XiaoMi-AI文件搜索系统
World File Search System数据
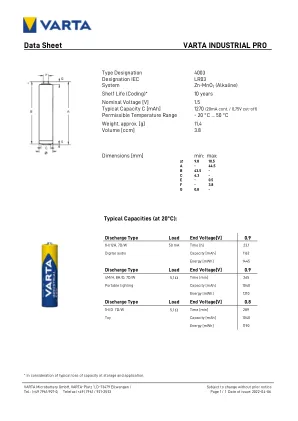
数据表Varta Industrial Pro
安全数据表是职业安全与健康管理局(OSHA)危害通信标准的次级要求,1910.1200子部分29 CFR。此危险通信标准不适用于各种子类别,包括OSHA定义为“文章”的任何内容。根据OSHA的说法,文章是指除流体或粒子以外的制造物品:(i)在制造过程中形成特定形状或设计; (ii)具有最终使用函数(s)的全部或部分取决于其在最终使用过程中的形状或设计; (iii)在正常使用条件下不会释放超过少量的危险化学物质(如本节(d)所述),并且不会对员工构成身体上的危险或健康风险。
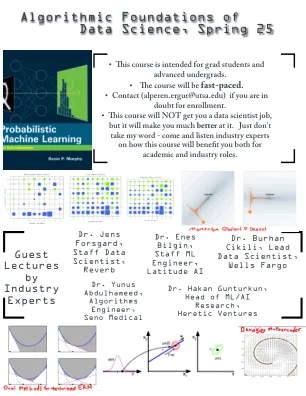
数据科学算法基础,春季25
•本课程旨在针对研究生和高级本科生。•课程将快节奏。•联系(alperen.ergur@utsa.edu)如果您有疑问是否有招生。•本课程不会为您提供数据科学家的工作,但是它会使您更加更好。只是不要说出我的话 - 来倾听行业专家,了解该课程如何使您在学术和行业角色中受益。
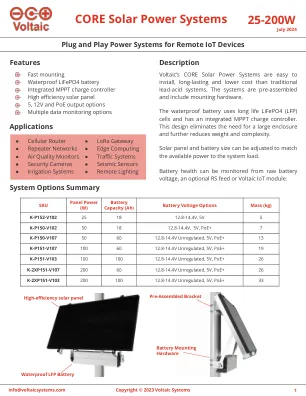

Python和NOQL地下数据的自动化和高级分析:REATE计划信息处理中石油和天然气行业可持续性的创新
在此编码中,国家石油,天然气和生物燃料(ANP)的重新计划在提供有关巴西陆地盆地的全面数据方面起着至关重要的作用。根据Ferreira和Oliveira(2021)的说法,对这些数据的开放访问对于可以改变该行业的技术创新至关重要。这项研究使用与NOSQL数据库集成的Python和Typescript中开发的软件加深了此数据的处理,Melo和Santos(2020)(2020)将这种方法识别为对大型数据的有效管理必不可少的方法。


什么是数据挖掘?
本书从算法的角度介绍了数据挖掘中使用的主要原理和技术。对这些原理和技术的研究对于更好地理解如何将数据挖掘技术应用于各种数据至关重要。本书也是有兴趣在该领域进行研究的读者的起点。我们以有关数据的一章(第2章)开始了本书的技术讨论,该章节讨论了数据质量,数据质量,预专业技术的基本类型以及相似性和相似性的度量。尽管可以快速涵盖此材料,但它为数据分析提供了重要的基础。第3章,关于数据探索,讨论了摘要统计数据,可视化技术和在线分析处理(OLAP)。这些技术提供了快速洞悉数据集的手段。第4章和第5章封面分类。第4章通过讨论决策树分类器和对所有分类重要的几个问题提供基础:过度拟合,绩效评估和不同分类模型的比较。使用此基础,第5章介绍了许多其他重要的分类技术:基于规则的系统,最近的邻居分类器,贝叶斯分类器,人工神经网络,Sup-Port-Port-Port-Port-Port vector Machines和Ensemble Classifier,它们是Classi-

