XiaoMi-AI文件搜索系统
World File Search System芯片尺寸

Ye Tian, Yang Zhao, Shengping Liu, Qiang Li, Wei Wang, Junbo Feng* and Jin Guo Scalable and compact photonic neural chip with low learning-capability-
摘要:光子计算因能以比数字电子替代方案高得多的时钟频率加速人工神经网络任务而受到广泛关注。特别是由马赫-曾德尔干涉仪 (MZI) 网格组成的可重构光子处理器在光子矩阵乘法器中很有前途。希望实现高基 MZI 网格来提高计算能力。传统上,需要三个级联 MZI 网格(两个通用 N × N 酉 MZI 网格和一个对角 MZI 网格)来表示 N × N 权重矩阵,需要 O ( N 2 ) 个 MZI,这严重限制了可扩展性。在此,我们提出了一种光子矩阵架构,使用一个非通用 N × N 酉 MZI 网格的实部来表示实值矩阵。在光子神经网络等应用中,它可能将所需的 MZI 减少到 O ( N log 2 N ) 级别,同时以较低的学习能力损失为代价。通过实验,我们实现了一个 4 × 4 光子神经芯片,并对其在卷积神经网络中的性能进行了基准测试,以用于手写识别任务。与基于传统架构的 O (N 2) MZI 芯片相比,我们的 4 × 4 芯片的学习能力损失较低。而在光学损耗、芯片尺寸、功耗、编码误差方面,我们的架构表现出全面的优势。

双通道芯片冷却建模与优化...
摘要 — 未来处理器预计将具有超高功率密度,而传统的冷却解决方案无法有效缓解这一问题。使用带有微柱芯蒸发器的两相蒸汽室 (VC) 是一种新兴的冷却技术,可通过冷却剂的蒸发过程有效去除高热通量。带有微柱芯的两相 VC 利用毛细管驱动流提供高冷却效率,其中冷却剂由芯吸结构被动驱动,从而无需外部泵。此类新兴冷却技术的热模型对于评估其对未来处理器的影响至关重要。现有的两相 VC 热模型使用计算流体动力学 (CFD) 模块,这需要较长的设计和仿真时间。本文介绍了一种快速、准确的带有微柱芯的两相 VC 紧凑热模型。与 CFD 模型相比,我们的模型实现了 1.25 ◦ C 的最大误差,速度提高了 214 倍。使用我们提出的热模型,我们构建了一个优化流程,选择最佳冷却解决方案及其冷却参数,以在给定处理器和功率分布的温度约束下最小化冷却功率。然后,我们在不同的芯片尺寸和热点分布上演示了我们的优化流程,以在 VC、基于微通道的两相冷却、通过微通道的液体冷却以及热电冷却器和微通道液体冷却的混合冷却技术中选择最佳冷却技术。

开发用于小芯片的切割芯片粘接膜 (DDAF)
近年来,对包括微机电系统 (MEMS) 和传感器在内的越来越小的芯片的需求急剧增加。自动驾驶技术等技术正在腾飞,市场对减小封装尺寸和提高移动设备性能的压力也在增加。DDAF 越来越多地被用于这些应用中,以将芯片粘合到基板和其他芯片上。DDAF 可用于切割和芯片粘合工艺,取代了使用两种独立材料来切割和粘合芯片的需求。它由 DAF(芯片粘接膜)和基材组成,DAF 层将小芯片粘合到基板和其他芯片上。然而,传统的 DDAF 在芯片尺寸较小时容易出现转移故障 (TF)。这是一种故障模式,在芯片拾取 (PU) 过程中,DAF 层从芯片背面剥落。导致此问题的根本原因有多种;小型芯片的 DAF 附着面积较小,而为增加芯片强度而使芯片背面光滑,导致 DAF 无法锚定到芯片本身。通过使用具有高熔体粘度的 DAF,使 DAF 能够更好地锚定到芯片上,从而改善了 PU 工艺上的 TF。但是,由于材料无法嵌入到基板上,封装可靠性下降。探索了高基板嵌入抑制 TF 的影响因素。为了探索这些因素,实施了直角撕裂强度方法。在分析数据后,发现了一个抑制 TF 的新参数。该参数与 TF 显示出很强的相关性。开发了一种新的 DDAF,可减轻 PU 过程中的 TF。关键词 刀片切割、切割芯片贴膜、MEMS、直角撕裂强度法、转移失败

