XiaoMi-AI文件搜索系统
World File Search SystemDrivelm
drivelm:用图形驾驶视觉问题回答
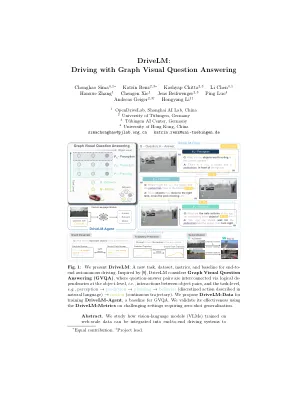
增强概括并实现与人类用户的互动性。最近的方法可以使VLM通过单轮视觉问题答案(VQA)适应VLM,但人类驾驶员在多个步骤中的决策原因。从关键对象的本地化开始,人类在采取行动之前估计相互作用。关键洞察力是,通过我们提出的任务,图形VQA,我们在其中建模了图形结构的理由,通过感知,预测和计划问题 - 答案对,我们获得了一个合适的代理任务来模仿人类的推理。我们实例化基于Nuscenes和Carla建立的数据集(DRIVELM-DATA),并提出了一种基于VLM的基线方法(Drivelm-Agent),用于共同执行图形VQA和端到端驾驶。实验表明,Graph VQA提供了一个简单的原则性框架,用于推理驾驶场景,而Drivelm-Data为这项任务提供了具有挑战性的基准。与最新的驾驶特定架构相比,我们的Drivelm-Agent基线端到端自动驾驶竞争性驾驶。值得注意的是,当在看不见的传感器配置上评估其零射击时,其好处是明显的。我们的问题上的消融研究表明,绩效增长来自图表结构中对质量检查对质量检查的丰富注释。所有数据,模型和官方评估服务器均可在https://github.com/opendrivelab/drivelm上找到。

drivelm:用图形驾驶视觉问题回答
模型。drivelm-agent采用轨迹令牌092,可以应用于任何一般VLM [17、19、23、34],093,以及图形提示方案,该方案模型logi-094 cal依赖关系作为VLMS的上下文输入。结果095是一种简单,优雅的方法,可有效地重新利用096 VLMS用于端到端AD。097我们的实验提供了令人鼓舞的结果。我们发现098在Drivelm上的GVQA是一项具有挑战性的任务,其中Cur-099租金方法获得适中的得分,并且可能需要更好地获得逻辑依赖的100型,以实现101强质量质量质量强大的效果。即使这样,在开放环计划环境中进行测试时,Drivelm-Agent已经有102个已经在最先进的驾驶特定103型型号[13]中竞争性地发挥作用,尽管其任务不合时宜和通用架构,但仍有104个模型。fur-105 Hoperore,采用图形结构可改善零弹性106概括,使Drivelm-Engent在训练或部署期间在108 Waymo DataSet [28]进行训练或仅在NUSCENES [3] 109数据上训练后,在108训练或部署期间都看不见新颖的对象。从这些结果中,我们认为,提高GVQA 110具有建立具有强烈概括的自动驾驶111代理的巨大潜力。112

drivelm:用图形驾驶视觉问题回答
增强概括并实现与人类用户的互动性。最近的方法可以使VLM通过单轮视觉问题答案(VQA)适应VLM,但人类驾驶员在多个步骤中的决策原因。从关键对象的本地化开始,人类在采取行动之前估计相互作用。关键洞察力是,通过我们提出的任务,图形VQA,我们在其中建模了图形结构的理由,通过感知,预测和计划问题 - 答案对,我们获得了一个合适的代理任务来模仿人类的推理。我们实例化基于Nuscenes和Carla建立的数据集(DRIVELM-DATA),并提出了一种基于VLM的基线方法(Drivelm-Agent),用于共同执行图形VQA和端到端驾驶。实验表明,Graph VQA提供了一个简单的原则性框架,用于推理驾驶场景,而Drivelm-Data为这项任务提供了具有挑战性的基准。与最新的驾驶特定架构相比,我们的Drivelm-Agent基线端到端自动驾驶竞争性驾驶。值得注意的是,当在看不见的传感器配置上评估其零射击时,其好处是明显的。我们的问题上的消融研究表明,绩效增长来自图表结构中对质量检查对质量检查的丰富注释。所有数据,模型和官方评估服务器均可在https://github.com/opendrivelab/drivelm上找到。