XiaoMi-AI文件搜索系统
World File Search System文本

战略管理:文本和案例
Gregory G. Dess是德克萨斯大学达拉斯分校的Andrew R. Cecil管理主席。他的主要研究兴趣是战略管理,组织环境关系和知识管理。他在学术和从业者期刊上发表了许多有关这些主题的文章。他还在各种以从业者为导向和学术期刊的编辑委员会中任职。在2000年8月,他被入选《管理学院名人堂》作为其特许成员之一。DES教授在美国,欧洲,非洲,香港和澳大利亚进行了执行计划。在1994年,他是葡萄牙Oporto的富布赖特学者。2009年,他获得了伯尔尼大学(瑞士)的荣誉博士学位。他获得了华盛顿大学(西雅图)的工商管理博士学位,并获得了佐治亚理工学院的BIE学位。

ldmol:文本到 - 分子扩散模型
以扩散模型的出现作为生成模型的前线,许多研究人员提出了通过条件扩散模型的分子产生技术。但是,分子的不可避免的离散性使扩散模型很难将原始数据与自然语言等高度复杂的条件连接起来。为了解决这个问题,我们提出了一种新型潜在扩散模型,称为文本条件分子的生成。ldmol构建了一种分子自动编码器,该自动编码器可产生可学习且结构上的特征空间,并具有自然语言条件的潜在扩散模型。特别是认识到多个微笑符号可以代表相同的分子,我们采用对比度学习策略来提取特征空间,以了解分子结构的独特特征。ldmol优于文本到整体生成基准的现有基准,建议扩散模型可以在文本数据生成中胜过自回旋模型,而潜在的潜在域则更好。此外,我们表明LDMOL可以应用于下游任务,例如分子到文本检索和文本引导的分子编辑,表明其作为扩散模型的多功能性。

Z 世代在 Discord 上区分人工智能生成的文本和人类撰写的文本的能力
ChatGPT 等生成式人工智能 (AI) 聊天机器人日益流行,对社交媒体产生了变革性的影响。随着人工智能生成内容的普及,人们对网络隐私和错误信息的担忧不断增加。在社交媒体平台中,Discord 支持人工智能集成——这使得其主要的“Z 世代”用户群特别容易接触到人工智能生成的内容。我们调查了 Z 世代的个人 (n = 335),以评估他们在 Discord 上区分人工智能生成文本和人类撰写的文本的能力。调查采用了 ChatGPT 的一次性提示,伪装成在 Discord.com 平台上收到的短信。我们探讨了人口统计因素对能力的影响,以及参与者对 Discord 和人工智能技术的熟悉程度。我们发现 Z 世代的人无法辨别人工智能和人类编写的文本(p = 0.011),而那些自称对 Discord 熟悉程度较低的人与那些自称有人工智能使用经验的人相比,在识别人类编写文本方面表现出更高的能力(p << 0.0001)。我们的结果表明,人工智能技术与 Z 世代流行的沟通方式之间存在微妙的关系,为人机交互、数字通信和人工智能素养提供了宝贵的见解。

ODM:文本图像进一步的对齐预训练方法,用于场景文本检测和发现
近年来,文本图像联合预训练技术在各种任务中显示出令人鼓舞的结果。然而,在光学特征识别(OCR)任务中,将文本实例与图像中的相应文本区域对齐是一个挑战,因为它需要在文本和OCR文本之间有效地对齐(将图像中的文本称为ocr-文本以与自然语言中的文本区分开来),而不是对整体图像内容的全面理解。在本文中,我们提出了一种新的预训练方法,称为o cr-text d估计化m odeling(ODM),该方法根据文本提示将图像中的文本样式传输到统一样式中。使用ODM,我们在文本和OCR文本之间实现了更好的对齐方式,并启用预训练的模型以适应场景文本的复杂和多样化的样式。此外,我们为ODM设计了一种新的标签生成方法,并将其与我们提出的文本控制器模块相结合,以应对OCR任务中注释成本的挑战,并以大量未标记的数据参与预培训。在多个Pub-LIC数据集上进行的广泛实验表明,我们的方法显着地证明了性能,并且在场景文本检测和发现任务中的当前预训练方法优于当前的预训练方法。代码在ODM上可用。
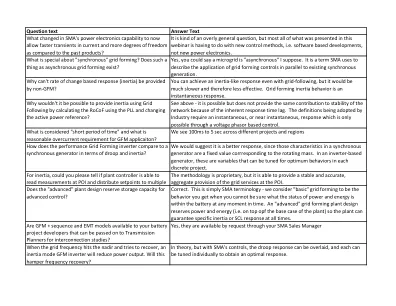
问题文本回答文本,SMA的电力电子能力中发生了什么变化,以便在
我会将其构架为造成需求的市场条件。下垂和惯性是不同的反应,每个反应都对任何给定情况都对网格稳定产生独特的影响。当我们退役传统的综合产生植物并增加基于网格的逆变器的发电量时,网格正朝着较弱的条件趋势。因此,我们需要替换同步生成的特征(即惯性和SCL),任何给定的项目位置中的确切“配方”都是该项目的特定的。因此,可以单独启用并调整项目需求的下垂和惯性行为是有利的。供应链能够在一年左右的时间内为美国所有电池提供大量份额的GFM逆变器吗?GFM要求应该放慢吗?

文本分析和自动索引 - SIGIR
本书的前两章介绍了现有信息检索系统的设计和操作。在信息检索所需的所有操作中,最关键、也可能是最困难的操作是分配适当的术语和标识符,以表示集合项的内容。这项任务称为索引,通常由训练有素的专家手动执行。在现代环境中,索引任务可以自动执行。本章涉及用于自动索引的技术以及这些技术的效果和性能。首先描述基本的索引任务,然后比较手动和自动索引。然后研究选择好的内容术语和根据术语的假定值分配权重的基本技术,以便进行内容识别。然后提出了一种简单的自动索引程序,以及由使用术语短语和同义词库类别组成的改进。还简要介绍了语言和概率技术在自动索引中的使用。最后,包括评估输出以证明所提出的索引技术应用于小样本集合的有效性。


节能的文本转音频 AI
AudioLDM 设计概览,用于文本到音频生成(左)和文本引导的音频处理(右)。在训练期间,潜在扩散模型 (LDM) 以音频嵌入为条件,并在 VAE 学习的连续空间中进行训练。采样过程使用文本嵌入作为条件。给定预训练的 LDM,零样本音频修复和风格迁移以反向过程实现。前向扩散块表示用高斯噪声破坏数据的过程(参见公式 2)。来源:arXiv (2023)。DOI:10.48550/arxiv.2301.12503

人工智能文本生成使用政策
生成式人工智能辅助 (GAIA) 政策 我们欢迎人工智能语言生成工具(统称为大型语言模型或 LLM)进入学习过程,以保持公平、优化学生技能培养和尊重相关利益相关者的观点。这些包括我们作为渴望学习和建立事业的学生的观点,以及送我们上大学的家人、负责教授我们重要技能的教授、有责任用文凭证明我们能力的大学、因为我们的能力和品格而投资于我们的未来雇主以及缺乏宝贵资源特权的同事的观点。为此,GAIA 政策对 LLM 的包容性方法采取了一些常识性限制。
