XiaoMi-AI文件搜索系统
World File Search System新思

基思·史蒂文森博士
摘要:由于世界人口不断增长,能源需求不断增加,以及对可再生能源替代品多样化的需求日益增加,开发先进材料和技术以有效地将能源直接转化为电能变得至关重要。然而,在成功实施任何数量的竞争能源技术(例如基于硅的太阳能电池以外的技术)之前,仍然存在巨大的科学挑战。目前正在探索的材料、界面和设备架构很难通过集合平均、批量实验方法来探究,因为它们不表现出长程有序或同质性,包含独特的纳米形态特征,并且具有不均匀的化学成分和缺陷化学。此外,这些材料和界面具有动态“反应性”,其性能在使用过程中会显著下降,从而限制了它们的循环寿命和最终的商业化前景。本次演讲将重点介绍我们为开发高分辨率、空间分辨的方法来研究钙钛矿太阳能电池所做的努力。我们开发了一些方法来研究功能设备中不同深度的埋藏界面。这些实验揭示了不同层之间的大量混合[1-3]。另一个设计参数是通过用 Br 部分取代 I - 来调整钙钛矿化学的带隙,以扩大其在串联太阳能电池和 LED 中的应用。剩下需要解决的唯一关键问题是它们在工作条件下的长期稳定性较差,特别是通过分裂成富含 I 和 Br 的相而导致的光化学降解。要充分抑制这一过程,需要彻底了解其潜在现象。在本次报告中,我们将详细研究化学计量和非化学计量混合卤化物 CsPbI 3-x Br x 中的电场诱导和光诱导相变。使用 ToF-SIM 和原位原子力显微镜,可以可视化光照下卤化物相偏析的实时动力学。富含 I 的相主要沿晶界偏析,而晶粒本体仍然富含 Br。我们提出,通过空间分辨成像方法,光生 Pb 0 和 I 3 - 物种被选择性地从晶粒本体排出到晶粒边界界面。 简历:史蒂文森教授于 1997 年在犹他大学亨利怀特教授的指导下获得博士学位。随后,他在西北大学 (1997-2000) 担任博士后;并在 2000 年至 2015 年期间在德克萨斯大学奥斯汀分校担任教授。目前,他正在领导俄罗斯莫斯科一所新的研究生大学 (斯科尔科沃科学技术研究所) 的发展,他曾担任该研究所的教务长、全职教师和能源科学与技术中心 (CEST) 的创始人。2019 年,斯科尔科沃科技大学成为世界上最年轻的大学,也是俄罗斯联邦唯一一所进入自然指数年轻大学前 100 名的大学。史蒂文森的研究兴趣旨在阐明和控制对许多新兴的能源存储和能量转换技术至关重要的固/液界面化学。迄今为止,他已经在这个领域发表了 350 多篇同行评审的出版物、13 项专利和 6 本书的章节。他曾获得美国国家科学基金会 CAREER 奖(2002 年)、南方研究生院会议新学者奖(2004 年)、电分析化学学会青年研究员奖(2006 年)、Kavli 研究员(2012 年)、电分析化学学会 Charles N. Reilley 奖(2021 年)和电化学学会 David C. Grahame 奖(2023 年)。史蒂文森的研究兴趣旨在阐明和控制对许多新兴的能源存储和能量转换技术至关重要的固/液界面化学迄今为止,他已在该领域发表了 350 多篇同行评审出版物、13 项专利和 6 本书章节。他曾获得 NSF CAREER 奖(2002 年)、南方研究生院会议新学者奖(2004 年)、电分析化学学会青年研究员奖(2006 年)、Kavli 研究员奖(2012 年)、电分析化学学会 Charles N. Reilley 奖(2021 年)和电化学学会 David C. Grahame 奖(2023 年)。

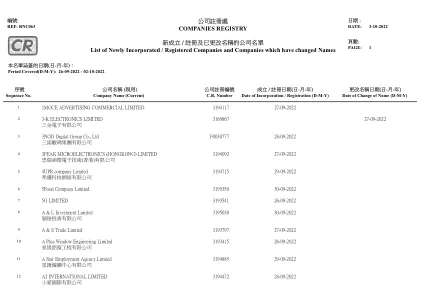
新成立/ 注册及已更改名称的公司名单List of Newly ...
成立/ 注册日期(日-月-年) CR Number Date of Incorporation / Registration (DMY) Date of Change of Name (DMY) Company Name (Current)

新成立/注册及已更改名称的公司名单新列表... div>
本报告中的每个记录都以6个数据字段的形式显示。每个数据字段通过“选项卡”分开。6个数据字段的顺序是“序列编号”,“当前公司名称为英文”,“当前公司名称中文”,“ B.R.编号“”,“合并 /注册日期(D-M-Y)”和“名称更改日期(D-M-Y)”。< / div>
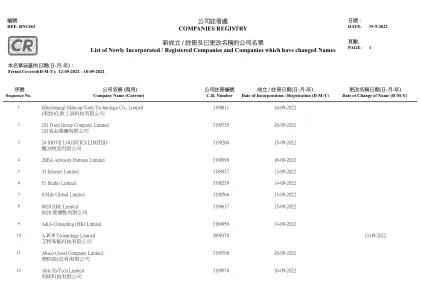
新成立/注册及已更改名称的公司名单新列表... div>
成立 /注册日期(日-月-年)c.r。< / div>编号合并 /注册日期(D-M-y)名称更改日期(D-M-y)公司名称(当前)< / div> < / div>

