XiaoMi-AI文件搜索系统
World File Search System自定义

2024 IEEE自定义集成电路会议(CICC)21
3:50 pm 11-6:70-通道频率频率的每通道冷冻-CMOS IC的7.4μW和860μm²,半导体Qubits的μs读取“ Quentin Schmidt先生(法国)1,Brian Martinez(France)1,Thomas Houriez(France)(France)1,France)1,Brian Martinez先生(France)。 (法国)1,Aloysius Jansen博士(法国)2,Xavier Jehl博士(法国)2,Tristan Meunier博士(法国)3,GaëlPillonnet博士(法国)1,GérardBilliot(法国)1,法国先生(法国)1,Adrien Morel(法国)4,France(France)(France)(France)5,France)5,5,France)5,5,5,France),5,5大学。Grenoble Alpes,CEA,Leti,F-38000 Grenoble,法国,2。大学。Grenoble Alpes,CEA,Pheliqs,F-38000 Grenoble,法国,3。Quobly,F-38000 Grenoble,法国;大学。Grenoble Alpes,CNRS,Institut Neel,F-38000 Grenoble,法国,4。Symme,Univ。Savoie Mont Blanc,法国Annecy,5。大学。Grenoble Alpes,CEA,List,F-38000 Grenoble,法国)

在自定义RISC-V ASIPS上嵌入机器学习的挑战
Solution: End-to-End TinyML Deployment and Benchmarking Flow • [MLIF] (Machine Learning Interface) • Framework/target-independent abstraction layers for Target SW • [MLonMCU] • Provides support for • 15+ targets (mainly RISC-V simulators) • 6 backends ([TVM] and TFLM) • Handling of Dependencies • Analysis and Exploration methods • Designed with并行性/可重复性

2025 IEEE自定义集成电路会议(CICC)13
1:30 pm 10-1 :(被邀请)类似基于变压器的语言模型(被邀请)类似类似的硬件加速器»Geoffrey W. Burr(美国)1,Hsinyu Tsai(美国)1,IEM Boybat(瑞士)博士(瑞士)2,William A. Simon(Switzerland) Vasilopoulos(瑞士)2,Pritish Narayanan博士(美国)1,Andrea Fasoli博士(美国)1,Kohji Hosokawa先生(日本)3(日本)3,Manuel Lealoo(瑞士)博士(瑞士)2国家)1,查尔斯·麦金(Charles Mackin)(美国)1,埃琳娜·费罗(Elena Ferro)(瑞士)2,Kaoutar El Maghraoui博士(美国)4,Hadjer Benmeziane博士(瑞士)2,Timothy Philicelli(美国)5,美国的Timothy Philicelli博士(瑞士) ,Shubham Jain博士(美国)4,Abu Sebastian博士(瑞士)2,Vijay Narayanan博士(美国)4(1。IBM研究-Almaden,2。IBM Research Europe,3。IBM东京研究实验室,4。 IBM T. J. Watson Research Center,5。 IBM Albany Nanotech)IBM东京研究实验室,4。IBM T. J. Watson Research Center,5。 IBM Albany Nanotech)IBM T. J. Watson Research Center,5。IBM Albany Nanotech)IBM Albany Nanotech)

2025 IEEE自定义集成电路会议(CICC)13
1:30 pm 10-1 :(被邀请)类似基于变压器的语言模型(被邀请)类似类似的硬件加速器»Geoffrey W. Burr(美国)1,Hsinyu Tsai(美国)1,IEM Boybat(瑞士)博士(瑞士)2,William A. Simon(Switzerland) Vasilopoulos(瑞士)2,Pritish Narayanan博士(美国)1,Andrea Fasoli博士(美国)1,Kohji Hosokawa先生(日本)3(日本)3,Manuel Lealoo(瑞士)博士(瑞士)2国家)1,查尔斯·麦金(Charles Mackin)(美国)1,埃琳娜·费罗(Elena Ferro)(瑞士)2,Kaoutar El Maghraoui博士(美国)4,Hadjer Benmeziane博士(瑞士)2,Timothy Philicelli(美国)5,美国的Timothy Philicelli博士(瑞士) ,Shubham Jain博士(美国)4,Abu Sebastian博士(瑞士)2,Vijay Narayanan博士(美国)4(1。IBM研究-Almaden,2。IBM Research Europe,3。IBM东京研究实验室,4。 IBM T. J. Watson Research Center,5。 IBM Albany Nanotech)IBM东京研究实验室,4。IBM T. J. Watson Research Center,5。 IBM Albany Nanotech)IBM T. J. Watson Research Center,5。IBM Albany Nanotech)IBM Albany Nanotech)