IEEE 电子设备学报特别版“...
技术计算机辅助设计用于模拟半导体工艺和器件,这个领域已变得日益复杂和异构。如今,集成电路的加工需要超过 400 个工艺步骤,而最终的器件往往具有复杂的 3D 结构并包含各种材料。只有考虑从原子(界面、缺陷等)到纳米(量子限制、非体积特性等)到完整芯片尺寸(应变、热传输等)的所有长度尺度,以及从飞秒到秒的时间尺度的影响,才能理解完整的器件行为。电压、电流和电荷已缩放到如此低的水平,以至于电子噪声、统计效应和工艺变化都有很大的影响。基于新材料(例如 2D 晶体)和物理原理(铁电体、磁性材料、量子比特等)的器件对标准 TCAD 方法提出了挑战。虽然物理学界开发的模拟方法可以描述基本的器件行为,但它们通常缺乏重要的模拟功能,例如瞬态模拟或与其他 TCAD 工具的集成,并且对于日常使用来说速度太慢。由于半导体技术的复杂性,通过在理想条件下观察孤立器件的单个方面来评估工艺或器件结构变化对电路性能的影响变得越来越困难。相反,需要一个能够处理嵌入在芯片环境中的实际器件结构的 TCAD 工具链。TCAD 的所有方面都需要新的方法,以确保基于灵活的模拟模型的高效工具链,从原子效应到电路行为,这些模型可以处理新材料、器件原理和随之而来的大规模模拟。IEEE 电子设备学报的这期特刊将介绍 TCAD 在工艺和器件行为领域的最新发展和最新技术,重点介绍改进工具链的新方法。论文必须是新的、原创的材料,且未受版权保护、未在任何其他档案出版物中出版或接受出版,目前尚未考虑在其他地方出版,并且在《电子设备交易》审议期间不会提交到其他地方。感兴趣的主题包括但不限于:

电子产品 - UTS 的 OPUS
巴伦将单端信号转换为平衡信号,广泛用于射频前端模块,如倍频器、混频器等,它们利用差分信号来消除共模信号并改善端口隔离。巴伦的关键性能规格包括插入损耗、幅度/相位平衡和芯片尺寸。这些参数在毫米波 (MMW) 电路和系统的设计中非常重要 [1]。Marchand 巴伦 [2-10] 利用两个耦合线段,由于其工作带宽宽且易于实现,在 MMW 频率电路设计中得到广泛应用。在 [2] 中,提出了一种基于改进的离中心频率法的非对称宽边耦合 Marchand 巴伦。它实现了 34-110 GHz 的带宽;然而,它的插入损耗很高,平均约为 3 dB。为解决不平衡性能问题,还设计了另一种带有偏置半径线圈的30 GHz至60 GHz变压器巴伦[11]。结果显示,幅度不平衡为0.12 dB,相位不平衡小于1 ◦;但最大插入损耗约为3 dB。一种小型化片上Marchand巴伦[12]基于堆叠螺旋耦合(SSC)结构,带有自耦合补偿线和带深沟槽的中心抽头接地屏蔽,设计用于6.5 GHz至28.5 GHz的宽带工作,但测得的最大插入损耗为3 dB。宽带工作和幅度/相位不平衡一直是先前报道的文献的重点,同时以巴伦插入损耗为代价。在本文中,介绍了一种具有低插入损耗的新型Ka波段Marchand巴伦的设计,同时实现了宽带工作和可接受的不平衡性能。所提出的巴伦采用边耦合和宽边耦合组合结构来增强主信号和次信号之间的耦合,从而在 29.0 GHz 至 46.0 GHz 的 1 dB 带宽内实现了 1.02 dB 的测量低插入损耗。第 2 节介绍了巴伦的详细分析和所提出的巴伦设计,第 3 节讨论了实验结果并与最新技术进行了比较,第 4 节得出结论。