新成立/ 注册及已更改名称的公司名单List of Newly ...
1. 101 BUSINESS CONSULTANT LIMITED 101 企业顾问有限公司305422102-06-2021 Nil 2. 101 SYSTEM LIMITED 305302231-05-2021 Nil 3. 17 Play Limited 17游玩有限公司305376201-06-2021 Nil 4. 2105 Chambers Limited 305497904-06-2021 Nil 5. 247 Wine Trading Limited 247红酒贸易有限公司305360901-06-2021 Nil 6. 360 Data Dynamics Limited 305320331-05-2021 Nil 7. 3883 LIMITED 305342901-06-2021 Nil 8. 3A Interior Design Limited 优品设计工程有限公司305362401-06-2021 Nil 9. 3Brothers Limited 三哥有限公司305513704-06-2021 Nil 10. 3NV Technology Limited 三环科技有限公司305370301-06-2021 Nil 11. 42 Hong Kong Limited 305513004-06-2021 Nil 12. 4JH Company Limited 朗琦企业有限公司305419402-06-2021 Nil 13. 520 Coliving Limited 爱共居有限公司305501504-06-2021 Nil 14. 858 LIMITED 305343001-06-2021 Nil 15. 99 Loyalty Limited 1903220Nil 31-05-2021 16. A Lai Catering Holding Limited 阿荔餐饮控股有限公司305332031-05-2021 Nil 17. A List HK 3 Limited 305318031-05-2021 Nil 18. A List HK 4 Limited 305318331-05-2021 Nil 19. A&C Asia Limited 2633296Nil 01-06-2021 20. A-ARYA INTERNATIONAL TRADING CO., LIMITED 阿涯国际贸易有限公司305357501-06-2021 Nil 21. ABACUS PROPTECH LIMITED 305309531-05-2021 Nil 22. ABACUS ROBOTICS LIMITED 305310131-05-2021 Nil 23. Abana Decor Limited 雅笆.纳凯有限公司305351301-06-2021 Nil 24. ABC Digital Agency Limited 1157648Nil 04-06-2021

新成立/ 注册及已更改名称的公司名单List of Newly ...
本报告的每一条记录都以一行显示,包含 6 个数据字段。每个数据字段以“制表符”分隔。6 个数据字段的顺序为“序号”、“现时公司英文名称”、“现时公司中文名称”、“商业登记号码”、“成立/注册日期 (DMY)”和“更改名称日期 (DMY)”。


免疫和细胞治疗新进展学术会议
肿瘤衍生的外泌体在将肿瘤分子转移到相邻细胞中起着关键作用,从而导致其表型改变并促进肿瘤生长,转移,耐药性和调节肿瘤微环境。我们对恶性脑肿瘤的研究表明,胶质母细胞瘤干细胞(GSC)通过细胞外囊泡(EVS)将其货物转移到肿瘤非茎细胞或正常细胞中,从而导致具有治疗性耐药性和癌性特性的肿瘤干细胞亚型的发展。tzab-001,一种由GSC衍生的细胞外囊泡产生的单克隆抗体,通过阻断EV的细胞间传播,可以显着降低肿瘤干细胞的治疗性耐药性。TZAB-001在神经胶质瘤中识别的蛋白质比其他肿瘤高了60倍。免疫组织化学染色和蛋白质印迹表明,TZAB-001抗体明确识别人GBM干细胞,肝癌细胞系HEPG2,胰腺癌细胞PANC-1和肺癌细胞系A549,但不是正常脑细胞。结果表明,TZAB-001具有肿瘤诊断,癌症干细胞的CART免疫疗法以及ADC药物开发的应用潜力,以提高其功效。

Kamishinko 和其他 183 件物品 - 防卫省/自卫队
7. 注意事项 (1) 投标人资格 A. 投标人不得属于《预算、会计及审计法》第 70 条的规定。此外,未成年人、被监护人或接受协助的人,即使已经取得订立合同所必需的同意,也属于同一条款内有特殊事由的情况。 (一)不属于预算会计审计法第七十一条规定情形的。 2022、2023、2024年度国防部竞标资格(全部统一资格)“货物销售”项目取得D级以上资格者。 (有资格参加竞标的注册公司必须在开标前提交资格审查结果通知书副本。) (e)目前不受合同官员等暂停投标的限制。在审查投标指南和合同条款后,投标人将在投标文件中声明承诺排除有组织犯罪集团。目前不受防卫政策局局长、采购、技术和后勤局局长或陆上自卫队参谋长的提名暂停影响,根据“指导方针”暂停设备等及服务采购提名”。与前项停止指定对象有资本或人身关系,且无与国防部订立货物买卖契约或制造、承包契约者,与该人同类的服务。事物。 Q 原则上,目前被暂停投标资格的人员不允许进行分包。但相关部委提名暂停机关认定有确实不可避免的情况时,不在此限。