚类、降维、K-NN 和管道。使用 SciPy 包及其子包(包括 Integrate、Optimize、Statistics、IO 和 Weave)执行科学和技术计算。使用 NumPy 和 Scikit-Learn 获得数学计算方面的专业知识。掌握推荐引擎和时间序列建模的概念。理解机器学习的原理、算法和应用。了解人工智能在不同领域的各种用例中的应用,如客户服务、金融服务、医疗保健等。实现经典的人工智能技术,如搜索算法、神经网络和跟踪。学习如何应用人工智能技术解决问题,并解释当前人工智能技术的局限性。设计和构建自己的智能代理,并应用它们创建实际的人工智能项目,包括游戏、机器学习模型、逻辑约束满足问题、基于知识的系统、概率模型、代理决策功能等。了解 TensorFlow 的概念、主要功能、操作和执行管道。掌握卷积神经网络、循环神经网络、训练深度网络和高级接口等高级主题。使用 Tableau 分析数据并熟练构建交互式仪表板 了解 Hadoop 生态系统的不同组件,并学习使用 HBase、其架构和数据存储,了解 HBase 和 RDBMS 之间的区别,并使用 Hive 和 Impala 进行分区。了解 MapReduce 及其特性,并学习如何使用 Sqoop 和 Flume 提取数据。使用最流行的库 Python 的自然语言工具包 (NLTK) 了解自然语言处理的基础知识。