XiaoMi-AI文件搜索系统
World File Search System显着性

Federico Magliani信息技术老师
我与CNN合作,利用转移学习并应用微调以提高检索的最终准确性。我的焦点开了大规模检索,试图减少检索时间,但要保持较高的检索性能。我提出了一种基于LSH预测的新索引方法,称为索引袋(BOI)。我也对图像检索目的的注意力/显着性方法感兴趣。
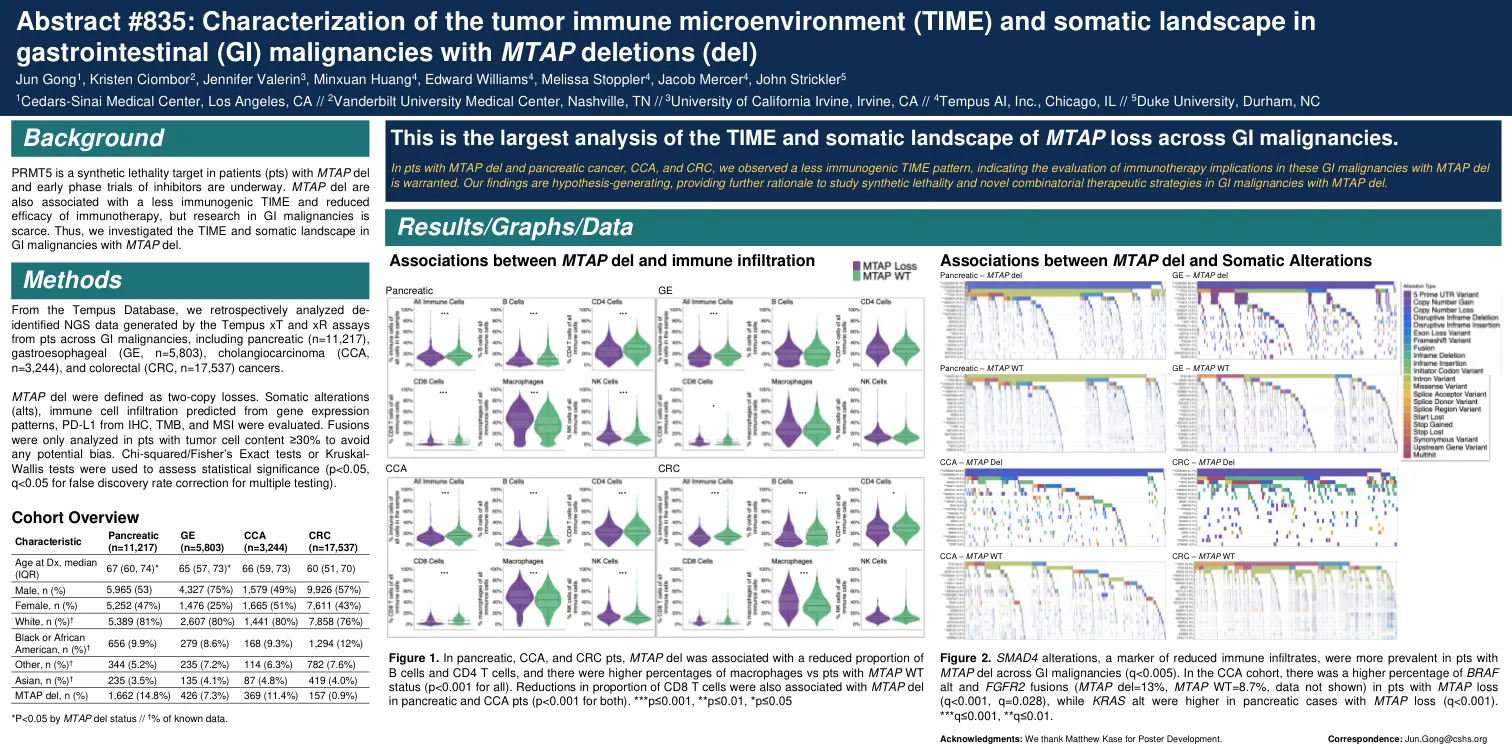
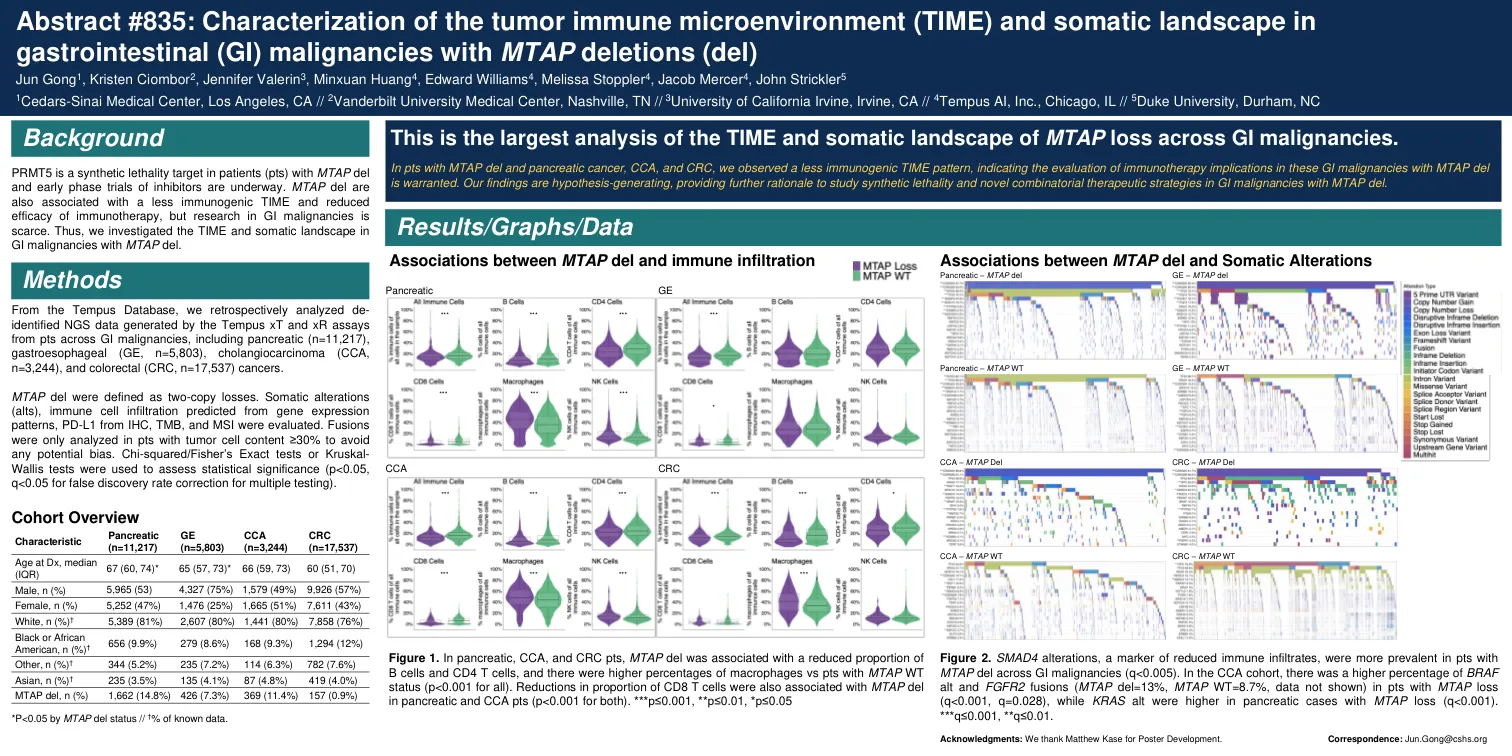
肿瘤免疫微环境的表征(...
mtap del定义为两拷贝损失。体细胞改变(ALTS),从IHC,TMB和MSI的基因表达模式,PD-L1预测的免疫细胞浸润。融合,以避免任何潜在的偏见。卡方/Fisher的精确测试或Kruskal-Wallis检验用于评估统计显着性(p <0.05,Q <0.05,用于用于多次测试的错误发现率校正)。

