XiaoMi-AI文件搜索系统
World File Search System泰米尔语

2021/22 南非
大约 28.07% 的人口(1701 万人)年龄在 15 岁以下,大约 9.2%(559 万人)的人口年龄在 60 岁以上。15 岁以下儿童比例最高的省份是林波波省(33.6%)和东开普省(32.7%)。南非 60 岁及以上的老年人口比例与日俱增,因此应优先制定政策和计划来满足这一不断增长的人口的需求。 语言 除官方语言外,南非还使用许多其他语言,包括非洲语、欧洲语、亚洲语等,因为该国位于南部非洲的十字路口。该国使用的其他语言并在宪法中提及,包括科伊语、纳马语和桑语、手语、阿拉伯语、德语、法语、希腊语、古吉拉特语、希伯来语、印地语、葡萄牙语、梵语、泰米尔语、泰卢固语和乌尔都语。此外还有少量土著克里奥尔语和皮钦语。

SRMIST的第二届年度Pongal节
值得注意的获奖者还包括教授露台。M. Bopathy,博士K. Magudamudi,教授K. Tamilamalan和教授西瓦。 Elango,他收到了G.U. 教皇翻译奖,泰米尔语Abdul Kalam科学技术奖,Parithimar Kalaignar奖和Muthamzh Arignar Kalaignar Karunadhi社会正义奖。 作者唐加·森卡西(Thanga Senkathir),教授Seyyon和Shvashankari还获得了Sudesamtra Tamil Ithazh奖,Tholkappiya Tamil Sangam奖和Parivendaddor Pyntamil奖,后者包括卢比的现金奖。 3号 SRMIST的亲校长(行政)博士的存在为此事件增添了优化。 Ravi Pachamuthu,副理事博士C. Muthamzhchelvan,注册商博士S. Plunsamy兼泰米尔人Perayam教授的总裁卡鲁·纳加拉扬(Karu Nagarajan)和其他贵宾。M. Bopathy,博士K. Magudamudi,教授K. Tamilamalan和教授西瓦。Elango,他收到了G.U.教皇翻译奖,泰米尔语Abdul Kalam科学技术奖,Parithimar Kalaignar奖和Muthamzh Arignar Kalaignar Karunadhi社会正义奖。作者唐加·森卡西(Thanga Senkathir),教授Seyyon和Shvashankari还获得了Sudesamtra Tamil Ithazh奖,Tholkappiya Tamil Sangam奖和Parivendaddor Pyntamil奖,后者包括卢比的现金奖。3号SRMIST的亲校长(行政)博士的存在为此事件增添了优化。 Ravi Pachamuthu,副理事博士C. Muthamzhchelvan,注册商博士S. Plunsamy兼泰米尔人Perayam教授的总裁卡鲁·纳加拉扬(Karu Nagarajan)和其他贵宾。
南非 2021/22
约 28.07% 的人口年龄在 15 岁以下(1701 万),约 9.2%(559 万)的人口年龄在 60 岁及以上。15 岁以下儿童比例最高的省份是林波波省(33.6%)和东开普省(32.7%)。南非 60 岁及以上老年人的比例随着时间的推移而增加,因此应优先考虑满足这一不断增长的人口需求的政策和计划。语言 除了官方语言外,南非还使用许多其他语言 - 非洲、欧洲、亚洲等,因为该国位于南部非洲的十字路口。该国使用的其他语言,以及宪法中提到的语言,包括科伊语、纳马语和桑语、手语、阿拉伯语、德语、法语、希腊语、古吉拉特语、希伯来语、印地语、葡萄牙语、梵语、泰米尔语、泰卢固语和乌尔都语。此外,还有少数本土克里奥尔语和洋泾浜语。


数据处理至关重要:SRPH-Konvergen AI 为 WMT'21 打造的机器翻译系统
本文介绍了三星菲律宾研究中心和 Konvergen AI 联合团队为 WMT'21 大规模多语言翻译任务提交的机器翻译系统。我们的团队参加了 Small Track #2,其任务是为五种东南亚语言(爪哇语、印尼语、马来语、他加禄语和泰米尔语 1 )以及英语制作一个多语言机器翻译系统,涵盖所有 30 个方向。我们将首先描述用于预处理数据的过滤启发式方法,然后概述我们训练和评估模型所采取的步骤。特定的超参数、预处理决策和其他训练参数将在其相应的部分列出。最后,我们报告在 FLORES-101(Goyal 等人,2021 年)隐藏测试集以及竞赛隐藏测试集上的结果。


