XiaoMi-AI文件搜索系统
World File Search System测试用例

异质材料双栅极的建模与仿真
隧道场效应晶体管 (TFET) 被认为是未来低功耗高速逻辑应用中最有前途的器件之一,它将取代传统的金属氧化物半导体场效应晶体管 (MOSFET)。这是因为随着 MOSFET 尺寸逐年减小,以实现更快的速度和更低的功耗,并且目前正朝着纳米领域迈进,这导致 MOSFET 的性能受到限制。在缩小 MOSFET 尺寸的同时,面临着漏电流增加、短沟道效应 (SCE) 和器件制造复杂性等几个瓶颈。因此,基于隧道现象原理工作的 TFET 已被提议作为替代 MOSFET 的器件之一,后者基于热电子发射原理工作,将器件的亚阈值摆幅限制在 60mV/十倍。 TFET 具有多种特性,例如不受大多数短沟道效应影响、更低的漏电流、低于 60mV/dec 的更低亚阈值摆幅、更低的阈值电压和更高的关断电流与导通电流之比。然而,TFET 也存在一些缺点,例如掺杂 TFET 的制造工艺复杂,会导致各种缺陷。这些问题可以通过使用无掺杂技术来克服。该技术有助于生产缺陷更少、更经济的设备。另一个缺点是 TFET 表现出较低的导通电流。异质材料 TFET 可用于解决低离子问题。为了更好地控制异质材料 TFET 沟道,提出了双栅极。亚阈值摆幅 (SS) 是决定器件性能的重要参数之一。通过降低 SS,器件性能将在更低的漏电流、更好的离子/关断比和更低的能量方面更好。这个项目有 3 个目标:建模和模拟异质材料双栅极无掺杂 TFET (HTDGDL- TFET)。比较 Ge、Si 和 GaAs 作为源区材料的 TFET 性能。将 HTDGDL-TFET 用作数字反相器。将使用 Silvaco TCAD 工具进行模拟。已成功建模单栅极和双栅极 HTDL-TFET。已为该项目进行了 4 个模拟测试用例,以选择所提 TFET 的最佳结构。使用 Vth、SS、Ion、Ioff 和 Ion/Ioff 比等几个重要参数来测量 TFET 的性能。在所有 4 个测试用例中,最佳 TFET 结构以 Ge 为源区材料,源区和漏区载流子浓度为 1 × 10 19 𝑐𝑚 −3,沟道载流子浓度为 1 × 10 17 𝑐𝑚 −3,且无掺杂。这是因为器件的 Vth 值为 0.97V,SS 值为 15mV/dec,Ion/Ioff 比为 7 × 10 11 。设计的 TFET 反相器的传播延迟比 [21] 中的反相器短 75 倍,比市场反相器 [SN74AUC1G14DBVR] 短 29 倍。本文还提出了一些未来的工作。

直接内存访问控制器的全芯片验证...
摘要 — 本文重点介绍使用 UVM 对微控制器片上系统 (SoC) 中的 DMA 控制器进行功能验证。DMA 是现代计算机系统不可或缺的一部分,它通过从 CPU 卸载数据传输任务来提高性能。拟议的工作采用通用验证方法 (UVM) 来开发一个全面的验证环境,其中包括驱动程序、监视器、记分板和序列器等基本组件。验证涵盖各种数据传输模式(固定到固定、固定到块、块到固定和块到块)、边界条件和错误情况,以确保 DMA 控制器的功能正确性。获得了不同的代码覆盖率,例如 FSM 覆盖率为 100%,表达式覆盖率为 90.13%,条件覆盖率为 93.33%,语句覆盖率为 99.34%,这使得 DMA 控制器的总体代码覆盖率为 86%。断言、覆盖点和覆盖组等高级 SystemVerilog 功能被纳入测试平台以提高其有效性。拟议的工作还通过详细的测试用例展示了成功的验证,验证了 DMA 控制器的功能并为 SoC 设计的未来增强提供了坚实的基础。

