XiaoMi-AI文件搜索系统
World File Search System朗冈区

脑电图(EEG)中言语回忆和非回忆间隔的分类
脑机接口 (BCI) 研究已开始用于从脑电图 (EEG) 中识别语音想象过程中的回忆音节。目前,很难从 EEG 数据中识别出真实的回忆持续时间。因此,通常使用不准确的回忆数据(包括非回忆持续时间或通过视觉确定频谱轮廓标记的回忆部分)来识别回忆的音节。由于视觉音节标记耗时费力,因此希望区分正确的语音想象片段的过程能够自动化。在本文中,我们构建了由语音想象片段和非回忆片段组成的每个模型以获得真正的音节片段。我们通过视觉判断从带有音节标记的语音想象/非回忆数据中提取复倒谱,并使用这些特征识别语音想象/非回忆片段。最后,我们报告了通过 10 倍交叉验证的分类结果。

金达尔电力有限公司 2 号地块,第 32 区古尔冈
请愿书编号 199/MP/2021 成员: Shri IS Jha,成员 Shri Arun Goyal,成员 Shri PK Singh,成员 命令日期:2022 年 7 月 8 日 涉及事项:根据 2003 年《电力法》第 79(1)(f) 条和请愿人与被告于 2012 年 6 月 29 日和 2013 年 8 月 23 日签订的购电协议第 8 条,提出请愿,要求追讨请愿人每月账单上的逾期付款附加费。 以及 关于 Jindal Power Limited Plot No. 2, Sector-32 Gurgaon- 122001, Haryana ......请愿人
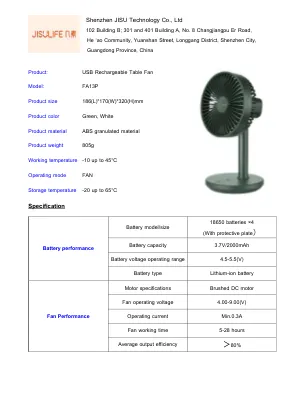
深圳JISU技术有限公司规范
深圳JISU Technology Co.,Ltd 102 Building B; 301和401建筑物,编号8 Changjiangpu Er Road,He'AO社区,Yuanshan街,朗冈区,深圳市,广东省,中国广东省

讲故事比赛 - 古尔冈
● 国家级:地区级获奖者将由专家委员会进行数字评估。视频时长和大小指南:2-3 分钟,不超过 2 MB 请注意,超过指定时长或大小限制的视频将不被接受。视频提交必须符合这些要求,以避免比赛期间出现技术问题。提交视频后,学校将为入选学生注册参加地区级比赛。我们鼓励所有学生参加这项激动人心的比赛,展示他们讲故事的才华。如有任何疑问,请联系班主任。感谢您一直以来的支持。诚挚问候

古尔冈地铁有限公司
现有的快速地铁已规定在现有的 Mousari Avenue 地铁站连接上行线(朝 56 区方向)的新走廊,并在 Belvedere 地铁站连接下行线(从 56 区开始)。M/S RITES 为该项目编制了详细设计报告,考虑到即使在实施的新线路上也允许使用 2.8 米宽度的快速地铁车厢。但印度政府不同意 2.8 米的车厢宽度,新项目已批准使用 2.9 米的标准车厢宽度。GMRL 正在研究在现有快速地铁轨道上运行 2.9 米宽度车厢的问题,反之亦然。但是,研究并提出使现有线路适合在现有线路上运行 2.9 米宽度车厢的列车的方法,反之亦然,这属于总咨询合同的范围。甚至这类工作的成本核算也属于总咨询合同的范围。此项研究将由 GC 在 LoA 签发之日起 4 个月内按照本合同中提议的人力进行,且 GMRL 无需承担任何额外费用。