自定义赠款查找器报告 - 网络示例
与地质存储配对时,直接空气捕获(DAC)可以以一种可以帮助实现全球气候目标的规模永久删除碳二氧化碳IDE(CO2)。有大量证据可以深入评估地质二氧化碳存储的安全性和持久性,因为该实践已在美国的商业规模上数十年来利用。根据美国环境心理保护局(EPA)的VI级地下注射控制计划等框架进行适当的位置,构造,测试和监控时,CO2的地质存储既持久又安全[1]。地质存储周围的安全问题通常会因与管道运输二氧化碳的运输有关。鉴于DAC等技术发展的迅速增长,需要在全球范围内允许并委托更多地质存储以实现清除碳的目标。鉴于DAC等技术发展的迅速增长,需要在全球范围内允许并委托更多地质存储以实现清除碳的目标。
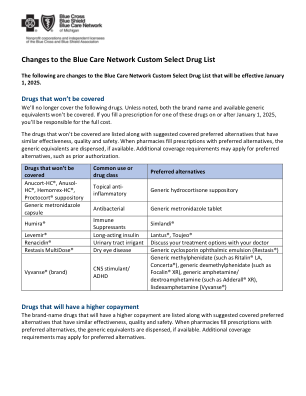
Blue Care Network 自定义选择药物清单的变更
一些药物和药物类别不在本药物清单的承保范围内,因此未显示。这些包括:• 有仿制药的品牌药物• 有非处方药同等强度和剂型的处方药(除非美国预防服务工作组认为是预防性的)• 非处方药(除非美国预防服务工作组认为是预防性的)• 生活方式药物(例如治疗勃起功能障碍或减肥的药物)• 产前维生素• 用于治疗胃灼热和胃酸反流的药物(部分仿制药除外)• 治疗咳嗽和感冒的药物,包括大多数抗组胺药• 用于实验目的的药物• 用于美容目的的处方药• 作为医疗福利承保的产品(例如,通常在医生办公室注射的注射药物和疫苗)

idt ruo自定义DNA和RNA寡做 - Net
IDT自定义寡核能是在礼节综合平台上制造的,并使用优化的磷光体化学用于可持续制造。IDT提供了广泛的修改和净化选项以及大量的配方服务菜单,以满足您苛刻的项目需求。Ultramer™DNA或RNA寡核能是较长的高质量寡核,最适合苛刻的应用,例如克隆,DDRNAI,同源指导的修复和基因构建。

开放式:培训具有大规模合成角色的可自定义角色扮演的LLM
在大型语言模型(LLMS)中(也称为charcter概括)中可自定义的角色扮演,人们对其在开发和部署角色扮演的对话代理方面的多功能性和成本效率引起了人们的关注。本研究探讨了一种大规模数据合成方法,以配备LLM具有特征生成能力。我们首先使用角色中心的角色综合大规模角色概况,然后探索两种策略:响应重写和响应生成,以创建与角色一致的教学响应。为了验证我们的合成教学调谐数据的有效性以进行角色泛化,我们使用Llama-3 8B模型执行监督的微调(SFT)。我们表现最好的模型增强了原始的Llama-3 8b指导模型,并实现了与角色扮演对话的GPT-4O模型相当的性能。我们发布了1个合成字符和指导对话,以支持公共研究。

自定义自动化软件工具增加了遗传咨询后续任务效率
遗传辅导员追踪了花费的时间写作和发送患者笔记,作为标准后续措施的一部分,用于3,900多个测试后的远程医疗遗传咨询会议,用于阳性彩色遗传性遗传性癌症测试或彩色遗传性心脏健康测试的患者2019年1月1日至2020年3月31日之间。在2019年6月至2020年3月启动自动化笔记软件之间使用自动软件工具的时间效率是在2019年1月至2019年1月至5月之间使用自动软件工具(n = 1,535)之间执行的相同的活动进行了比较。当不使用自动软件工具时,遗传辅导员提供了几种手动输入以注意模板,例如患者和提供者订单和人口统计信息,个人和家庭健康历史,基因测试结果以及基因咨询期间讨论的其他信息。

diffsign:具有增强现实主义的AI辅助生成可自定义的手语视频
摘要。近年来,几种流媒体服务的扩散使世界各地的各种受众都可以观看相同的媒体内容,例如电影或电视节目。虽然正在添加翻译和配音服务,以使当地受众访问内容,但支持具有不同能力的人(例如聋哑人和听力难(DHH)通信)可以访问的内容仍在滞后。我们的目标是通过与合成签名者生成手语视频,使DHH社区更容易访问媒体内容。使用相同的签名者对全球视图的给定媒体内容可能有限的吸引力。因此,我们的方法结合了参数建模和生成建模,以生成现实的合成签名者,并根据用户偏好自定义其外观。我们首先通过优化参数模型来重新定位人类手语构成3D手语的头像。然后,使用渲染的化身姿势来调节使用基于扩散的生成模型生成的合成签名者的姿势。合成签名者的外观由通过视觉适配器提供的图像提示控制。我们的结果表明,使用我们的方法生成的手语视频比仅在文本提示下的扩散模型生成的视频具有更好的时间固定性和现实主义。我们还支持多模式的提示,允许用户进一步自定义签名者的外观以备同行多样性(例如肤色,性别)。我们的方法对于签名匿名也很有用。