用于高效功率转换的 GaN 晶体管...
四十多年来,随着功率金属氧化物硅场效应晶体管 (MOSFET) 结构、技术和电路拓扑的创新与日常生活中对电力日益增长的需求保持同步,电源管理效率和成本稳步提高。然而,在新千年,随着硅功率 MOSFET 渐近其理论界限,改进速度已经放缓。功率 MOSFET 于 1976 年首次出现,作为双极晶体管的替代品。这些多数载流子器件比少数载流子器件速度更快、更坚固,电流增益更高(有关基本半导体物理的讨论,一个很好的参考资料是 [1])。因此,开关电源转换成为商业现实。功率 MOSFET 最早的大批量消费者是早期台式计算机的 AC-DC 开关电源,其次是变速电机驱动器、荧光灯、DC-DC 转换器以及我们日常生活中成千上万的其他应用。最早的功率 MOSFET 之一是国际整流器公司于 1978 年 11 月推出的 IRF100。它拥有 100V 漏源击穿电压和 0.1 Ω 导通电阻 (R DS(on)),堪称当时的标杆。由于芯片尺寸超过 40mm2,标价为 34 美元,这款产品注定不会立即取代备受推崇的双极晶体管。从那时起,几家制造商开发了许多代功率 MOSFET。40 多年来,每年都会设定基准,随后不断超越。截至撰写本文时,100V 基准可以说是由英飞凌的 BSZ096N10LS5 保持的。与 IRF100 MOSFET 的电阻率品质因数 (4 Ω mm 2 ) 相比,BSZ096N10LS5 的品质因数为 0.060 Ω mm 2 。这几乎达到了硅器件的理论极限 [2]。功率 MOSFET 仍有待改进。例如,超结器件和 IGBT 已实现超越简单垂直多数载流子 MOSFET 理论极限的电导率改进。这些创新可能还会持续相当长一段时间,并且肯定能够利用功率 MOSFET 的低成本结构和一批受过良好教育的设计人员的专业知识,这些设计人员经过多年学习,已经学会了从功率转换电路和系统中榨干每一点性能。