藤崎-冈本的后量子验证
证明是有缺陷的 [10]。最近,发现了对 ISO 标准化分组密码模式 OCB2 [25] 的攻击 [24],尽管 [31] 认为 OCB2 是安全的。虽然严格且结构良好的证明风格(例如,使用 [10, 35] 中提倡的游戏序列)可以减少隐藏错误和不精确的可能性,但仍然很难写出 100% 正确的证明。(特别是当使用随机预言 [13] 或倒带 [42, 45] 等证明技术时。)尤其是如果证明中的错误发生在看似非常直观的步骤中,读者很可能也不会发现这个错误。在后量子安全(即针对量子对手的安全性)的情况下,这个问题更加严重:后量子安全证明需要推理量子算法(对手)。我们的直觉是由对经典世界的经验所塑造的,而对量子现象的直觉很容易是错误的。这使得看似合理但不正确的证明步骤在后量子安全证明中特别容易不被发现。简而言之,为了确保后量子安全证明的高可信度,仅仅由人来检查是不够的。相反,我们提倡形式化(或计算机辅助)验证:安全证明由检查每个证明步骤的软件来验证。在本文中,我们介绍了第一个这样的形式化验证,即由 H¨ovelmanns、Kiltz、Sch¨age 和 Unruh [23] 分析的 Fujisaki-Okamoto 变换 [18] 的变体。


沃尔夫冈·A·沃尔(教授、博士、工程师)
力学(IACM)2012 - 2016 莱布尼茨超级计算中心咨询委员会成员 2012 - 2020 ECCOMAS 执行委员会成员(增选)2013 - 2016 德国计算力学协会 (GACM) 主席 2014 - 2017 TUM 生物工程学院创始董事会成员 2014 – 格拉茨工业大学(奥地利格拉茨工业大学)研究与技术委员会成员 2015 – 奥地利科学院海外通讯院士 2015 - 2017 国际流体数值方法杂志主编 2015 - 2020 ERC 高级资助小组成员(后任小组副主席)2016 – TUM 任命和终身教职委员会成员 2017 – 国际机械科学中心 (CISM) 校长意大利乌迪内 2017 年 – 巴伐利亚州科学与人文学院院士 2019 年 – 亥姆霍兹格斯塔赫特中心 (HZG,材料与海岸研究中心) 技术科学委员会成员 2020 年 – 亥姆霍兹中心 Hereon GmbH 技术科学委员会主席 2021 年 – 慕尼黑生物医学工程研究所 (MIBE) 成员,TUM 2021 年 – 慕尼黑机器人与机器智能研究所 (MIRMI) 成员,TUM 2021 年 – 慕尼黑数据科学研究所 (MDSI) 核心成员,TUM 2022 年 – 奥地利研究基金会指导讲师 2022 年 – 材料、能源与过程工程研究所 (MEP) 核心成员,TUM 2022 年 – 莱布尼茨超级计算中心 (LRZ) 顾问委员会成员 2023 年 – 巴伐利亚州科学与人文学院总统战略顾问委员会成员

语音回忆过程中脑电图回忆间隔的估计
图4显示了使用20倍交叉验证估计每个受试者的回忆间隔的结果。在图 4 中,横轴是时间,纵轴是来自 5 个受试者的 200 个样本(总共 1000 个样本)的准确率。红框内是语音回忆部分。前文研究 [2] 中的方法(图 4 中的蓝线)的准确率在语音回忆片段之间下降到 0.2,而本文提出的方法(图 4 中的橙线)则达到了 0.8 的稳定准确率。 从这些结果可以看出,可以说所提出的方法对于估计回忆间隔是有效的。然而,当我们观察所提出的方法在语音回忆部分之外的准确度时,我们发现与以前的研究相比,该方法将语音回忆部分之外的部分估计为回忆率的情况更为常见。这被认为是由于大脑中噪音的影响。因此,我们旨在通过将增加的 10 个样本应用于所提出的方法来减少这种噪音。结果就是图4中的绿线。在保持回忆部分的准确度的同时,非回忆部分的准确度得到了提高。基于这些结果,我们研究了所提出方法的最佳添加次数。结果如图5所示。图 5 显示了所有受试者对每个加法数字的准确率。蓝线表示整个时间内的平均准确率,橙线表示回忆期间的最大准确率。横轴是添加的样本数量,纵轴是准确率。通过添加 sigma,回忆部分的准确率得到了提高,达到了约 90%。另外,10 次添加等于 1 个样本。
