XiaoMi-AI文件搜索系统
World File Search System真实

真实量子处理单元上的量子模式识别
摘要 量子计算最有前途的应用之一是处理图像等图形数据。在这里,我们研究了基于交换测试实现量子模式识别协议的可能性,并使用 IBMQ 噪声中型量子 (NISQ) 设备来验证这个想法。我们发现,使用双量子比特协议,交换测试可以有效地以良好的保真度检测两个模式之间的相似性,尽管对于三个或更多量子比特,真实设备中的噪声会变得有害。为了减轻这种噪声影响,我们采用破坏性交换测试,这显示出三量子比特状态的性能有所提高。由于云对较大 IBMQ 处理器的访问有限,我们采用分段方法将破坏性交换测试应用于高维图像。在这种情况下,我们定义了一个平均重叠度量,当在真实 IBMQ 处理器上运行时,它可以忠实地区分两个非常不同或非常相似的模式。作为测试图像,我们使用具有简单模式的二进制图像、灰度 MNIST 数字和时尚 MNIST 图像,以及从磁共振成像 (MRI) 获得的人体血管的二进制图像。我们还介绍了一种利用金刚石中的氮空位 (NV) 中心进行破坏性交换测试的实验装置。我们的实验数据显示单量子比特状态具有高保真度。最后,我们提出了一种受量子联想记忆启发的协议,其工作方式类似于监督学习,使用破坏性交换测试进行量子模式识别。

真实媒介:沉浸式技术和叙事空间
在本文中,我们将VR视为铭文悠久传统的新写作空间。构建虚拟现实(VR)叙述可以被理解为刻有空间中文本的过程,并将其作为“阅读”空间的过程。我们的研究目标是探索空间叙事提供的意义创造过程,以测试VR是否促进了传统的编织复杂,多个叙事链的方式,并为利用空间提供了新的机会。我们认为,与印刷书的线性空间相反,VR叙事空间与博物馆的物理空间相似,可以在三个不同的层面上进行分析:(1)空间本身的架构,(2)收藏品,(3)单个文物。为了为设计VR叙事提供更深层次的背景,我们设计并实施了一个名为RealityMedia的测试台,以探索传统叙事设备的数字补救措施以及VR的空间,沉浸式和互动效果。我们使用VR耳机和20名参与者的定性访谈进行了基于任务的用户研究。我们的结果突出了三个语义级别(空间,收集和工件)如何共同构成VR中有意义的叙事经历。

一线联合免疫检查点的真实数据......
摘要背景:黑色素瘤脑转移(MBM)预后不良。已证实可改善晚期黑色素瘤预后的全身治疗具有颅内(IC)效应。我们研究了联合免疫检查点抑制剂伊匹单抗/纳武单抗(Combi-ICI)或靶向治疗(Combi-TT)作为 MBM 一线治疗的疗效和预后。方法:MBM 患者在诊断后 3 个月内接受 Combi-ICI 或 Combi-TT 治疗。终点是无进展生存期(PFS)和总生存期(OS)。结果:53 例患者接受了 Combi-ICI 治疗,32% 有症状性 MBM,33.9% LDH 升高。71.7% 需要局部治疗。疾病控制率为 60.3%。 3 个月时 IC 缓解率 (RR) 为 43.8%,6 个月时 (46.5%) 和 12 个月时 (53.1%) 持久缓解。3 个月时颅外 (EC) RR 为 44.7%,12 个月时为 50%。中位 PFS 为 9.6 个月 (95% CI 3.6-NR),中位总生存期 (mOS) 为 44.8 个月 (95% CI; 26.2-NR)。63 名患者接受了 Combi-TT,55.6% 的患者有症状性 MBM,57.2% 的患者 LDH 升高,68.3% 的患者需要局部治疗。疾病控制率为 60.4%。3 个月时 ICRR 为 50%,但 6 个月时下降 (20.9%)。ECRR 为

评估来自真实世界证据的 HTA 影响......
IQWiG 表示,GSAV 的实施将对德国的常规数据收集产生更大的影响,而不是对孤儿药福利评估过程的影响。G-BA 对 RWE 效用的信心增加,可能会促使制造商在未来提供高质量、全面的数据。我们的分析和 IQWIG 的报告表明,G-BA 注册使用的要求将很少使用,可能仅在存在重大数据不确定性且 EMA 尚未发出 RWE / 注册创建请求的情况下使用。