衍生自HIPSC的生物工程血管
图1 HIPSC用具有常见MSC 324标记的MSC表型分化为细胞。显示了MSC分化协议的示意图(a)。在HIPSC-IMSCS(B)的分化过程中,观察到326(B)的MSC标记基因THY1(CD90),NT5E(CD73)和ENG(CD105)的折叠基因表达325。 常见MSC阳性标记的直方图为327(c)(C),并且在36天36天后,也可以通过流式细胞仪(C-I至C-III)注意CD90,CD73和CD105阳性的细胞百分比,当IMSC被得出时,也可以通过流式细胞仪(C-I至C-III)进行注意。 329数据显着性表示为***p≤0.001和****p≤0.0001(n = 3)。 330折叠基因表达325。常见MSC阳性标记的直方图为327(c)(C),并且在36天36天后,也可以通过流式细胞仪(C-I至C-III)注意CD90,CD73和CD105阳性的细胞百分比,当IMSC被得出时,也可以通过流式细胞仪(C-I至C-III)进行注意。329数据显着性表示为***p≤0.001和****p≤0.0001(n = 3)。330
遗传性癌症测试申请表2025.01.07
mtap del定义为两拷贝损失。体细胞改变(ALTS),从IHC,TMB和MSI的基因表达模式,PD-L1预测的免疫细胞浸润。融合,以避免任何潜在的偏见。卡方/Fisher的精确测试或Kruskal-Wallis检验用于评估统计显着性(p <0.05,Q <0.05,用于用于多次测试的错误发现率校正)。

