XiaoMi-AI文件搜索系统
World File Search System数据解释

生物信息学中的Chatgpt和DeepSeek -IJRPR
近年来,人工智能(AI)已成为各个领域的强大工具,生物信息学是其表现出变革性潜力的最杰出领域之一。生物信息学涉及大规模的生物学数据分析,包括基因组序列,蛋白质结构和临床数据。使用机器学习(ML),深度学习(DL)和自然语言处理(NLP)技术在理解复杂的生物学现象方面加速了进展,而在这项革命的最前沿,是OpenAI开发的大型语言模型。chatgpt建立在GPT(生成预审预测的变压器)等尖端神经网络体系结构上,在文本生成,数据解释甚至对话交流方面都表现出了非凡的功能。其在生物信息学中的实施可以导致更快,更有效的研究和更有效的临床决策。从协助基因组学到改善医学教育和增强药物发现,Chatgpt正在改变生物信息学家和医疗保健专业人员处理复杂问题的方式。但是,与任何技术进步一样,需要考虑的挑战。这些包括数据隐私问题,AI-I-Intent的道德含义以及AI模型在临床决策中的可靠性。本手稿旨在探索生物信息学中Chatgpt的潜力和局限性,从而概述其应用,道德考虑以及AI在生物医学科学中的未来方向。

跨学科研究与创新中心(CIRI)
哲学和道德,关于科学和研究的道德,智力诚实和研究完整性,科学不当行为:伪造,制造和窃(FFP)(FFP),多余的出版物:重复和重叠的出版物,萨拉米语,选择性的报告,选择性报告和陈述数据。出版道德:定义,引言和重要性,利益冲突,出版物不当行为:定义,概念,导致不道德行为的问题,违反出版伦理学,作者身份,出版物不当行为,投诉和上诉,掠夺性出版商和期刊。II II:生物信息学和生物统计学下一个基因组测序和分析方法。 染色体构象捕获和染色质免疫沉淀与测序(CHIP-SEQ)耦合。 序列对齐clustalw和Omega。 统计,数据类型,平均值,模式,中值,样本方差和样本标准偏差的简介。 数据解释和分析,精度和准确性,误差分析,最小二乘拟合,线性和非线性回归和相关分析,假设检验(T和F假设检验),显着性测试,拟合测试的方形优势。 拟合优度的重要性。 单元III:Techniques-1电泳:类型,原理和应用。 印迹技术:类型,原理和应用。 通过ELISA测定抗原抗体浓度。 确定解离常数和基本的生化计算。 质谱法:原理,电离方法和质谱的应用。II II:生物信息学和生物统计学下一个基因组测序和分析方法。染色体构象捕获和染色质免疫沉淀与测序(CHIP-SEQ)耦合。序列对齐clustalw和Omega。统计,数据类型,平均值,模式,中值,样本方差和样本标准偏差的简介。数据解释和分析,精度和准确性,误差分析,最小二乘拟合,线性和非线性回归和相关分析,假设检验(T和F假设检验),显着性测试,拟合测试的方形优势。拟合优度的重要性。单元III:Techniques-1电泳:类型,原理和应用。印迹技术:类型,原理和应用。通过ELISA测定抗原抗体浓度。确定解离常数和基本的生化计算。质谱法:原理,电离方法和质谱的应用。明亮场和共聚焦显微镜的原理和应用。单元IV:Techniques-2色谱原理及其类型。 紫外可见吸收光谱的原理和应用。 原理和荧光光谱的应用。 圆形二科运动(Far-UV,近紫外)。 红外光谱。 拉曼光谱和动态光散射。 X射线衍射的基本,Bragg定律,X射线晶体学,低温电子显微镜,透射电子显微镜,扫描电子显微镜,NMR光谱的基础知识及其应用。单元IV:Techniques-2色谱原理及其类型。紫外可见吸收光谱的原理和应用。原理和荧光光谱的应用。圆形二科运动(Far-UV,近紫外)。红外光谱。拉曼光谱和动态光散射。X射线衍射的基本,Bragg定律,X射线晶体学,低温电子显微镜,透射电子显微镜,扫描电子显微镜,NMR光谱的基础知识及其应用。

遥感方法在农业中的应用 - 农业生物学
对妨碍遥感数据解释的因素的敏感性,例如土壤背景、地貌、植物的非光合作用元素、大气、观看和照明几何(Huete 和 Justice 1999)最常用的指数是归一化差异植被指数 (NDVI),由 Rouse 等人 (1974) 提出,计算为近红外和红光区域反射率差与和的商。由于叶片叶肉的散射,植物的绿色部分在近红外区域反射强烈,并通过叶绿素强烈吸收红光和蓝光(Ayala-Silva 和 Beyl 2005)。NDVI 指数最常用于确定栽培植物的状况、发育阶段和生物量以及预测其产量。 NDVI 已成为最常用的植被指数(Wallace 等人,2004 年;Calvao 和 Palmeirim,2004 年),人们做出了许多努力,旨在开发更多指数,以减少土壤背景和大气对光谱测量结果的影响。限制土壤对遥感植被数据影响的植被指数的一个例子是 Huete(1988 年)提出的 SAVI(土壤调节植被指数)。另一个是 VARI 指数(可见大气抗性指数)(Gitelson 等人,2002 年),它大大降低了大气的影响。人们还开发了更多指数来考虑 NIR 和 SWIR 范围内的反射率差异,这表明植物缺水:MSI (

