XiaoMi-AI文件搜索系统
World File Search SystemPandas


信息科学技术(IS&T)
IS&T 5520数据科学和机器学习与Python(LEC 3.0)一起研究了数据科学方法论,用于刮擦,操纵,转换,清洁,可视化,可视化,总结和建模大型数据以及受监督和无人监督的机器学习算法应用于各种商业分析和数据科学方案。Python库,例如Pandas,Numpy,Matplotlib和Scikit-Learn。先决条件:STAT 3111,Stat 3113,Stat 3115或Stat 3117; IS&T 1552,IS&T 1562,Comp Sci 1575之一;对于研究生:微积分,统计和编程知识。

Lucas A. Weissman
Languages: Python, Java, C, C++, Kotlin, SQL (PostgreSQL), JavaScript, HTML/CSS, R, TypeScript, Tailwind ML & AI Frameworks: TensorFlow, PyTorch, Keras, Scikit-learn, Hugging Face Transformers, OpenCV, Stable Diffusion Libraries: pandas, NumPy, Scipy,Matplotlib,Seaborn,Plotly Frameworks:烧瓶,fastapi,node.js,react,bunx。开发人员工具:git,docker,vs code,eclipse,android Studio。创意工具:虚幻引擎,搅拌器,无花果,Adobe Suite,Unity,OpenGL,Trix.js,Oculus SDK,Meta Quest。云与分布式计算:Spark,Hadoop。

人工智能和机器学习 - NIELIT
人工智能是机器或软件所展现的智能。人工智能的应用领域非常广泛,因此这是一个日益重要的研究领域。这个工程分支强调创造像人类一样工作和反应的智能机器。目标本课程将介绍 Python 编程及其基本数据结构。学生将学习如何编程和使用 Numpy 和 pandas 等数据科学库,应用数据分析、数据清理技术、数据可视化。将详细介绍机器学习的概念、模型及其算法的实现。还将介绍神经网络中转换文本和图像领域的深度学习算法。

Databricks-Machine-Learning-Coscoite
PySpark DataFrame API中的函数mapinpandas允许将函数应用于数据框的每个分区。在使用分组数据时,GroupBy然后使用ApplionPandas是正确的方法,可以将功能应用于单独的PANDAS数据框架。但是,如果该函数应在分组数据的每个分区中应用,而不是在每个组上应用,则将使用MAPINPANDAS。由于代码段表示使用GroupBy,因此目的似乎是在每个组上都将Train_model应用于特定的,这与ApplionInpandas一致。因此,ApplionPandas是一种更好的选择,以确保GroupBy生成的每个组都通过Train_Model函数处理,并保留分区和分组完整性。
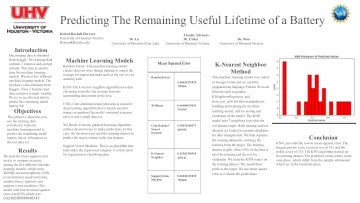
预测电池的剩余有用寿命
方法此机器学习模型是在Google Colab中编码的,我们使用了编程语言Python。我们使用诸如Pandas,KneighBorsRegressor和Train_test_split之类的库进行数据操纵,构建和培训机器学习模型,以及对模型的测试和验证。KNN模型使用7个邻居来预测测试数据集目标。将培训和测试数据集加载到熊猫数据框架上进行数据操作。然后,我们通过将功能与目标分离来分开训练数据集。培训数据集被拆分,其中80%的数据用于培训,其余数据用于验证。我们在培训数据集上训练KNN模型。然后该模型预测目标。我们使用均方根误差来评估预测。

开发支持的操作系统...
摘要 - 本研究讨论了智能操作系统功能的开发,该功能支持Linux操作系统中使用人工智能(AI)功能的智能预测和建议。该研究旨在通过根据用户行为模式提供相关的应用程序建议将AI驱动的功能集成到Linux中,以提高用户的生产率和效率。实施涉及应用程序使用情况的数据收集,用于应用程序建议的机器学习模型,以及将这些功能集成到Linux环境中。该项目利用Python进行脚本,采用Psutil,Pandas,Scikit-Learn和Joblib等库来进行数据处理和机器学习任务。结果表明,AI驱动的推荐系统的成功实现,增强了Linux操作系统中的用户互动和生产力。

Quentin Ferry(博士)
深度学习课程和认证:(i)深度学习。 (ii)UC Berkeley-设计,可视化和理解深NN(审计,2021年); (iii)DeepMind-强化学习系列2021(审计,2021年)。-----熟悉:经典DL体系结构(MLP(FF),CNN,RNN,NLP,Transformers),模型培训与优化(SGD,正规化,超参数调整等),应用程序(RL,Vision,Vision,NLP,GAN,VAE)。无监督的学习与数据分析(PCA,TSNE,MDS等)。-----编程语言:Python(Numpy,Pandas,Pytorch,Matplot- Lib),R,Matlab(也是Java,Java,JavaScript,CSS,CSS,HTLM,MySQL)。-----科学交流(即手稿,海报和谈话)(精通所有办公室软件和Adobe Illustrator);流利的英语和法语。

初级计算研究人员发布
○ Experience with web development (HTML, CSS, Javascript, React, Vue, Svelte, three.js, d3.js, leaflet, mapbox) ○ Experience with data analysis (Python, pandas, numpy, scikit-learn, SQL) ○ Experience with GIS tools (QGIS, ArcGIS, ArcMap, Leaflet, or MapBox) ○ Experience with command line interface and用于文件操作的脚本工具●具有灵活和独立工作以及指导的验证能力●较强的书面和口语交流技巧;能够记录对细节的关注并纳入关键反馈的能力●展示了研究技能和经验在跨学科团队上合作的经验●通过暴露于敏感/图形内容的学习最佳实践的兴趣●开放的探索,使用和学习新方法,框架和工具和工具●熟悉设计,访问和访问权限

主题:应用人工智能(APAI)
什么是计算机视觉?图像分析和计算机视觉的应用。常见的图像和视频格式(非常简短的描述 .jpeg、.tiff、.bmp、.mp4、.avi)、颜色模型:RGB、计算机中的图像表示、图像二值化(基于阈值)、图像特征 - 像素特征、灰度值作为特征、通道的平均像素值、边缘特征(Prewitt 核、Sobel 核)、纹理特征、用例:使用动物数据集进行图像分类(三类 - 狗、猫和熊猫)、带有示例的图像表示、动物数据集的描述、使用 k-NN 或其他 ML 工具进行分类(步骤的简要描述:数据收集、数据表示、将数据集拆分为训练集和测试集、训练分类器、使用 Scikit 学习工具进行评估)。