XiaoMi-AI文件搜索系统
World File Search System细分

细分申请表的计划
技术要求•计划是标准A1尺寸(594 mm x 841 mm)或拱形D大小(609.6 mm x 914.4 mm)板,以度量为单位,并使用适当的度量标准(1:200,1:200,1:250,1:300,1:300,1:300,1:1:400,1:400或1:500)。•为支持本申请的许多计划和研究必须由合格的工程师,建筑师,测量师,规划师或指定专家签名,密封和日期。如果缺少此信息,该市将不会审查计划或研究。•所有必需的研究的电子副本和细分计划草案必须以Adobe .pdf格式提供,并随附您的申请提交。所有PDF提交的文档均应解锁,扁平化并不保存为投资组合文件。•电子文档名称应与此表格第3节中包含的研究/计划名称相匹配。这些文档将在该市的开发应用搜索工具上公开可用。•分区计划草案必须参考水平控制网络并由财产所有人签署。•分区计划草案,以及任何后续的修订,必须以衡量标准单元(计算机辅助设计)格式提供,并以识别和标记为标记。如果可能的话,该计划还必须以网格格式进行地理化和提供。在MTM 9区,NAD83中协调。线条必须清楚地表明细分的周边,每个批次,块或部分都带有明确的文本标签。财务要求•描述该提案的大标志将发布在主题财产上。此服务的费用作为申请成本的一部分($ 1,023.78)。附加标牌,如果需要,将向申请人开具发票,每个标志$ 510.76。•在整个开发审查过程中可能需要额外的费用,包括但不限于Parkland奉献,技术报告的同行审查,保护局费用,协议以及相关费用以及适用的证券。

总体规划细分申请
所有拟建街区(即一个或多个被公共街道包围的地块)、地块和地块均应符合以下具体要求:1. 所有地块均应符合适用土地使用区域的一般开发标准(第 2 条)和第 3.1.020.J 节“街道连通性和街区形成”的标准。2. 退缩距离应符合适用土地使用区域的要求(第 2 条)。3. 每个地块均应符合第 3.1 章“出入和流通”的标准。4. 可能需要景观或其他遮蔽以维护毗邻用途的隐私。请参阅第 2 条 - 土地使用区域和第 3.2 章 - 景观美化。5. 根据《统一消防规范》,应提供 20 英尺宽的消防设备通道,以服务距离公共通行权或经批准的通道 150 英尺以上的建筑物所有部分。请参阅第 3.1 章 - 出入和流通。 6. 如果需要提供一条公用车道来服务多个地块,则应在经批准的分区或分区图中记录相互的通行和维护权地役权。 7. 应满足所有适用的街道、公用设施、地表水管理和地役权的工程设计标准。

人工智能驱动的应用程序细分
Zscaler, Inc. (HQ) 20 Holger Way San Jose, CA 95134 +1 408.533.0288 zscaler.com © 2024 Zscaler, Inc. 保留所有权利。Zscaler™、Zero Trust Exchange™、Zscaler Internet Access™、ZIA™、Zscaler Private Access™、ZPA™ 和 zscaler.com/legal/trademarks 上列出的其他商标是 (i) 注册商标或服务标志或 (ii) Zscaler, Inc. 在美国和/或其他国家/地区的商标或服务标志。任何其他商标均为其各自所有者的财产。
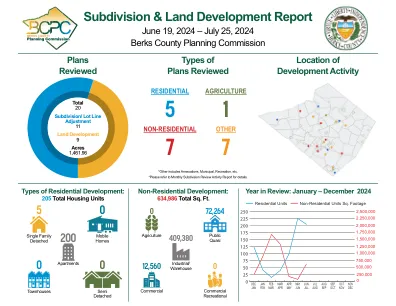

自由县细分和发展...
这些细分和发展法规已由自由县专员法院的命令通过,以提供自由县地区的有序有效发展。自由县的各个部门,机构,实体,雇员和代理人被指示执行这些法规,并被授权如本文所述。这些法规的目的是执行根据得克萨斯州水法,德克萨斯州健康与安全法规,德克萨斯州地方政府法规和其他法律授权的县的权力和职责,以制定专员法院的政策,并规定在与自由县开发相关活动的县诉讼中遵循的程序。10.1.02。可严重的性能是德克萨斯州自由县专员法院的明确意图,即这些法规的部分,附录,条款,段落,段落,短语,句子,句子和章节都可以切断。In the event any section, appendix, clause, paragraph, phrase, sentence, or subsection of these regulations shall be declared unconstitutional or invalid by the valid judgment or decree of any court of competent jurisdiction, such unconstitutionality or invalidity shall not affect any remaining sections, appendices, clauses, paragraphs, phrases, or subsections of these Regulations.


提高语义细分的效率...
提取和分析详细的视觉信息。传统的人工神经网络(ANN)在这一领域取得了长足的进步,但是尖峰神经网络(SNN)的能源效率和以生物为基础的基于时间的处理而引起了人们的关注。然而,由于限制,诸如量化误差和次优膜电位分布之类的局限性,现有的基于SNN的语义分割方法面临着高精度的挑战。这项研究介绍了一种基于尖峰 - 深板的新型尖峰方法,并结合了正则膜电位损失(RMP-loss)来应对这些挑战。建立在DeepLabv3体系结构的基础上,提出的模型通过优化SNN中的膜电位分布来利用RMP-loss来提高分割精度。通过优化膜电位的存储,其中仅在最后一个时间步骤存储值,该模型可显着减少内存使用和处理时间。这种增强不仅提高了计算效率,而且还提高了语义分割的准确性,从而可以对网络行为进行更准确的时间分析。提出的模型还显示出更好的稳健性,以防止噪声,在不同级别的高斯噪声下保持其精度,这在实际情况下很常见。所提出的方法在标准数据集上展示了竞争性能,展示了其用于节能图像处理应用的潜力


细分和发展上诉委员会
马太福音25:31ޓ40“但是,当人的儿子进入他的GL01Y,而所有的天使都和他在一起时,他将坐在他光荣的宝座上。所有的国家都将在他面前聚集,他将把人民分开,因为牧羊人将绵羊与山羊分开。他将把绵羊放在右手,山羊在他的左边。“然后国王会对他的右边的人说,'来吧,我父亲祝福的人继承了为您准备的王国。因为我被吊死:RY,你喂了我。我渴了,你给了我一杯饮料。我是一个陌生人,你邀请我进入你的家。我是赤裸裸的,你给了我衣服。我生病了,你照顾我。我在监狱里,你拜访了我。“那么这些正义的人会回答,'主,我们什么时候见过你。或口渴,给您一些喝点?还是一个陌生人,向您展示热情好客?还是裸露给你衣服?我们什么时候见过您生病或在监狱里拜访您?“国王会说,'我告诉你真相,当你对我的兄弟姐妹中的其中一个做到这一点时,你就是对我做的!'