XiaoMi-AI文件搜索系统
World File Search SystemDyna

根据动态管理能力的理论和Dyna
与美国和欧洲汽车公司(美国和欧洲汽车公司)相反,这些公司在19日大流行期下进行了,丰田汽车公司持续了没有显着的负面影响。然而,在案件时代到来的“战争”中,即连接的汽车(C),自主驾驶(A),共享驾驶(S)和电动汽车(E)(E) - Toyota的记录并不令人鼓舞。本文评估了丰田电动汽车战略(EV),重点是基于动态管理能力理论(DMC)和动态平台策略的以下问题:(1)丰田对新进入EV业务的新速度是否足够吗?(2)如果丰田的进入速度不可能,那么原因是什么?(3)丰田对包括GAFA(Google,Apple,Facebook和Amazon)在内的IT巨头的“ EV大战”做好了充分的准备吗?结果是,由于动态管理能力的不良效率(DMC),丰田的新进入速度和GAFA的准备还不够,尽管该公司在案件时代出现后立即执行的战略变化方面表现出色。未能引入其他重大变化的原因是:(1)保留基于其过去成功的心态。(2)缺乏对全球变暖的社会责任感。(3)缺乏对GAFA的谨慎感。

Benjumea, José; Saiidi, M.“Saiid”; Itani, Ahmad 预制桥梁计算模型的抗震性能分析与评估 DYNA, 第 87 卷,第
摘要:在内华达大学雷诺分校的地震工程实验室,对一座由预制构件组装而成的大型双跨桥梁模型进行了一系列双轴地面运动模拟试验。在试验前,使用 OpenSees 软件开发的三维计算模型估算了桥梁的响应。试验后,将测量到的关键地震响应与计算模型预测的地震响应进行比较,以评估建模假设。观察到桥梁的位移、底部剪力和滞回响应存在较大的误差。本文讨论了地震荷载、材料、预制构件的连通性和计算模型中的边界条件对误差的影响。提出了未来的建模方向以减少这些误差。关键词:预制桥,计算模型,OpenSees,振动台试验。简历:Un puente de gran escala, de dos vanos, construido con varios elementos prefabricados fue ensayado bajo sismos biaxises en una mesa sísmica del Laboratorio de Ingeniería Sísmica de la Universidad de Nevada, Reno.通过使用 OpenSees 软件中的数字模型三维解集来估计预期的预测结果。在对数字模型的预测结果进行比较期间,重要的是要考虑模型的设计有效性。 La comparación reveló diferencias relativamente grandes en desplazamientos, cortante basal, y respuesta histerética.对西斯米卡的兴奋、材料、预制元件的连接、以及在文章中讨论的错误的前沿条件和错误的影响。不同的模型指导可以减少错误。参数:预制构件、计算模型、OpenSees、台面结构。

Elektor-Electronics-USA-1990-11.pdf - 世界无线电史
在大多数 C.-1SeS 中。与 Heath、Dyna 和其他公司的套件不同,不包括外壳、面板、旋钮、连接线、线路线、跳线和类似部件。通常不包括分步说明,但 TAA 和 SB 中的文章是有用的指南。套件中包含文章重印本。我们的目标是让您从基本部件开始 - 其中一些

研究生助教 - 实验断裂力学
申请人应具有机械工程、航空航天工程、船舶与海洋工程、土木工程和材料科学等专业的学士学位。具有硕士学位的研究生优先考虑。在以下领域有研究经验者将有很大优势:复合材料(制造/测试/分析)、FEA 模拟(使用 Abaqus/Ansys/LS-Dyna/COMSOL/内部代码)、科学编码(数值算法、网格生成、数据可视化等)

