XiaoMi-AI文件搜索系统
World File Search System累加

5469/23 kr/am 1 tree.1.a永久...数据
5委员会向欧洲议会,理事会,欧洲经济和社会委员会以及2019年4月9日的地区委员会关于欧洲议会指令2006/66/EC内部市场的实施以及对环境的影响以及2006年9月6日对欧洲议会的内部市场的运作,对炮台和累积者和蓄电池/蓄电池/累加者和累加仪和累加仪和累加者的行为(最终)和委员会的工作人员工作文件,内容涉及评估2006/66/EC对电池和蓄能器以及废物电池以及蓄能器以及废除指令91/157/EEC的评估(SWD(2019)1300最终)。 6附件2从委员会到欧洲议会,理事会,欧洲经济和社会委员会以及2018年5月17日的地区委员会的交流,欧洲正在移动 - 欧洲的可持续发展:安全,联系和清洁(com(2018)293最终)。5委员会向欧洲议会,理事会,欧洲经济和社会委员会以及2019年4月9日的地区委员会关于欧洲议会指令2006/66/EC内部市场的实施以及对环境的影响以及2006年9月6日对欧洲议会的内部市场的运作,对炮台和累积者和蓄电池/蓄电池/累加者和累加仪和累加仪和累加者的行为(最终)和委员会的工作人员工作文件,内容涉及评估2006/66/EC对电池和蓄能器以及废物电池以及蓄能器以及废除指令91/157/EEC的评估(SWD(2019)1300最终)。6附件2从委员会到欧洲议会,理事会,欧洲经济和社会委员会以及2018年5月17日的地区委员会的交流,欧洲正在移动 - 欧洲的可持续发展:安全,联系和清洁(com(2018)293最终)。

AN10902 使用 LPC32xx VFP - NXP 半导体
ARM 提供基于硬件的矢量浮点 (VFP) 协处理器,可加速浮点运算。ARM VFP 支持以 CPU 时钟速度执行单精度和双精度加法、减法、乘法、除法、乘法累加运算和除法/平方根运算。ARM VFP 可用于提高成像应用程序(如缩放、2D 和 3D 变换、字体生成、数字滤波器或任何使用浮点运算的应用程序)的性能。由于 ARM VFP 是由 ARM 开发和支持的协处理器,因此它在各种工具链、RTOS 和操作系统(如 Keil MDK 开发环境或 Linux)中都受到支持。ARM VFP 符合 IEEE 754 标准。

AI 引擎内核编码最佳实践指南
虽然大多数标准 C 代码都可以为 AI 引擎编译,但代码可能需要重构才能充分利用硬件提供的并行性。AI 引擎的强大之处在于它能够使用两个向量执行乘法累加 (MAC) 运算、为下一个运算加载两个向量、存储上一个运算的向量以及在每个时钟周期增加指针或执行另一个标量运算。称为内在函数的专用函数允许您定位 AI 引擎向量和标量处理器并提供几个常见向量和标量函数的实现,因此您可以专注于目标算法。除了向量单元之外,AI 引擎还包括一个标量单元,可用于非线性函数和数据类型转换。

修订:2024年1月:03433/2022第1页,共8
在人类中,ACE抑制剂和非甾体类抗炎药(NSAIDS)的组合可导致抗高血压功效或肾功能受损降低。兽药产品和其他抗高血压药的组合(例如钙通道阻滞剂,β受体阻滞剂或利尿剂),麻醉药或镇静剂可能会导致累加性降压作用。因此,应谨慎考虑同时使用NSAID或其他具有降压作用的药物。肾功能和低血压的迹象(嗜睡,弱点等)应密切监视并根据需要进行处理。与保存利尿剂(如螺内酯,triamterene或amiloride)的相互作用不能排除。由于高钙血症的风险,建议使用兽医药物与钾的利尿剂结合使用兽药水平。

政策 1 – 发电控制和性能 - NERC
4. 扰动控制绩效调整。在给定日历季度内未达到扰动控制标准的每个控制区域或储备共享组应在区域和/或 NERC 资源小组委员会评估后增加其日历季度的应急储备义务(偏移一个月)。[例如,对于一年的第一个日历季度,处罚适用于 5 月、6 月和 7 月。] 增加的金额应与上一季度的扰动控制标准不合规情况成正比。此调整不会在各个季度之间累加,并且是除最严重的单一应急之外所需的额外储备百分比。储备共享组可以选择一种分配方法来增加其储备共享组的应急储备,前提是此增加的金额已完全分配。 [请参阅“ 性能标准参考文件 ” C 节。]
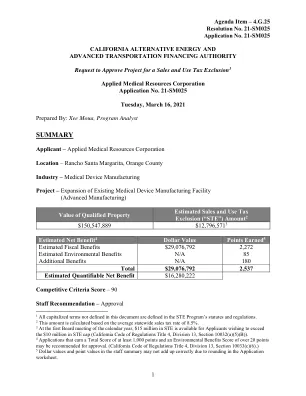
应用医疗资源公司员工摘要
2,272 85 180总计$ 29,076,792 2,537估计可量化的净福利$ 16,280,222竞争标准得分 - 90名员工建议 - 批准1在本文档中未定义的所有资本化条款在Stepon计划的法规和法规中定义。2此金额是根据全州平均营业税率8.5%来计算的。3在日历年的第一次董事会会议上,希望超过1000万美元的Ste Cap(加利福尼亚州法规第4章,第13分部,第13卷第10032(a)(5)(b)条)的申请人可获得1500万美元的Ste。4个申请至少获得1,000分,而环境福利得分超过20分的申请可以批准。(加利福尼亚州法规第4条,第13师,第10033(c)(6)节。)员工摘要中的5美元值和点值可能不会正确地累加,因为在应用程序工作表中进行四舍五入。