革命性的发育神经毒性测试
抽象的发育神经毒性(DNT)测试在过去二十年中取得了巨大进步。即使在2007年的DNT测试中的动物OECD测试指南之前,2005年开始的一系列非动物技术研讨会和会议都塑造了一个社区,该社区提供了一系列体外测试方法(DNT IVB)的全面电池。现在,其数据解释已被最近的经合组织指南涵盖(No.377)。在这里,我们概述了该领域的进展,重点是测试策略的演变,新兴技术的作用以及OECD测试指南对DNT测试的影响。,这是针对化学物质对人类健康最复杂的危害之一的无动物测试方法的靶向发展的一个例子。这些发展从字面上始于空白的板岩,没有提出的替代方法可用。在过去的二十年中,尖端的科学实现了一种测试方法的设计,该方法能够避免动物,并使吞吐量能够解决这一挑战性危害。显然,该领域需要指导和法规,但应更优先考虑化学暴露引起的人类认知能力的巨大经济影响。除此之外,在体外测试中名声的主张是它带来的巨大科学进步,以理解人的大脑,其发育以及如何受到干扰。

软件工具(SPSS,NVIVO)在数据分析中的作用
rvsd001@gmail.com和sskadam@mitacsc.ac.ac.in摘要:nvivo,在增强不同研究学科的数据分析方面发挥关键作用。随着数量和数据复杂性的增加,研究人员对分析工具的压力是可靠和有效的结果所必需的。本研究通过结合定性访谈和定量调查来应用混合方法设计,以确定此类工具如何增强数据分析的速度,准确性和范围。关键调查结果包括报告显示85%的受访者表明SPS是为了进行统计分析所必需的,而对于管理定性数据和主题分析,对NVivo的90%对NVivo具有相同的看法。参与者报告了由于这些工具的功能而增加的时间节省,并增加了分析性的严格性。此外,研究指出了混合方法研究的SPS和NVivo的整合可能性,因此数据解释将更好地全面。但是,定量和定性研究结果的综合仍然是一个挑战。的发现表明,只有在研究人员接受足够的使用培训时,该工具才有用。它有助于通过软件工具理解数据分析的促进,从而提高了研究质量,并为一系列学科的基于证据的原则提供了决策。关键字:SPSS,NVIVO,数据分析,定量研究,定性研究,混合方法,研究工具,主题分析,统计分析
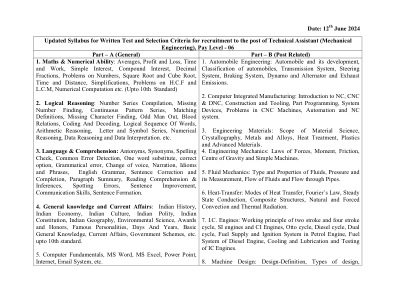
日期:2024 年 6 月 12 日 笔试更新大纲...
工程)、薪酬水平 - 06 部分 - A(一般)部分 - B(职位相关)1.数学与数字能力:平均值、利润和损失、时间和工作、单利、复利、小数、数字问题、平方根和立方根、时间和距离、简化、HCF 和 LCM 问题、数值计算等。(最高 10 年级)2.逻辑推理:数字系列汇编、缺失数字查找、连续模式系列、匹配定义、缺失字符查找、奇数、血缘关系、编码和解码、单词的逻辑顺序、算术推理、字母和符号系列、数字推理、数据推理和数据解释。等。3. 语言与理解:反义词、同义词、拼写检查、常见错误检测、单词替换、正确选项、语法错误、变声、叙述、习语和短语、英语语法、句子改错和完成、段落总结、阅读理解与推理、发现错误、句子改进、沟通技巧、句子形成。4. 一般知识和时事:印度历史、印度经济、印度文化、印度政体、印度宪法、印度地理、环境科学、奖项和荣誉、名人、日子和年份、基本常识、时事、政府计划等,最高 10 年级标准。5. 计算机基础、MS Word、MS Excel、Power Point、互联网、电子邮件系统等。