基于纳米孔的RSV整个基因组测序
(棕色),只有G基因(深红色)和缺失的G和F基因测序(也称为深绿色的“其他”),分别由DNA纯化(紫色)救出。在基因组位置(蓝色)和(红色)PCR扩增子清理的基因组位置的测序代表性RSV-A(E)和RSV-B(f)的覆盖深度。bar图显示了NGS的折叠变化读取的映射到未经PCR扩增子纯化的未经和带有PCR扩增的放大器的测序样品和高(g)和高(H)浓度的RSV参考基因组。将洗涤的PCR扩增子的库的 ngs读取为标准化,并表示为对未洗的PCR扩增子的折叠更改,该折叠设置为1。。 数据表示为平均值±SD。 进行 t检验分析的统计显着性。 p值小于0.05被认为具有统计学意义,并将其标记为 *。ngs读取为标准化,并表示为对未洗的PCR扩增子的折叠更改,该折叠设置为1。数据表示为平均值±SD。t检验分析的统计显着性。p值小于0.05被认为具有统计学意义,并将其标记为 *。
![arXiv:2202.11690v1 [q-bio.NC] 2022 年 1 月 12 日](/simg/7\7d0d54ea9ea1ba10858600a879490fb573f5c9aa.webp)
arXiv:2202.11690v1 [q-bio.NC] 2022 年 1 月 12 日
摘要。通过深度学习进行脑年龄 (BA) 估计已成为脑健康的强大而可靠的生物标记,但神经网络的黑箱性质并不容易洞察脑老化的特征。我们训练了一个 ResNet 模型作为 BA 回归器,该模型基于来自 524 人的小型横断面队列的 T1 结构 MRI 体积。使用逐层相关性传播 (LRP) 和 DeepLIFT 显着性映射技术,我们分析了训练后的模型,以确定与网络最相关的脑老化结构,并在显着性映射技术之间进行比较。我们展示了在衰老过程中对不同脑区相关性归因的变化。对脑区相关性归因的三部分模式出现了。一些区域随着年龄的增长而相关性增加(例如右侧颞横回);一些区域随着年龄的增长相关性降低(例如右侧第四脑室);其他区域在各个年龄段都始终相关。我们还研究了大脑年龄差距 (BAG) 对脑容量内相关性分布的影响。希望这些发现能够为正常大脑衰老提供临床相关的区域轨迹,以及比较大脑衰老轨迹的基线。

一项受控和随机临床试验
52名参与者,年龄从18至25岁,选择了硫化硫化物(H 2 S)112 ppb。他们分为4组(n = 13):第1组:舌头刮刀;第2组:用APDT治疗一次;第3组:含有乳酸乳杆菌WB21(6.7 x 10 8 CFU)和木糖醇(280mg)的益生菌胶囊,每天3次,持续14天;第4组:用APDT和益生菌胶囊治疗一次14天。用气体摄影(临床评估)和微生物样品中的从APDT前后的舌头以及7、14和30天后收集。 临床数据未能遵循正态分布;因此,在必要时,使用Kruskal-Wallis检验(独立度量)和Friedman ANOVA(依赖度量)进行了比较。 对于微生物数据,由于数据未能遵循正态分布,因此使用Dunn的后测试进行了Kruskal-Wallis秩和测试。 显着性水平为α= 0.05。从APDT前后的舌头以及7、14和30天后收集。临床数据未能遵循正态分布;因此,在必要时,使用Kruskal-Wallis检验(独立度量)和Friedman ANOVA(依赖度量)进行了比较。对于微生物数据,由于数据未能遵循正态分布,因此使用Dunn的后测试进行了Kruskal-Wallis秩和测试。显着性水平为α= 0.05。