AI 规划中的自动行动策略测试
1 简介 使用神经网络 (NN) 学习行动策略 π 在游戏中非常成功 (Mnih 等人2013;Sil- ver 等人2018),并在 AI 规划中越来越受欢迎 (Is- sakkimuthu、Fern 和 Tadepalli 2018;Groshev 等人2018;Garg、Bajpai 和 Mausam 2019;Toyer 等人2020;Karia 和 Srivastava 2021)。策略 π 可以在动态环境中做出实时决策,只需根据当前状态对其进行评估即可获得下一步行动。然而,这种方法显然存在潜在的政策“缺陷”,即不良或致命的政策行为。测试(试图找到发生此类行为的情况)是解决这一问题的自然范例。自动测试用例生成可用于评估 π 的质量,并最终通过广泛的测试来证明 π 是可信的。先前关于顺序决策测试的研究控制环境行为(MDP 中的状态转换选择),并尝试找到满足故障条件 ϕ 的环境决策序列(例如,Dreossi 等人2015;Akazaki 等人2018;Koren 等人2018;Ernst 等人2019;Lee 等人2020)。但如果失败
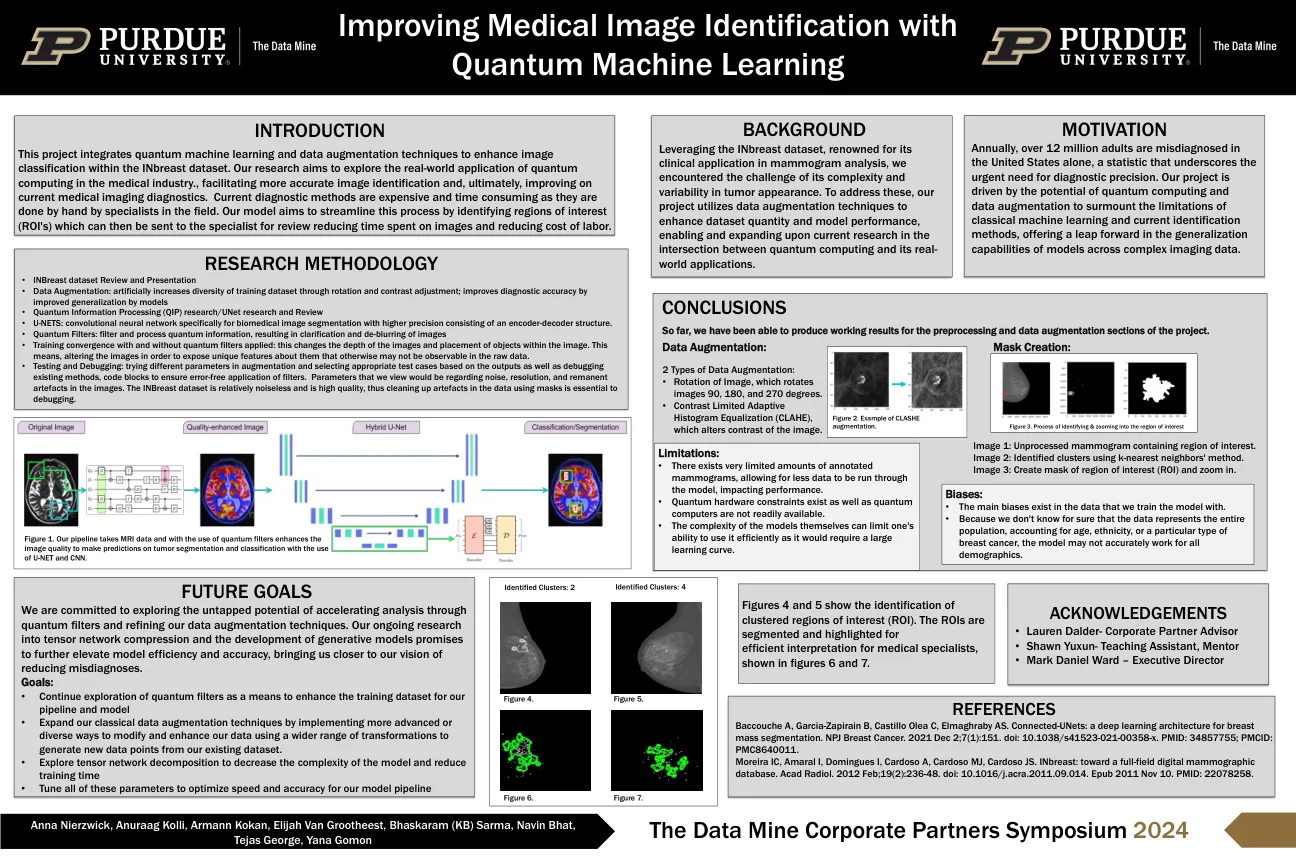
用量子改进医学图像识别...
研究方法•INBREAST数据集审查和呈现•数据增强:通过旋转和对比度调整,人为地增加培训数据集的多样性;通过模型改善概括来提高诊断精度•量子信息处理(QIP)研究/UNET研究和审查•U-NET:卷积神经网络专门针对生物医学图像分割,具有更高的精度,由编码器编码器结构组成。•量子过滤器:过滤和处理量子信息,导致图像的澄清和去除•使用和不使用量子过滤器的训练收敛性:这改变了图像深度和对象在图像中的位置。这意味着更改图像以揭示它们在原始数据中可能无法观察到的独特功能。•测试和调试:在增强中尝试不同的参数,并根据输出选择适当的测试用例,并调试现有方法,代码块,以确保过滤器的无错误应用。我们认为的参数将是关于图像中噪声,分辨率和剩余文物的参数。Inbreast数据集相对毫无噪音,并且是高质量的,因此使用掩码清理数据中的人工制品对于调试至关重要。