采用并行前缀加法器的高速乘法器设计
1. 引言 VLSI 技术在速度和尺寸方面的进步使得实现并行乘法器硬件成为可能。技术发展进一步确保了更好的性能特征和在 DSP 系统中的广泛使用。它执行诸如累加多个乘积之和之类的操作的速度比普通微处理器快得多。DSP 架构旨在执行并行操作,从而降低计算复杂性并提高此类应用中重复信号处理所需的速度[1]。这些功能旨在提高可编程 DSP 的速度和吞吐量。对于给定的应用,有大量可编程 DSP 可供选择,具体取决于速度、吞吐量、算术能力、精度、规模、成本和功耗等因素[2]。单芯片乘法器的引入及其与微处理器架构的结合是能够实现 DSP 功能的商用 VLSI 芯片面市的最重要原因[3]。并行前缀加法器被认为是最有效的二进制加法电路。它们的规则结构和快速性能使得它们特别适合实现 VLSI[4]。数字的乘积生成需要一个处理器周期。无论是基于软件的移位和加法算法,还是一个

AI 引擎上的波束成形实现
Xilinx AI 引擎专为各种应用(包括但不限于 5G 无线)中的密集计算而设计。一个 AI 引擎块由一个 AI 引擎、32KB 数据内存和两个用于自动数据传输的 DMA 引擎组成。每个 AI 引擎都配备了一个矢量处理器,该处理器能够在一个时钟周期内执行 32 个实数乘以实数 16 位乘法累加 (MAC) 运算。AI 引擎内的内存访问单元每个时钟周期读取 512 位操作数并写入 256 位计算结果,以匹配矢量处理器的功能。在单个 Versal™ AI Core 设备中,有数百个 AI 引擎块根据用户在编译时定义的数据流通过级联总线、AXI 流和共享本地内存互连。有关 AI 引擎的更多详细信息,请参阅 Xilinx AI 引擎及其应用 (WP506)。

使用在线光子独立成分分析...
摘要:独立成分分析 (ICA) 是一种通用技术,用于分析多维数据以揭示彼此最大程度独立的底层隐藏因素。我们报告了第一个通过采用片上微环 (MRR) 权重库对未知信号混合进行的光子 ICA。MRR 权重库对接收到的混合信号执行所谓的加权加法(即乘法累加)运算,并输出感兴趣信号的单个降维表示。我们提出了一种新颖的 ICA 算法,仅基于加权加法输出的统计信息来恢复独立成分,同时不仅对原始源而且对混合信号的波形信息都保持盲目性。我们研究了通道可分离性和近远问题,我们的双通道光子 ICA 实验表明我们的方案与传统的基于软件的 ICA 方法具有相当的性能。我们的数值模拟验证了所提出方法的保真度,并研究了噪声效应以确定我们方法的运行方式。所提出的技术可以为盲源分离、微波光子学和片上信息处理的未来研究开辟新的领域。

数据高效且计算高效的机器学习
海报会议 1:数据高效和计算高效的机器学习 标题:矩阵的内存效率 PoC:Chien-Cu Chen 标题:舒张阵列:高效的神经网络推理加速 PoC:Michael Mishkin 和 Mikko Lipasti 摘要:绝大多数神经网络运算都是与点积计算相关的乘法和累加。基于舒张阵列的神经网络加速有助于实现基于收缩阵列的节能神经网络推理加速,该收缩阵列具有复杂单元的浅流水线,每个单元包含多个乘法器单元和一个加法器树以执行部分缩减。这些流水线比传统的矩阵乘法收缩阵列实现包含的触发器更少,从而大幅节省能源。由于通过较浅流水线的较低延迟传播,可以进一步提高性能,但这种延迟的减少很容易被带宽限制所掩盖。通过并行操作多个较小的舒张阵列图块以提高阵列利用率,可以进一步提高性能。平铺增加的功耗被舒张阵列功率节省所抵消,从而在组合时产生最佳能量延迟积。标题:学生声学基础词嵌入,用于改进声学到词的语音识别 PoC:Shane Settle 标题:学生序列的多视图表示学习 PoC:Qingming Tang T