Pingel 企业
文字和徽标:Dyna Glide、Dyna Wide Glide、Eagle Iron、Electra Glide、Evolution、Fat Boy、HD、H-D、Harley、Harley-Davidson、Heritage Softail、Hugger、Low Glide、Low Rider、Roadster、Screamin' Eagle、Softail、Sport Glide、Sportster、Springer、Sturgis、Super Glide、Tour-Pak、Tour Glide、Ultra Classic、Wide Glide 和 Road King 是 Harley-Davidson, Inc.(位于威斯康星州密尔沃基)的注册商标。文字:Convertible、Duo Glide、Hydra Glide 和 V-Fire III 是 Harley-Davidson, Inc.(位于威斯康星州密尔沃基)的商标。本目录中哈雷戴维森摩托车的以下型号名称仅供参考:FL、FLH、FLHS、FLHT、FLHTC、FLHTC Ultra Classic、FLST、FLSTC、FLSTF、FLT、FLTC、FLTC Ultra Classic、FXB、FXDB、FXDC、FXDG、FXE、FXEF、FXLR、FXR、FXRC、FXRD、FXRDG、FXRP、FXRS、FXRSE、FXRS-Conv.、FXRS-SP、FXRT、FXS、FXSB、FXST、FXSTC、FXSTS、FXWG、XL、XLCH、XLCR、XLH、XLH 883、XLH 1100、XLH 1200、XLR、XLS、XLT、XLX、XR-1000、FLHR 和 FLSTN。所有其他品牌名称、商标或注册商标均属于其各自所有者的财产。

使用亚目标模型的目标空间计划
本文使用背面计划研究了一种新的基于模型的强化学习方法:混合(近似)动态编程更新和无模型更新,类似于DYNA架构。带有学习模型的背景计划通常比无模型的替代方案(例如Double DQN)差,即使前者使用的记忆和计算更大。基本问题是,学到的模拟可能是不准确的,并且经常会产生无效的状态,尤其是在迭代许多步骤时。在本文中,我们通过将背景计划限制为一组(摘要)子目标,并仅学习本地,子观念模型来避免这种限制。这种目标空间计划(GSP)方法在计算上更有效,自然地包含了时间抽象,以进行更快的长途径计划,并避免完全学习过渡动态。我们表明,我们的GSP算法可以从抽象空间中传播价值,以帮助各种基础学习者在不同的域中更快地学习显着的速度。关键字:基于模型的增强学习,时间抽象,计划
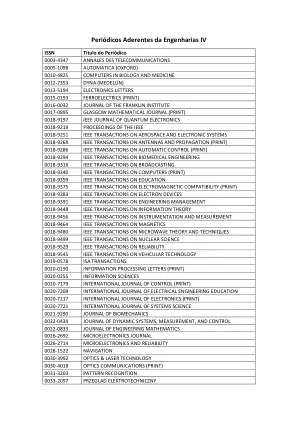
遵循工程 IV 的期刊
ISSN 期刊标题 0003-4347 电信年报 0005-1098 自动化(牛津) 0010-4825 生物医学计算机 0012-7353 DYNA(麦德林) 0013-5194 电子快报 0015-0193 铁电学(印刷版) 0016-0032 富兰克林研究所杂志 0017-0895 格拉斯哥数学杂志(印刷版) 0018-9197 IEEE 量子电子学杂志 0018-9219 IEEE 论文集 0018-9251 IEEE 数学学报航空航天与电子系统 0018-926X IEEE 天线与传播学报(印刷版) 0018-9286 IEEE 自动控制学报(印刷版) 0018-9294 IEEE 生物医学工程学报 0018-9316 IEEE 广播学报 0018-9340 IEEE 计算机学报(印刷版) 0018-9359 IEEE 教育学报 0018-9375 IEEE 电磁兼容学报(印刷版) 0018-9383 IEEE 电子设备学报 0018-9391 IEEE 学报工程管理 0018-9448 IEEE 信息理论学报 0018-9456 IEEE 仪器与测量学报 0018-9464 IEEE 磁学学报 0018-9480 IEEE 微波理论与技术学报 0018-9499 IEEE 核科学学报 0018-9529 IEEE 可靠性学报 0018-9545 IEEE 车辆技术学报 0019-0578 ISA 学报 0020-0190 信息处理信函(印刷版) 0020-0255 信息科学0020-7179 国际控制杂志(印刷版) 0020-7209 国际电气工程教育杂志 0020-7217 国际电子学杂志(印刷版) 0020-7721 国际系统科学杂志 0021-9290 生物力学杂志 0022-0434 动态系统、测量与控制杂志 0022-0833 工程数学杂志 0026-2692 微电子学杂志 0026-2714 微电子学与可靠性 0028-1522 导航 0030-3992 光学与激光技术0030‐4018 光学通信(打印) 0031‐3203 模式识别 0033‐2097 PRZEGLAD ELEKTROTECHNICZNY