XiaoMi-AI文件搜索系统
World File Search System检查和

自主 - 保险箱 - 检查和诊断 - ...
美国政府最终用户:Oracle计划(包括任何操作系统,集成软件,任何已嵌入,安装或在交付的硬件上激活的程序,以及此类程序的修改)和Oracle计算机文档或美国政府最终用户提供或访问的其他Oracle数据是“商业计算机软件”,“商业计算机软件”,“商业计算机软件文档”,“商业计算机软件”,“商业计算机软件”,“有限的权利数据”或“有限的权利”适用于适用于适用的适用性,或者适用于适用性的适用性,并适用于适用于适用性。因此,使用,复制,重复,释放,显示,披露,修改,衍生作品的准备和/或适应i)Oracle程序(包括任何操作系统,集成软件,嵌入,安装或激活的任何程序,在此类程序中嵌入或激活的任何程序,对此类程序的限制和其他限制),III和/或III IS IS III和/或/或/或/或/或/或/或/或/或/或/或/或/或/或/或/ii ii III),IS或/或/或/或/或/或/或/或/或/或/或/或III III IS IIS)在适用的合同中。管理美国政府使用Oracle Cloud Services的条款由适用的此类服务的合同定义。没有其他权利授予美国政府。

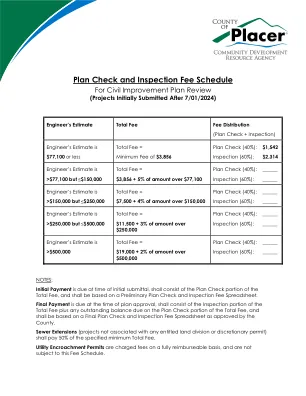
危险品检查和验收清单
Error 500 (Server Error)!!1500.That’s an error.There was an error. Please try again later.That’s all we know.

CSP检查和测试指南
这些准则提供了有关符合条件的消费者在构建CSP系统结束时将要执行的检查和测试程序的信息,以将其连接到KSA的分销网络。这些准则向测试工程师和承包商提供了技术知识和知识,以帮助他们成功进行调试。SEC将永远不会负责检查以下准则的执行,而SEC始终只对会影响连接点的分销网络的设备感兴趣。免责声明承包商,顾问和符合条件的消费者是对Reg系统和调试中的一切的最终负责。sec将根据其内部清单检查和委托这些系统,仅重点关注影响分销网络和连接点的组件和设备。参考批准的WERA法规和SEC连接过程,在名为“ Reg Connection”阶段的步骤3中执行了检查和测试。SEC在此阶段的职责将仅限于以下内容:


研究,检查和入学规则
(4)核心课程第一年的研究为学生提供了从不同的学科角度理解,分析和评估公共政策的基本知识,工具和技能,并在当代数据科学中处理和使用数据的基础。学生获得政策制定,法律和经济学的基础;获取数据科学的基础;并了解用于数据收集,转换和分析的各种方法和技术,以及它们在公共,私人或非营利性设置中的适用性(模块1-3)。专业发展模块通过为学生提供对积极参与公共政策和数据科学领域的机构的日常工作的见解,并通过发展和磨练其专业技能(模块4)来补充这一基础(模块4)。

基于成本的风险分析,以确定检查和恢复...
摘要 — 本文旨在开发一个成本率函数 (CRF),以确定正在老化且故障隐藏的飞机可修复部件的最佳检查和修复间隔和频率,即可通过检查或按需检测。本文考虑了两种流行的策略,即故障查找检查 (FFI) 和 FFI 与恢复操作的组合 (FFI+Res),用于“非安全影响”和“安全影响”类别的隐藏故障。考虑了与旧如旧 (ABAO) 的检查有效性和与新如新 (AGAN) 的恢复有效性。如果由于检查发现而进行维修,则考虑与旧如旧的维修有效性。所提出的方法考虑了检查和维修时间,并考虑了与检查、维修和恢复相关的成本,以及由于无法使用飞机(维修停机时间)而造成的潜在损失。它还考虑了因发生多重故障而导致事故相关的成本。本研究中使用的风险约束优化方法基于设备在检查间隔(MFDT)内未运行的平均时间分数和恢复期内的平均间隔不可用行为。在操作限制的情况下,当无法移除设备进行恢复,或者需要使用设备的时间超过预期运行时间时,本文介绍了一种分析延长恢复间隔的可能性和条件的方法,同时满足风险约束和业务要求。索引术语 — 成本率函数、维护策略组合、故障查找检查、隐藏故障、检查间隔、平均分数死区时间、多重故障、MSG-3、恢复任务、风险约束优化、间隔延长。注释:

隐性指纹检查和人为因素 - GovInfo
1 Barnes, J. “历史。”在《指纹手册》中。美国国家司法研究所,2011 年。Cole,S. 嫌疑人身份:指纹识别和犯罪识别的历史。哈佛大学出版社,2001 年。 2 Mnookin,J. “DNA 分析时代的指纹证据。”布鲁克林法律评论,67(2001):13。 3 例如,R. v. Smith,2011 EWCA Crim. 1296;Bertino,A. 和 P. Bertino。法医科学:基础与调查。西南教育出版社,2009 年(Stephen Cowans 案);美国司法部监察长办公室。对 FBI 对 Brandon Mayfield 案处理的审查(未分类和删节版)。美国司法部,2006 年 3 月;Sweeney,C。“检察总长将在 Shirley McKie 指纹调查前出庭。”泰晤士报,2008 年 10 月 21 日。 4 例如,Leveson,B。《刑事法庭中的专家证据——问题》,致法医学会的演讲,伦敦大学国王学院,2010 年 11 月 18 日。有关具体案例的讨论,请参阅第 6 章。 5 Sanders,M. 和 E. McCormick。《工程和设计中的人为因素》,第 7 版。麦格劳-希尔公司,1993 年。 6 美国国家科学院、医学研究所、美国医疗质量委员会。《人非圣贤,孰能无过:建立更安全的医疗体系》。美国国家科学院出版社,1999 年。

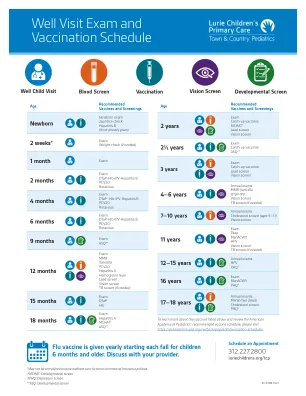
健康检查和疫苗接种时间表
要了解有关上述疫苗的更多信息并查看美国儿科学会推荐的疫苗接种时间表,请访问https://publications.aap.org/redbook/pages/Immunization-Schedules。