EDM-900 - J.P. 仪器
目录 第 1 节 - 入门 1 按钮 1 为飞机加油 3 显示屏 3 RPM 和 MAP 部分显示 3 条形图部分显示 3 Scanner® 基本操作 4 第 2 节 - 数据解释 6 飞行各阶段的操作 6 典型正常测量值 8 发动机诊断图表 9 第 3 节 - LeanFind 11 LeanFind 模式 - 倾斜“峰值富油”方法 11 LeanFind 程序 - 详细说明 14 倾斜查找模式 - “峰值倾斜”方法,GAMI 喷油器 16 涡轮增压发动机 17 第 4 节 - 警报 17 警报优先级 18 提前点火和爆震 19 第 5 节 - 显示和控制 19 RPM 和 MAP 显示 20 Scanner® 显示 20 条形图显示 22 远程辅助显示选项 23 第 6 节 - 操作 23 模式23 自动模式 23 手动模式 24 LeanFind 模式 24 第 7 节 - 燃油流量功能 24 燃油管理 26 测量扫描 27 第 8 节 - 内存和数据下载 27 将数据从 EDM-900 传输到笔记本电脑 28 第 9 节 - 首次设置和自定义 29 第 10 节 - 自定义编程 35 第 11 节 - 确定燃油液位校准点 36 第 12 节 - 自定义条形图显示 39 第 13 节 - EDM 故障排除 39 常见误用 39

激光探索 1 - 波涛之下:看到证据......
图1:中大西洋山脊系统显示较高的分辨率回声沿着船只轨道映射,并在卫星数据之间进行卫星数据解释。(Google Earth:Data Sio,NOAA,美国海军,NGA,Gebcodata ldeo-Columbia,NS,Noaalandsat/Copernicus)此EarthlearneNingIdea是一种试图模拟回声数据收集方法的试图,该方法允许科学家绘制海洋底层并解释其板块构造的板块。(本系列中的“激光任务2 - 在波浪上方”显示了卫星方法 - 第2页上的表)。海洋有多深?回声声音是一种技术,其中一种声纳使用声波来确定水深(测深),从而确定海底表面的形状(地形)。声波是从船上的仪器(换能器)上的仪器中射出的,并测量了从海底(双向时间)反射的波浪所花费的时间,并将其转换为海洋深度。这在深渊平原的深水中提供了约100米的分辨率。可以使用D.I.Y.可以在教室中模拟回声声音。激光测量(或激光测距仪) - 手持测量设备,通过将激光从设备发送到目标,并测量反射返回所需的时间,记录两个点之间的距离。这提供了涉及原则的实际证明。(它还补充了第2页的表中所引用的地球“建模海底映射”)

神经仪:大脑连接组中图形机学习的基准
机器学习提供了一种有价值的工具,用于分析高维功能神经影像学数据,并证明可以有效预测各种神经系统疾病,精神疾病和认知模式。在功能磁共振成像(MRI)研究中,大脑区域之间的相互作用是使用基于图的表示形式建模的。图形机学习方法的效力已经在跨众多域中建立,标志着数据解释和预测建模的跨形成一步。,尽管他们有希望,但由于潜在的预处理管道数量的庞大数量以及基于图的数据集构建的大量参数搜索空间,这些技术向神经影像域的换位一直在挑战。在本文中,我们介绍了神经图1,这是基于图的神经影像数据集的集合,并展示了其用于预测多种行为和认知性状的实用性。我们通过制作包含静态和动态大脑连接性的35个数据集,深入研究数据集生成搜索空间,运行超过15种基线方法进行基准测试。此外,我们还提供通用框架 - 用于在静态图和动态图上学习。我们的广泛实验导致了几个关键观察。值得注意的是,使用相关向量作为节点特征,结合了更多的感兴趣区域并使用稀疏图会提高性能。为了促进基于图的数据驱动神经成像分析的进一步进步,我们提供了一个全面的开源Python软件包,其中包括基准数据集,基线实现,模型培训和标准评估。

bimsa:使用内存处理加速长序列对齐
单细胞RNA-Seq以前所未有的规模和细节来表征生物样品,但数据解释仍然具有挑战性。在这里,我们介绍了Cellwhisperer,这是一种多模式的机器学习模型和软件,该模型和软件连接转录组和文本,用于交互式单细胞RNA-seq数据分析。Cell Whisperer启用25英语中基于聊天的转录组数据的询问。为了培训我们的模型,我们创建了一个具有超过一百万对RNA-seq配置文件和匹配的文本注释的A-Ai-Cunip策划数据集,并在广泛的人类生物学上进行了匹配,我们建立了使用对比学习的匹配转录组和文本的多模式嵌入。我们的模型启用了按单元类型,状态和其他属性以零摄像的方式启用转录组数据集的自由文本搜索和注释,而无需参考数据集。此外,细胞-30个耳语者回答了关于自然语言聊天中细胞和基因的问题,使用生物学流利的大语言模型,我们对我们进行了微调,以分析各种生物应用中的批量和单细胞转录组数据。我们将Cell Whisperer与广泛使用的CellXgene浏览器集成在一起,使用户可以通过集成的图形和聊天接口进行遗传探索RNA-Seq数据。我们的方法展示了一种使用转录组数据的新方法,利用自然语言进行单细胞数据35分析,并为未来的基于AI的生物信息学研究助理建立重要的基础。