语音识别中的人工智能应用
I. 引言当今时代是人机交互的时代,人在银行和金融机构、国防和军事、教育、医疗和交通领域、预订系统、查询系统等各个领域都发挥着至关重要的作用。由于英语的存在,欠发达地区和农村社区无法使用技术,从而导致计算机网络和通信意识的传播。对于非英语用户来说,最好的解决方案可能是用母语与人互动的智能设备。印度是一个语言多元化的国家,根据 2001 年的人口普查,印度有 1599 种语言、122 种主要语言和 22 种官方语言,其中包括印地语、英语、尼泊尔语、克什米尔语、古吉拉特语、旁遮普语、梵语、孟加拉语、奥里雅语、曼尼普尔语、马拉地语、卡纳达语、孔卡尼语、泰米尔语、泰卢固语和乌尔都语 [1,2,3] 根据第 8 附表。这些是印度的自然使用语言。本文重点研究语言代码选择,即在一次话语中从一种语言转换为另一种语言,也称为代码转换。
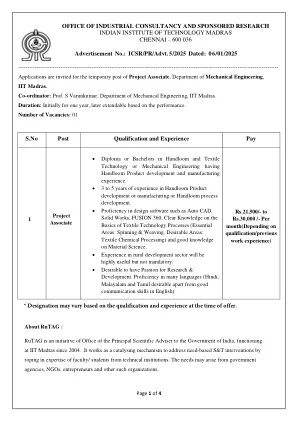
S.No 职位资格和经验薪酬办公室...
拥有手工织布和纺织技术或机械工程文凭或学士学位,并具有手工织布产品开发和制造经验。 拥有 3 至 5 年手工织布产品开发或制造或手工织布工艺开发经验。 熟练使用 Auto CAD、Solid Works、FUSION 360 等设计软件,熟悉纺织技术工艺的基础知识(关键领域:纺纱和织造,理想领域:纺织化学加工),并具备丰富的材料科学知识。 拥有农村发展领域的经验将非常有用,但不是强制性的。 最好对研究和开发充满热情。精通多种语言(除了良好的英语沟通能力外,最好会说印地语、马拉雅拉姆语和泰米尔语)。

语言实体掩蔽可改善低资源语言的多语言模型的跨语言表示
按照掩蔽语言建模 (MLM) 目标进行训练的多语言预训练语言模型 (multiPLM) 通常用于双语文本挖掘等跨语言任务。然而,这些模型的性能对于低资源语言 (LRL) 仍然不是最优的。为了改进给定 multiPLM 的语言表示,可以进一步对其进行预训练。这称为持续预训练。先前的研究表明,使用 MLM 进行持续预训练,随后使用翻译语言建模 (TLM) 进行预训练可以改进 multiPLM 的跨语言表示。然而,在掩蔽期间,MLM 和 TLM 都会给予输入序列中的所有标记相同的权重,而不管标记的语言属性如何。在本文中,我们引入了一种新颖的掩蔽策略,即语言实体掩蔽 (LEM),用于持续预训练步骤,以进一步改进现有 multiPLM 的跨语言表示。与 MLM 和 TLM 相比,LEM 将掩码限制在语言实体类型名词、动词和命名实体上,这些实体在句子中占据更重要的地位。其次,我们将掩码限制在语言实体范围内的单个标记上,从而保留更多上下文,而在 MLM 和 TLM 中,标记是随机掩码的。我们使用三个下游任务评估 LEM 的有效性,即双语挖掘、并行数据管理和代码混合情感分析,使用三种低资源语言对英语-僧伽罗语、英语-泰米尔语和僧伽罗语-泰米尔语。实验结果表明,在所有三个任务中,使用 LEM 持续预训练的多 PLM 优于使用 MLM+TLM 持续预训练的多 PLM。

中央公立学校联合会 德里地区办事处
1. 物理障碍 - 是环境和自然条件,在信息从发送者传递到接收者的过程中,会阻碍沟通。例如噪音 2. 人际障碍 - 发送者的信息与接收者所想的不同。与不愿意说话或表达感受和观点的人沟通会变得困难。例如舞台恐惧症。 3. 语言障碍 - 无法使用泰米尔语和印地语等语言进行交流。 4. 组织障碍 - 组织是根据遵循绩效标准、规则、条例、程序、政策、行为规范等的正式等级结构设计的。 5. 文化障碍 - 不同文化背景的人无法理解彼此的风俗习惯。 克服有效沟通障碍的方法