功率 SiC MOSFET 在重复性
摘要 本文研究了商用平面和沟槽 1.2 kV 4H-SiC MOFSET 在重复非钳位电感开关 (UIS) 和短路 (SC) 应力下的可靠性。观察到器件特性的退化,包括传输特性、漏极漏电流 Idss 和输出特性。对 400 和 600 V 总线电压进行重复 SC 应力。应力期间总线电压的增加对测试器件的电气性能有更大的影响。在老化实验期间可能会发生热载流子注入和进入沟道区域栅极氧化物的捕获,这被认为是导致电气参数变化的原因。 关键词:可靠性、退化、SiC MOSFET、TrenchMOSFET、重复 UIS、重复短路 介绍 近年来,碳化硅 (SiC) 功率 MOSFET 制造技术已经相当成熟,因此,现在可以从不同的制造商处大量购买 [1]。由于其优异的性能,SiC 器件可用于更高温度、更高开关频率和更高功率密度的应用 [2-3]。尽管如此,在它们完全取代硅 (Si) 器件之前,稳健性和可靠性仍然是这些器件在过流、过温、短路和非箝位电感开关 (UIS) [5] 等多种极端工作条件下的主要问题 [3-4]。随着为降低成本而缩小芯片尺寸的趋势,雪崩稳健性和短路承受能力变得更加关键,因为它们对芯片尺寸设计非常敏感,因为芯片的最大能量密度是固定的。在 UIS 测试中,MOSFET 通常连接到没有反向并联续流二极管的电感,以在关闭器件时换向环路电流。因此,器件必须在工作阶段吸收先前存储在电感中的所有能量。因此,只要存储的能量足够高,MOSFET 就会进入雪崩模式,导致器件结温逐渐升高 [6]。在大电流雪崩操作期间,会产生高浓度的热载流子,这可能会导致界面和绝缘 (氧化物) 层的退化。
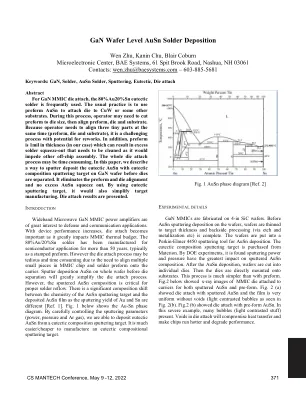
GaN 晶圆级 AuSn 焊料沉积
关键词:GaN、焊料、AuSn 焊料、溅射、共晶、芯片粘接摘要对于 GaN MMIC 芯片粘接,经常使用 80%Au20%Sn 共晶焊料。通常的做法是使用预制件 AuSn 将芯片粘接到 CuW 或其他一些基板上。在此过程中,操作员可能需要将预制件切割成芯片尺寸,然后对齐预制件、芯片和基板。由于操作员需要同时对齐三个微小部件(预制件、芯片和基板),因此这是一个具有挑战性的过程,可能需要返工。此外,预制件厚度为 1mil(在我们的例子中),这可能导致过量的焊料溢出,需要清理,因为它会妨碍其他片外组装。整个芯片粘接过程可能很耗时。在本文中,我们描述了一种在分离芯片之前在 GaN 晶圆上使用共晶成分溅射靶溅射沉积共晶 AuSn 的方法。它消除了预制件和芯片的对准,并且不会挤出多余的 AuSn。通过使用共晶溅射靶,它还可以简化靶材制造。下面给出了芯片粘接结果。引言宽带微波 GaN MMIC 功率放大器在国防和通信应用中具有重要意义。随着设备性能的提高,芯片粘接变得非常重要,因为它会极大地影响 MMIC 的热预算。80%Au/20%Sn 焊料已用于半导体应用超过 50 年,通常作为冲压预制件。然而,由于需要将 MMIC 芯片中的多个小块和焊料预制件对准到载体上,因此芯片粘接过程可能很繁琐且耗时。在芯片分离之前在整个晶圆上溅射沉积 AuSn 将大大简化芯片粘接过程。然而,溅射的 AuSn 成分对于正确的焊料回流至关重要。由于 Au 和 Sn 的溅射产率不同,AuSn 溅射靶材的化学性质和沉积的 AuSn 薄膜之间存在显著的成分变化 [参考文献 1]。下图 1 显示了 Au-Sn 相图。通过仔细控制溅射参数(功率、压力和氩气),我们能够从共晶成分溅射靶中沉积共晶 AuSn。制造共晶成分溅射靶要容易得多/便宜得多。

