XiaoMi-AI文件搜索系统
World File Search System数据量

![arXiv:2002.03688v1 [eess.IV] 2020 年 2 月 10 日](/simg/5\5ef42afacf9eaa5a3d06e9ec993481c8c60d02e8.webp)
arXiv:2002.03688v1 [eess.IV] 2020 年 2 月 10 日
摘要。多模态 MRI 中的脑肿瘤分割是医学图像分析中最具挑战性的任务之一。解决此任务的最新算法基于机器学习方法,尤其是深度学习。用于训练此类模型的数据量及其可变性是构建具有高表示能力的算法的基石。在本文中,我们研究了模型性能与训练过程中使用的数据量之间的关系。以脑肿瘤分割挑战为例,我们比较了使用挑战组织者提供的标记数据训练的模型,以及使用用异构模型集合注释的额外未标记数据以全监督方式训练的相同模型。结果,使用额外数据训练的单个模型实现了接近多个模型集合的性能,并且优于单个方法。
Error 500 (Server Error)!!1500.That’s an error.There was an error. Please try again later.That’s all we know.
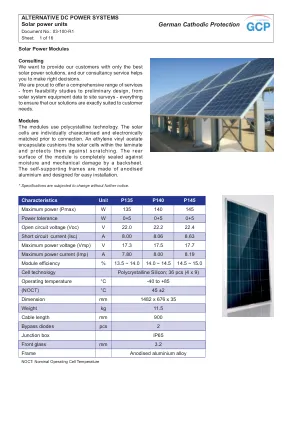
LED指标:电池充电,子阵列1、2和3断开连接,预警低压,一般警报 /负载断开连接。“交换机的翻转”系统诊断功能。无维护操作多年。所有主要系统组件的中心连接点。可选警报继电器。可选的从单元增加数组输入电流。可选仪器单元用于在线诊断。可选输出继电器能够切换60 A(恒定电流)。可选的数据量,用于测量小时平均。 可选的输出调节器,用于限制电压或阴极保护。 可选的高压瞬态保护具有瞬态电压抑制器。 可根据要求提供自定义选项。可选的数据量,用于测量小时平均。可选的输出调节器,用于限制电压或阴极保护。可选的高压瞬态保护具有瞬态电压抑制器。可根据要求提供自定义选项。
高性能交易:算法速度
•有助于准备新的法规:Reg NMS和MiFID等监管更改将生成更多报价,订购和取消/替换消息,因为股权公司适应了更多的电子业务流程。在美国,Subpenny-Presing规则还将增加对支持基础设施的需求。 MiFID还将导致更高的数据量,因为将其内部化交易的投资银行以电子方式发布。 交易应用程序的加速有助于确保最佳执行要求并提高交易竞争优势。在美国,Subpenny-Presing规则还将增加对支持基础设施的需求。MiFID还将导致更高的数据量,因为将其内部化交易的投资银行以电子方式发布。交易应用程序的加速有助于确保最佳执行要求并提高交易竞争优势。

数字化工厂40人工智能优化中小企业生产流程
借助人工智能,可以通过预测分析提前预测故障或失效,报告异常问题,帮助配置和修复程序,减少开发时间和精力,优化生产流程,并从获取的数据量中提取有用的信息。


严肃游戏与人工智能:计算社会科学的挑战与机遇
摘要 电子游戏行业在我们社会的娱乐领域中扮演着重要角色。然而,从大富翁到飞行模拟器,严肃游戏也已成为学习新语言、传达价值观或训练技能的有吸引力的工具。此外,过去十年人工智能 (AI) 和数据科学的复兴创造了一个独特的机会,因为通过游戏收集的数据量是巨大的,为此类 AI 算法提供数据所需的数据量也是巨大的。本文旨在确定使用严肃游戏作为一种新颖的研究工具的相关研究方向,特别是在计算社会科学领域。为了了解背景,我们还对该领域进行了(非系统的)文献综述。我们得出的结论是,游戏和数据之间的协同作用可以促进人工智能的良好使用,并开辟新的战略,以赋予人类权力并通过新颖的计算工具支持社会研究。我们还讨论了追求如此崇高目标所带来的挑战和新机遇。

最终年度项目报告(数字图像...
在过去的几十年中,对计算机的依赖和信息的效用一直在急剧增长。因此,开发用于存储和传输不断增加的数据量的有效技术已成为一个高度优先的问题。图像压缩通过减少表示数字图像所需的数据量来解决该问题。压缩过程的基础是删除冗余数据。为给定应用程序选择合适的压缩方案取决于可用的处理内存、数学计算的数量和可用的传输带宽。数字图像的安全性是另一个重要问题,近年来一直受到广泛关注。文献中提出了不同的图像加密方法来确保数据的安全性。加密过程将二维像素阵列转换为统计上不相关的数据集。本文提出了一种基于增强数论的彩色图像压缩和加密方案。该技术同时包含基于图像压缩和图像加密的双重应用,采用基于模型的范例作为通用压缩加密标准。

使用人工智能进行相控阵数据分析
摘要:在过去的 20 年中,人们采取了多项措施来提高无损检测的质量。便携式相控阵仪器的引入带来了超声波数据的记录,从而更好地控制了检测质量。在线培训的引入带来了理论教学的标准化,从而培养了训练有素的检验员和分析员。然而,在缺陷检测、识别和定量方面仍然存在问题。即使数据量呈爆炸式增长,数据分析仍然完全依赖于人类分析师的技能。不幸的是,虽然需要分析的数据量呈爆炸式增长,但合格数据分析师的数量并没有相应增加。结果是评估数据的时间更短,数据分析师的工作时间更长。必须为数据分析师提供新工具,以便他们能够更高效、更准确地执行任务。在本文中,我们回顾了分析相控阵超声数据的挑战以及人工智能提供的独特解决方案

大数据和人工智能的海洋
多样性和真实性 [“图8.1”](“Kitchin 2014”)。目前,量化全球数据量并不是一件简单的事情。根据国际数据组织的研究——“2020 年的数字宇宙”(“https"://bit. ly/3b4xgyy”),2020 年的数据量将达到约40 万亿千兆字节(“或 40 泽字节”)。有趣的是,大多数数据是在过去两年内生成的,到 2020 年,预计每个人每秒将生成 1.7 Mb(“https"://bit.ly/3fEQsH”),或每天生成 146,880 GB,到 2025 年每年将生成 165 泽字节(“https"://bit.ly/3b4xgyy”)。相比之下,特别是,海洋科学在过去十年中也经历了数据爆炸式增长(“Brett 等人2020”;Guidi 等人2020”)。例如,海洋微生物组的 DNA 测序自 2010 年以来产生了几百 TB 的原始数据,或世界上第一张海底数字地图