自动网络物理系统基于模拟测试的路线图:挑战和未来方向
作为自动网络物理系统(ACPS)的时代,例如无人驾驶汽车和自动驾驶汽车,展开,可靠测试方法的范围是实现在现实世界中采用此类系统的关键。但是,传统的软件测试范例在确保这些系统的安全性和可靠性方面面临着前所未有的挑战。在响应中,本文开创了用于基于ACPS的基于模拟测试的战略路线图,这特别是专注于自主系统。我们的论文讨论了ACPS的相关挑战和障碍,重点是测试自动化和质量保证,因此主张量身定制的解决方案来满足自动系统的独特需求。在模拟环境中提供了测试用例的具体定义时,我们还强调了创建新的基准资产和开发自动化工具在软件社区中明确量身定制的自动化工具的需求。本文不仅强调了相关的问题,并施加了软件工程社区应重点关注的问题(就实践,预期的自动化和范式而言),而且还概述了解决这些问题的方法。通过概述了基于ACPS的基于模拟的测试/开发的各个领域和挑战,我们为将来的研究效果提供了方向。

基于循环神经网络模型的 PMSG 变流器中功率半导体的可靠性评估
为了在可接受的仿真时间内获得准确的寿命评估结果,以满足全生命周期设计标准,本文提出了一种基于循环神经网络 (RNN) 的模型来替代 Simulink 模型。首先建立永磁同步发电机 (PMSG) 的平均开关 (AS) 模型和平均基波 (AF) 模型来计算累积损伤。然后,在相同的任务概况下,计算并比较 AS 和 AF 模型的结温、雨流计数和累积损伤。可以看出,AS 模型可以更准确地计算组件的可靠性,因为该模型既考虑了负载变化引起的大热循环,也考虑了基波交流电流引起的小热循环。然而,与 AF 模型相比,它耗费更多时间。为此,提出使用 RNN 模型来替代系统可靠性评估程序中最耗时的部分。借助所提出的模型,与 Simulink 模型相比,可以大大减少所耗时间。最后,通过一个1小时的案例验证了RNN模型的有效性。测试用例的平均绝对百分比误差(MAPE)为0.51%,RNN模型得出结果的时间小于1秒。此外,还实施了一个年度案例来验证RNN模型,全年平均MAPE为0.78%。

