XiaoMi-AI文件搜索系统
World File Search System程文

论文内容的摘要
[纸质评论摘要] 1。文章内容本文通过使用TOL2 transposon将导向RNA(GRNA)敲入基因组来建立了一种方便地创建条件敲除小鼠的方法。 2.纸质评论1)为研究目的而开创性和独创性,使用特定周期和组织特异性的条件敲除小鼠至关重要,以分析单个水平的基因功能。但是,传统的CRE/LOXP方法需要多种小鼠菌株的交配,这需要时间和精力。在此背景下,申请人结合了三个现有系统:转座系统,CRE/LOXP系统和CRISPR/CAS9系统,以建立一个系统,允许在短时间内更加方便地创建有条件的淘汰小鼠。这种观点值得认可。 2)社会意义从这项研究中获得的主要结果如下。 1。cag-creer小鼠和rosa-lsl-cas9敲入小鼠被体外受精,质粒和TOL2转座子mRNA,其在TOL2识别序列中夹在小鼠酪氨酸酶的GRNA之间的序列,将Tyr GRNA插入了Born Born Rece的6.3%-13.6%中。 2。当他对出生的小鼠施用他莫昔芬时,在某些情况下观察到头发颜色的变化有限。 3。在三只小鼠(TG1、2、3)中观察到缺失和插入3.1%,6.8%和7.5%的酪氨酸酶基因。 4。当F0雄性小鼠交配时,11.1%的F1小鼠显示GRNA盒传播。如上所述,申请人已经建立了一个系统,该系统允许在短时间内更方便,更简单地创建有条件的敲除小鼠。可以说这是一项有用的研究发现,可以加速个人水平的基因的功能分析。 3)在这项研究中,使用T7分析和深层测序分析了GRNA的基因组裂解,并使用PCR或Southern印迹分析了下一代小鼠中GRNA盒的传播。这种方法是在足够的分子生物学实验技术的支持下进行的,这表明申请人的知识和技术技能在研究方法上足够高,同时可以看出,这项研究是在非常谨慎的准备中进行的。


HO Wen Wei (何文维) Emergence of Quantum State ...
何文伟博士现为斯坦福大学理论物理研究所博士后学者,研究非平衡量子多体现象和新兴量子技术的应用。此前,他是哈佛大学的摩尔博士后研究员,与 Mikhail Lukin 教授和 Eugene Demler 教授一起工作。从 2022 年 8 月开始,他将担任新加坡国立大学校长青年(助理)教授。何文伟于 2017 年在日内瓦大学师从 Dmitry Abanin 教授获得博士学位,2015 年在滑铁卢大学/圆周研究所师从 Guifre Vidal 教授获得理学硕士学位,2013 年在普林斯顿大学获得学士学位,与 Duncan Haldane 教授一起工作。摘要:普遍性是指复杂系统普遍属性的出现,这些属性不依赖于精确的微观细节。量子热化是强相互作用量子多体系统非平衡动力学的一个例子,其中局部区域随着时间的推移变得由吉布斯集合很好地描述,而该集合仅受少数几个系统参数(例如温度和化学势)控制。局部区域与其补体(“浴”)之间产生的大量纠缠是这种普遍性出现的关键。在这次演讲中,我将介绍一种新的普遍行为,它源于某些类型的量子混沌多体动力学,超越了传统的热化。我将描述单个多体波函数如何编码由小子系统支持的纯态集合,每个纯态都与局部浴的(投影)测量结果相关。然后,我将展示这些量子态的分布如何接近均匀随机量子态的分布,即集合形成量子信息理论中所谓的“量子态设计”。我们的工作为研究量子混沌提供了一个新视角,并在量子多体物理、量子信息和随机矩阵理论之间建立了桥梁。此外,它还提供了一种实用且硬件高效的伪随机态生成方法,为设计量子态层析成像应用和近期量子设备的基准测试开辟了新途径。