ALK 重排 NSCLC 患者的真实临床实践
1 日本水户市筑波大学水户共同综合医院-水户医疗中心呼吸内科;2 日本水户市水户医疗中心呼吸内科和胸外科;3 日本日立市日立综合医院呼吸内科和胸外科;4 日本东海市茨城东医院呼吸内科;5 日本水户市筑波大学常陆那珂医疗中心呼吸内科;6 日本笠间市茨城县中央医院呼吸中心;7 日本土浦市土浦共同综合医院呼吸内科和胸外科;8 日本筑波大学临床医学院;9 日本筑波市筑波医疗中心医院呼吸内科和胸外科; 10 日本筑波筑波纪念医院胸外科;11 日本土浦霞浦医疗中心呼吸内科;12 日本阿见町东京医科大学茨城医疗中心呼吸内科和胸外科;13 日本龙崎龙崎赛生会医院呼吸内科;14 日本取手市 JA 取手市医疗中心呼吸内科;15 日本堺町西南医疗中心呼吸内科;16 日本筑波学园综合医院呼吸内科

真实三体纠缠的可靠几何测量
我们给出了离散、连续和混合量子系统的真正三体纠缠的忠实几何图像。我们首先发现三角关系 E α i | jk ⩽ E α j | ik + E α k | ij 对所有亚可加二体纠缠测度 E 、所有 i 、 j 、 k 方下的排列、所有 α ∈ [0 , 1] 以及所有纯三体态都成立。然后,我们严格证明边 E α 包围的非钝角三角形面积(0 < α ⩽ 1 / 2)是真正三体纠缠的测度。最后,对于量子位,给定一组亚加性和非亚加性测度,总会发现某个状态违反任何 α > 1 的三角关系,并且三角形面积不是任何 α > 1 / 2 的测度,这一点得到了显著加强。我们的研究结果为在统一框架内研究离散和连续多体纠缠铺平了道路。

真实神经元网络中的几何尺度律
我们研究了果蝇在不同发育阶段的突触分辨率连接组,揭示了神经元连接概率相对于空间距离的一致缩放定律。这种幂律行为与之前在粗粒度脑网络中观察到的指数距离规则有显著不同。我们证明几何缩放定律具有功能意义,与信息通信的最大熵和平衡整合与分离的功能临界性相一致。扰乱经验概率模型的参数或其类型会导致这些有利特性的丧失。此外,我们推导出一个明确的神经元连接定量预测因子,仅结合神经元间距离和神经元的进出度。我们的研究结果建立了大脑几何和拓扑结构之间的直接联系,有助于理解大脑如何在其有限空间内最佳地运作。

食物的真实成本:食物是医学案例研究
第一个案例研究是医疗量身定制的餐食:住院和医疗保健支出,是对全国MTM实施的真正成本的健康和经济评估。第二个案例研究,制作处方计划:健康和经济影响,是对扩大全国糖尿病和粮食不安全成人实施农产品处方的真实成本的健康和经济评估。总体结果表明,1)针对与饮食相关的状况和日常生活(IADL)限制的患者进行医疗保险,医疗补助和私人保险的全国实施,可能会导致约160万个避免住院和净成本储备的净成本和净成本储备,并在第一年中获得136亿美元的损害,以及在第一年的疾病中产生的疾病,以及在第一年中产生的罪名。 292,000种避免心血管事件和260,000个质量调整的终身岁月,同时从健康角度获得了高度有效的成本效益(基于成本效益的增量成本效益比为18,100美元/质量调整后的终身生活年),从社会角度来节省了成本(基于一个净储蓄净额(基于-0..055亿美元的网络储蓄))。

在有限温度下的真实频率图蒙特卡洛
图解扩展是处理相关电子系统的中心工具。在热平衡下,它们最自然地定义了Matsubara形式主义。但是,从Matsubara计算中提取任何动态响应函数最终需要从虚构到实频域到实频域的错误分析延续。最近提出了[物理学。修订版b 99,035120(2019)],可以使用符号代数算法分析进行任何相互作用膨胀图的内部Matsubara总结。总结的结果是复杂频率而不是Matsubara频率的分析函数。在这里,我们应用了此原理并开发了一种示意的蒙特卡洛技术,该技术直接在实际频率轴上产生。我们介绍了在非平凡参数方面的掺杂32x32环状方晶格哈伯德模型的自我能量σ(ω)的结果,其中pseudogap的特征似乎靠近antinode。我们讨论了在实频轴上的扰动序列的行为,尤其表明,在使用截短的扰动系列上使用最大熵方法时,必须非常小心。在分析延续很困难的情况下,我们的方法对将来的应用具有巨大的希望,而中阶扰动理论可能会融合结果。
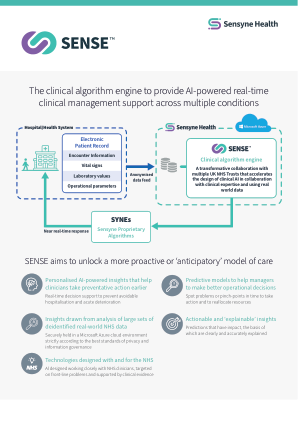
临床算法引擎提供人工智能驱动的真实……
与其他风险预测引擎不同,SENSE 使用先进的神经网络技术同时处理大量临床变量,为每位患者提供具有可量化确定性水平的个性化预测,并用通俗易懂的英语向临床医生解释。