用于多芯片 GPU 的晶圆光子网络
在过去十年中,图形处理单元 (GPU) 的进步推动了人工智能 (AI)、高性能计算 (HPC) 和数据分析领域的重大发展。要在这些领域中的任何一个领域继续保持这一趋势,就需要能够不断扩展 GPU 性能。直到最近,GPU 性能一直是通过跨代增加流式多处理器 (SM) 的数量来扩展的。这是通过利用摩尔定律并在最先进的芯片技术节点中使用尽可能多的晶体管数量来实现的。不幸的是,晶体管的缩放速度正在放缓,并可能最终停止。此外,随着现代 GPU 接近光罩极限(约 800 平方毫米),制造问题进一步限制了最大芯片尺寸。而且,非常大的芯片会导致产量问题,使大型单片 GPU 的成本达到不理想的水平。GPU 性能扩展的解决方案是将多个物理 GPU 连接在一起,同时向软件提供单个逻辑 GPU 的抽象。一种方法是在印刷电路板 (PCB) 上连接多个 GPU。由于提供的 GPU 间带宽有限,在这些多 GPU 系统上扩展 GPU 工作负载非常困难。封装内互连(例如通过中介层技术)比封装外互连提供更高的带宽和更低的延迟,为将 GPU 性能扩展到少数 GPU 提供了一个有希望的方向 [1]。晶圆级集成更进一步,通过将预制芯片粘合在硅晶圆上,为具有数十个 GPU 的晶圆级 GPU 提供了途径 [2]。不幸的是,使用电互连在长距离上以低功耗提供高带宽密度从根本上具有挑战性,从而限制了使用电中介层技术进行 GPU 扩展。在本文中,我们提出了光子晶圆网络 (NoW) GPU 架构,其中预先制造和预先测试的 GPU 芯片和内存芯片安装在晶圆级中介层上,该中介层通过光子网络层连接 GPU 芯片,同时将每个 GPU 芯片与其本地内存堆栈电连接,如图 1 所示。光子-NoW GPU 架构的关键优势在于能够在相对较长的晶圆级距离(高达数十厘米)内以低功耗实现高带宽密度。本文的目标是展示光子-NoW 的愿景

激光直接成型作为传统光刻技术的创新替代方案S03-3
激光直接成型作为传统光刻的创新替代方案 Eddy Roelants 西门子 Dematic 根特,比利时 摘要:高速精确的激光束偏转、印刷电路板 (PCB) 湿化学工艺的专业知识、PCB 激光直接成型 (LS) 的 CAD/CAM 实施以及机器开发和构造专业知识相结合,产生了一种具有专用系统的完整激光技术(图 1),为高密度互连 (HDI) 技术的制造提供了一种创新的替代方案。LS 工艺可以轻松集成到标准 PCB 生产线中,这已在欧洲 PCB 制造工厂得到验证。LS 工艺使用薄浸锡 (Sn) 作为抗蚀剂,通过聚焦激光束烧蚀。激光束勾勒出电路轨道和焊盘的轮廓。激光束的移动由高速控制器根据电子 CAD 布局数据控制。这样无需洁净室设施即可实现 50 µm 线间距甚至更小的线结构,并获得可接受的良率 (>70-80%) 和可接受的加工时间。此外,该系统具有高度灵活的模块化结构;配备 532 nm(绿色)或 355 nm 波长激光的系统设置证明它是一种出色的结构化和 µ 通孔钻孔系统,不仅从质量而且从性能的角度来看都是如此。简介目前,即使对于 HDI 板,对于大多数 PCB 制造商来说,100 - 75 µm 线间距技术也是标准配置。要低于这个假想的线间距宽度,需要付出巨大的努力和投资。这是由于需要洁净室(2500 欧元/平方米)和/或需要玻璃母版技术(这反过来会影响面板尺寸 - 从而影响产量)。除此之外,实现可接受的良率是另一个关键问题。下一代电子设备可能需要高密度,但仅针对一两个元件,同时保持 90% 以上的 PCB 面积采用传统的 100 µm 间距线技术。GSM、照相机、寻呼机等中使用的芯片尺寸封装 (CSP) 要求 PCB 制造工艺进行调整和创新,从而降低公差并实现更精细的线/间距。在这里,使用激光结构化变得合理:使用激光技术在标准 PCB 生产线中局部添加精细结构(作为纯插入式工艺)。这就是所谓的 PHD 工艺(部分高密度)。对于 BGA/CSP 或 MCM 基板等小尺寸基板,可以在激光光学器件的场尺寸范围内对整个区域进行激光结构化。