XiaoMi-AI文件搜索系统
World File Search System观察的



量子信息理论方法解决心脑问题
大脑由可电刺激的神经元网络组成,这些神经元网络受电压门控离子通道活动的调节。然而,进一步描绘大脑的分子组成,不会揭示任何让人联想到感觉、知觉或意识体验的东西。在古典物理学中,解决心智-大脑问题是一项艰巨的任务,因为没有物理机制能够解释大脑如何产生不可观察的内在心理世界意识体验,以及这些意识体验如何反过来引导大脑的底层过程朝着期望的行为发展。然而,这一挫折并不能证明意识是非物理的。现代量子物理学证实了希尔伯特空间中两种物理实体之间的相互作用:不可观察的量子态,即描述物理世界中存在的矢量,以及量子可观测量,即描述可在量子测量中观察到的算子。量子不通过定理进一步为研究量子大脑动力学提供了一个框架,该框架必须由物理上可接受的汉密尔顿量控制。意识中包含了不可观察的量子信息,这些信息整合在量子大脑状态中,解释了意识体验内在隐私的起源,并将意识过程的动态时间尺度重新审视为神经生物分子的皮秒构象转变。可观察的大脑是一个客观结构,由经典信息比特创建,这些信息比特受 Holevo 定理约束,并通过测量量子大脑可观察量获得。因此,量子信息理论澄清了不可观察的思维和可观察的大脑之间的区别,并为意识研究提供了坚实的物理基础。
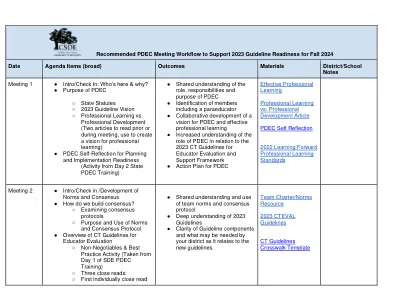
推荐PDEC会议工作流程以支持2023年秋季2024年指南准备就绪
与连续学习过程中的项目有关,与2023指南有关的非协商和/或最佳实践有关。。即:单点专栏,观察的频率和类型,高利用目标,形式的发展等。




越来越多自主系统的人类系统集成
观察阶段,并将允许人为因素专家和人类操作员对观察的评论。录音可用于进行自我对照。观察和访谈使得可以详细描述所执行的任务,所涉及的参与者,工具以及时间和地理方面以及可能的干扰。

启动ENSO:Cubesat有效载荷交付
与蒙彼利埃大学航天中心(CSUM)合作开发,ENSO(用于太阳 - iRradiance观察的纳米纳斯特)是一个R&D立方体,旨在通过帮助测量太阳能活动及其对地球的影响来帮助电离层表征电离层。

血浆聚合物膜的机械性能:评论
抽象的等离子体聚合物是微型或更常见的纳米大小涂层,可以通过不同的方法沉积在多种底物上。这些聚合物的多功能性是通过使用常规聚合反应以外的其他前体以及根据血浆的固有物理和化学特性的潜在变化而增加的。灵活性为各种科学和工程领域提供了富有成果的理由,但它也带来了许多经验观察的挑战。在这篇综述中,将不同的前体,底物和血浆外部参数的变化评估为常见,但不一定是理想或详尽的变量,用于分析血浆聚合物膜的机械性能。常见的趋势与例外相辅相成,并显示了经验观察的各种假设。用于确定血浆聚合物机械性能的技术和方法,对其进行后处理的影响以及某些应用的影响。最后,提供了一个一般的结论,突出了该领域的挑战。