稳态视觉诱发电势中的数据分析 -
摘要 - 电脑摄影仪(EEG)已被广泛用于脑部计算机界面(BCI),这使瘫痪的人能够由于其便携性,高时间分辨率,较高的时间分辨率,易用性和低成本而直接与外部设备进行通信和控制。基于稳态的视觉诱发电位(SSVEP)基于BCI的BCI系统,该系统使用多种视觉刺激(例如计算机屏幕上的LED或盒子)在不同频率上流动的数十年来,由于其快速通信速率和高信号速率和高信号率而被广泛探索。在本文中,我们回顾了基于SSVEP的BCI的当前研究,重点介绍了能够持续,准确检测SSVEP的数据分析,从而可以进行高信息传输率。在本文中描述了主要的技术挑战,包括信号预处理,频谱分析,信号分解,特定规范相关性分析及其变化以及分类技术的空间过滤。还讨论了自发性大脑活动,精神疲劳,转移学习以及混合BCI的研究挑战和机遇。

在环境DNA方法中的最新数据分析用于其适用于可持续的薄壁炉管理
使用海洋环境DNA(EDNA)方法进行的越来越多的研究通过帮助和简化评估被剥削的人群和生态系统状况所需的一些劳动密集型传统调查,显示了其在海洋渔业管理中的潜在应用。Edna接近(即 metabarcoding and Targeed)可以通过提供有关物种组成的信息来支持基于生态系统的薄片管理;侵入性,稀有和/或濒危物种的监视;并提供物种丰度的估计。 由于这些潜在用途和保护科学的潜在用途,在过去几年中,在海洋栖息地中应用EDNA方法的研究数量有所扩大。 但是,在应用管道进行数据分析时,整个研究缺乏一致性,这使得结果很难比较它们。 这种缺乏一致性的部分原因是在原始序列数据的管理中知识不足以及允许比较结果的分析方法引起的。 因此,我们在这里审查EDNA数据处理和分析的基本步骤,以获得声音,可重现和可比的结果,从而提供了一组对每个步骤有用的生物信息学工具。 总的来说,本评论介绍了EDNA数据分析的艺术状态,以促进可持续性的盗版管理中的全面应用。Edna接近(即metabarcoding and Targeed)可以通过提供有关物种组成的信息来支持基于生态系统的薄片管理;侵入性,稀有和/或濒危物种的监视;并提供物种丰度的估计。由于这些潜在用途和保护科学的潜在用途,在过去几年中,在海洋栖息地中应用EDNA方法的研究数量有所扩大。但是,在应用管道进行数据分析时,整个研究缺乏一致性,这使得结果很难比较它们。这种缺乏一致性的部分原因是在原始序列数据的管理中知识不足以及允许比较结果的分析方法引起的。因此,我们在这里审查EDNA数据处理和分析的基本步骤,以获得声音,可重现和可比的结果,从而提供了一组对每个步骤有用的生物信息学工具。总的来说,本评论介绍了EDNA数据分析的艺术状态,以促进可持续性的盗版管理中的全面应用。

消除无形的死亡:全球狂犬病数据的悲惨状态及其对2030年疏忽的可持续发展目标的影响
与其他被忽视的疾病一样,狂犬病的监视数据与准确描述疾病负担的需要是不足的,并且不兼容。在过去的二十年中,进行了估计全球人类狂犬病死亡的核心,结果每年14,000至74,000例。然而,模型参数的不确定性,建模方法的不一致以及全球负担研究中包含的每个国家 /地区的数据质量差异导致最近对狂犬病死亡率的巨大怀疑。缺乏数据不仅限制了狂犬病消除策略的效率和监测,而且严重降低了倡导国际资助机构支持的能力。同时,最脆弱的社区继续遭受可能通过更强大的报道来阻止的死亡。零by 30全球策略消除了2030年消除狗介导的人类狂犬病,建议特有国家采用部门间方法,综合咬合案例管理(IBCM),作为增强监视的成本效益方法。但是,IBCM的有效实施受到了有限能力,资源,知识,技能和对合规性态度等挑战的阻碍。为了解决这个问题,世界卫生组织和反对狂犬病论坛的联合会开发了几种开放式工具,以指导强大的数据收集实践中的国家控制计划,以及在线数据存储库,以实用简化报告并鼓励数据共享。在这里,我们讨论了如何最好地利用当前和未来的计划来改善现有监视工具的实施,并优先考虑有效的数据报告/共享,以优化2030年消除的进度。

案例研究:设置定期报告和 PAR 分析的数据管道
Technovative Consulting 成功帮助这家位于浦那的 NBFC 设计并实施了全面的数据管道解决方案,用于定期报告和 PAR 分析。通过自动化数据工作流程、引入实时跟踪和提高报告准确性,NBFC 能够增强其风险管理、运营效率和决策能力。该解决方案为该公司提供了可扩展、高效的基础设施,不仅改善了其黄金贷款组合的管理,还使其随着业务的扩展而为未来增长做好准备。