物流管理实践对卢旺达组织绩效的影响 -
来自基加利大学摘要 - 研究的目的是研究物流管理对卢旺达大猩猩物流有限公司绩效的影响。具体目标是评估物流信息系统对卢旺达大猩猩物流有限公司的性能的影响,以找出订单过程管理对卢旺达大猩猩物流有限公司的绩效的影响,并找出运输管理对卢旺达Gorilla Logistics绩效的影响。这项研究使用了描述性和相关研究设计,研究样本大小的104名受访者参与了卢旺达大猩猩物流有限公司的日常物流管理。受访者。使用问卷收集数据,并使用百分比,平均值和标准偏差进行分析。回归分析还用于检验研究的假设。从H0获得的发现(零假设)1表明,f检验值为61.384,显着性水平为0.000,显着性水平为0.000; p值<0.05,f检验很重要。因此,我们得出结论,模型很好。因此,我们不能接受HO1,该HO1指出,物流信息系统对卢旺达大猩猩物流有限公司的性能没有显着影响。从H02的发现显示F检验值为803.254,显着性水平为0.000,显着值为0.000;由于获得的p值<0.05,f检验很重要,因此我们得出结论,模型是好的。1。因此,我们不能接受HO2,该HO2指出,订单过程管理对卢旺达大猩猩物流有限公司的绩效没有显着影响。从H03的发现表明,F检验值为129.093,显着性水平为0.000,而获得的P值为0.000,而所获得的P值<0.05,F检验显着;因此,我们得出结论,模型很好。因此,我们不能接受H03,该H03表明运输管理对卢旺达大猩猩物流有限公司的绩效没有显着影响。HO4的总体发现表明,F检验值为363.022,显着性水平为0.000,而所获得的P值<0.05,f检验<0.05,f检验很重要,因此结论是模型良好的结论。因此,研究人员无法接受HO4,该HO4表明物流管理对卢旺达大猩猩物流有限公司的绩效没有显着影响。关键字:效果,物流,管理,组织绩效。简介物流管理对于将组织的绩效与供应链流程集成至关重要,以实现对客户依从性的改进。形成感知性的观点,物流管理生动地影响了组织的绩效,并通过订单处理管理,库存管理,运输管理,处理管理和包装以及能力网络设计均已掌握,这都是考虑因素的事物,并对客户满意度产生了重大影响(Hiourrini等人,2015年)。在过去的几十年中,已经出现了研究,以调查物流管理在满足客户需求和需求中的作用(Nyaberi等,2014)。对这一研究趋势的基本假设是,成功管理不同的物流活动,包括运输管理,订单流程管理,物流管理信息系统,库存管理,仓库运营,材料需求计划,购买,购买,质量控制,最终输出,处理和包装过程的物理分配,处理和包装过程在创造和增强组织竞争方面具有至关重要的作用(Cavinato Al。物流在支持组织中起着关键作用,因为他们像业务实践一样努力寻求更有效的管理系统。效率低下的管理系统以及效率低下的内部管理将使组织以最短的价格在最短的可行时间范围内对客户的需求做出反应,包括质量水平,不满足客户的期望,并希望组织对竞争对手的竞争不利的状况对抗竞争对手(Cozzolino,2012年)。

HR计划保留员工参考ZomatoHR计划保留员工参考Zomato
保留人力资源计划的平均百分比为33.2%,而员工满意度的平均百分比为42.4%。鉴于这些平均值的差异和李克特量表的分布,我们观察到员工满意度往往高于保留中的人力资源计划。如果我们考虑显着性水平和其他统计措施(此处未详细说明),则明显的差异表明拒绝零假设。因此,接受替代假设,表明保留中的人力资源计划显着影响员工满意度。

新的全球内部审计标准
在提供审核时,标准要求必须根据显着性(标准14.3)优先考虑各个发现,并且必须根据参与目标(标准14.5)包括参与性结论。不需要评级/排名,但建议进行评级/排名。在结论中,任务的结果必须与(参与)目标有关,反映审计师的专业判断,并证明对组织的影响以及评估过程的有效性。此外,还需要进行评估,以确定是否根据情况和既定方法将风险报告为发现。