定价电池储能系统在能源、储备和按绩效付费调节市场中的最佳参与
摘要 — 出于评估不同市场中电池储能服务的最佳分配及其对市场运营的影响的需要,本文提出了一个优化框架,以协调独立公用事业规模定价电池储能系统 (BESS) 在能源、旋转备用和基于性能的监管市场中的运行。整个问题被表述为一个双层优化过程,其中所有市场的结构都考虑到联合运行限制进行建模。研究了按绩效付费监管市场中定价者 BESS 的战略竞价行为。此外,还介绍了一种在优化中建模自动发电控制 (AGC) 信号的特定方法。虽然公式化的问题是非线性的,但它被转换为混合整数线性规划 (MILP) 以找到最优解。使用从真实市场数据创建的测试用例场景对所提出的框架进行评估。案例研究结果显示了 BESS 的定价行为对能源、备用和监管市场联合运营的影响。索引术语 — 电池储能系统 (BESS)、竞价策略、定价者、基于绩效的监管市场、双层优化、混合整数线性规划

CDA-AMC 人工智能医疗设备卫生技术审查实施情况审查:主要报告
数字健康技术 (DHT),包括支持 AI 的医疗设备,正在迅速发展并引发了许多希望和炒作。1 人工智能 (AI) 使用算法或模型来执行任务并模仿人类行为,例如学习、决策和预测。2 当医疗设备结合 AI 算法和机器学习 (ML) 模型来增强其功能和性能时,它通常被描述为支持 AI 的医疗设备或 MLMD。2,3 支持 AI 的医疗设备的一个例子是软件平台 RapidAI,4 它与本次审查一起进行了评估(可在项目网站上找到)。RapidAI 通过使用 AI 来提供医学成像工具,以便于查看、处理和分析 CT 图像。4 RapidAI 的总体目标是帮助临床医生评估疑似患有疾病的患者并确定适当的治疗方法。4 虽然 DHT 有望改善各种结果(例如,更好地获得医疗保健),但评估和实施它们带来了新的独特挑战。 AI 可能带来其他类别的 DHT 所特有的所有挑战(例如数据考虑、互操作性问题)以及其他挑战(例如算法公平性和偏见、黑盒或持续学习性质),5-7 可作为解决 DHT 带来的许多新挑战和独特挑战的有用测试用例。

自动化人类辅导员风格的编程反馈:利用GPT-4的提示生成指导模型和提示验证的GPT-3.5学生模型
生成的AI和大型语言模型通过自动为学生产生个性化的反馈来增强编程教育。我们调查了生成AI模型在提供人类辅导员风格的编程提示中的作用,以帮助学生解决其越野车计划中的错误。重新制作的作品对各种反馈生成方案的最新模型进行了基准测试;但是,它们的整体质量仍然不如人类的辅导员,尚未准备好现实世界。在本文中,我们试图将生成AI模型的限制推向提供高质量的编程提示,并开发出一种新颖的技术GPT4HINTS-GPT3.5VAL。作为第一步,我们的技术利用GPT-4作为“辅导”模型来生成提示 - 它通过使用未完成的测试用例和提示中修复的符号信息来提高生成质量。作为下一步,我们的技术利用GPT-3.5(一个较弱的模型)作为“学生”模型来进一步验证提示质量 - 它通过模拟提供此反馈的潜在实用性来执行自动质量有效性。我们通过对Python程序的三个现实数据集进行了广泛的评估来显示我们的技术的功效,这些数据集涵盖了从基本算法到使用PANDAS库的正则表达式和数据分析的各种概念。

大型语言模型仍然无法计划(LLMS计划和推理有关变更的基准)
大型语言模型(LLM)的最新进展已改变了自然语言处理(NLP)的领域。从GPT-3到Palm,每个新的大型语言模型都在推动自然语言任务的最先进的表现。与自然语言能力一起,人们对理解这种模型的使用是否具有推理基准表现出推理能力。但是,即使结果似乎是积极的,这些基准也被证明是简单化的,而LLMS在这些基准测试中的性能不能用作支持的证据,很多时候很奇怪,对LLMS的推理能力提出了主张。此外,这些仅代表了非常有限的简单推理任务集,如果我们要衡量基于LLM的系统的真实限制,我们需要研究更复杂的推理问题。以此为动机,我们提出了一个可扩展的评估框架,以测试LLM在行动和变化推理的能力,这是人类智能的主要方面。我们提供的多个测试案例比任何先前建立的基准都更重要,并且每个测试用例都评估了有关动作和变化的推理的不同方面。在GPT-3(Davinci),指令-GPT3(Text-Davinci-002)和Bloom(176b)上的结果,在此类推理任务上显示了Subpar的表现。