程良教授
学术出版物(精选) 1. Pei, ZF; Lei, HL; Cheng, L.* ,用于癌症治疗诊断的生物活性无机纳米材料。化学学会评论 2023, 52 (6), 2031-2081。 2. Lei, HL; Li, QG; Li, GQ; Wang, TY; Lv, XJ; Pei, ZF; Gao, X.; Yang, NL; Gong, F.; Yang, YQ; Hou, GH; Chen, MJ; Ji, JS*; Liu, Z.*; Cheng, L.* ,具有 STING 活化双重扩增的锰钼酸盐纳米点用于金属免疫治疗的“循环”治疗。生物活性材料 2024, 31, 53-62。 3. Wang, YJ; Gong, F.*;Han, ZH; Lei, HL; Zhou, YK; Cheng, SN; Yang, XY; Wang, TY; Wang, L.; Yang, NL; Liu, Z.; Cheng, L.*,缺氧氧化钼纳米增敏剂用于超声增强癌症金属免疫治疗。Angewandte Chemie-International Edition 2023, 62, e202215467 4. Wang, L.; Zhang, BR; Yang, XT; Guo, ST; Waterhouse, GIN; Song, GR; Guan, SY*; Liu, A. H*.; Cheng, L.*;Zhou, SY,通过阿托伐他汀-铁蛋白Gd层状双氢氧化物有针对性地缓解缺血性中风再灌注。生物活性材料 2023, 20, 126-136。 5. Wang, L.;Mao, Z.;Wu, J.;Cui, XL;Wang, YJ;Yang, NL;Ge, J.; Lei, HL; Han, ZH; Tang, W.; Guan, SY; Cheng, L.*,设计层状双氢氧化物基声催化剂以增强声动力免疫治疗。纳米今日 2023, 49。6. Cheng, SN; Chen, L.; Gong, F.; Yang, XY; Han, ZH; Wang, YJ; Ge, J.; Gao, X.; Li, YT; Zhong, XY; Wang, L.; Lei, HL; Zhou, XZ; Zhang, ZL*; Cheng, L.*,具有炎症微环境调节功能的 PtCu 纳米声敏剂可增强声动力细菌消除和组织修复。先进功能材料 2023, 33, 2212489 7. Wang, ZK; Zhang, P.; Yin, CY; Li, YQ; Liao, ZY; Yang, CH; Liu, H.; Wang, WY; Fan, CD*; Sun, DD*; Cheng, L.*,抗生素衍生的碳纳米点修饰水凝胶通过生物膜损伤增强活性氧的抗感染作用。先进功能材料 2023, 33, 2300341

【电子电路实验】课程纲要
一、丰富的数学、物理、科学与工程知识,以及实际运用的能力。 二、设计实验、执行实验、分析数据及归纳结果的能力。 三、执行电机工程实务所需理论、方法、技术及使用相关软硬体工具之能力。 四、电机工程系统、模组、元件或制程之设计能力。 五、团队合作所需之组织、沟通及协调的能力。 六、发掘问题、分析问题及处理问题的能力。 七、掌握科技趋势,并了解科技对人类、环境、社会及全球的影响。 八、理解专业伦理及社会责任。 九、专业的外语能力及与国际社群互动的能力。
![能源和信息课程学习课程[硕士课程]人力资源培训...](/simg/5\5063233e330f62749d5f8d0bd8941baf324b71df.webp)

物理年会议程总表Detailed Meeting Agenda
09:30 ~ 09:45 Germar Hoffmann Sunao Shimizu Yu-Wei Chen Ravish Kumar Jain YingLin Li Yu Hung Lin JaYil Lee Yan-Ru Chen Chan-Ching Lien Saikat Karmakar Po-Feng Wu Amar Aryan Chen-Kang Huang Hsin-Yeh Wu Chin-Chia Wu Anli Tsai
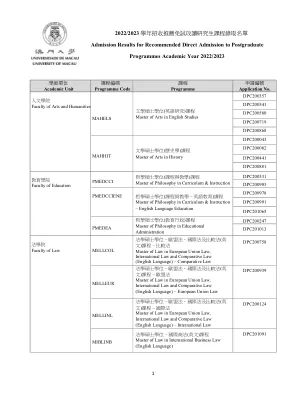
2022/2023 学年招收推荐免试攻读研究生课程录取名单- UM GRS
法学硕士学位– 欧盟法、国际法及比较法( 英文) 课程– 欧盟法Master of Law in European Union Law, International Law and Comparative Law (English Language) – European Union Law

文章/书籍信息 - T2R2
我们提出了一种方案,通过量子计算机上的统计抽样来构建相互作用电子系统的单粒子格林函数 (GF)。尽管电子自旋轨道的产生和湮灭算符的非幺正性使我们无法有选择地准备特定状态,但已证明量子比特可以进行概率状态准备。我们提供配备最多两个辅助量子比特的量子电路,以获得 GF 的所有组件。我们基于幺正耦合簇 (UCC) 方法对 LiH 和 H 2 O 分子的 GF 构建进行了模拟,通过比较 UCC 方法中的准粒子和卫星光谱以及全配置相互作用计算的光谱来证明我们方案的有效性。我们还通过利用 Galitskii-Migdal 公式来检查采样方法的准确性,该公式仅从 GF 中给出总能量。