XiaoMi-AI文件搜索系统
World File Search SystemRLHF


RLHF和DPO上的来宾演讲
假设具有n个形式(b i,b j,µ)的n个元素,其中µ(1)= 1,如果人类标记为bi≻bj,µ(1)= 0。5如果人类标记为b i = b j,则否则0如果b j j b i


提示,指令登录和DPO/RLHF
•斯坦福大学位于加利福尼亚州的__________。[Trivia]•我将___叉放在桌子上。[语法]•那个女人走过马路,检查___肩膀的交通。[COREFERCE]•我去了海洋,看到鱼,海龟,海豹和_____。[词汇语义/主题]•总的来说,我两个小时从观看爆米花和饮料的总和。电影是___。[情感]•IROH进入厨房喝点茶。Zuko站在Iroh旁边,思考了自己的命运。Zuko离开了______。[某些推理 - 这很难]•我在考虑1、1、2、3、5、8、13、21,____ [一些基本算术;他们不学习fibonnaci序列]

通过因果关系解决RLHF中的奖励黑客
奖励黑客[Skalse等,2022]是AI对齐的关键问题,尤其是在增强学习(RL)中。AI系统旨在优化特定的奖励,通常会发现意想不到的方式来最大化这种奖励,这与人类意图不同。真正的目标与模型所学的行为之间的这种错位可能会导致不安全或不良结果。解决奖励黑客攻击对于构建可靠与人类价值观相吻合的AI系统至关重要。通过人类反馈(RLHF)进行加强学习的主要奖励黑客攻击是因果错误识别[Tien等,2022]。当模型错误地学习动作与奖励之间的因果关系,导致其优化代理或虚假相关性而不是真实目标时,就会发生这种情况。例如,该模型可能会在其环境中操纵指标或利用快捷方式。这创建了一个方案,其中AI根据奖励功能看起来很成功,但无法实现预期的目标。该项目旨在探索是否准确识别奖励模型中的因果机制是否可以帮助减轻奖励黑客攻击。通过对推动理想行为的因果关系进行建模,我们希望将AI引导到更加一致的学习中。具体来说,该项目将调查将因果推断整合到奖励建模中以提高RLHF鲁棒性的方法,从而降低AI利用意外漏洞的风险。目标是了解因果推理如何有助于更好地对齐具有人为价值的AI系统。

从人类反馈(RLHF)学习的强化学习
https://www.youtube.com/watch?v=xwukx- ayirs&list = pljv_el3uvtsmhtsmhtt7_y6sgthghghphghp1vb2p2p2j&index = 29

为什么Bradley-Terry模型适合RLHF?
本论文的主要问题是,尽管Bradley-Terry模型在建模RLHF和培训LLM的偏好方面有明确的缺点,但为什么Bradley-Terry模型效果很好。例如,许多批评家认为,即使各个偏好是及物的,这种偏好的聚集也不是Bradley-terry模型的参数化不足。在本论文中进行调查的潜在假设是,尽管对于培训LLM模型的培训,这种批评可能是正确的,但对于确定了最佳输入向量而不是整个排名,但对于训练LLM模型来说,这只是重要的。此外,由于与这些模型的大小相比,由于偏好数据集的尺寸较小,LLM易于过度拟合。Bradley-Terry模型的普及和功效可能是由于其参数不足是一种隐式正规化而引起的。

rlaif vs. rlhf:通过AI反馈从人类反馈中缩放加强
Harrison Lee,Samrat Phatale,Hassan Mansoor,Thomas Mesnard,Johan Ferret,Kellie Lu,Colton Bishop,Ethan Hall,VictorCărbune,Abhinav Rastogi,Sushant Prakash Prakash ICML 2024 div>Harrison Lee,Samrat Phatale,Hassan Mansoor,Thomas Mesnard,Johan Ferret,Kellie Lu,Colton Bishop,Ethan Hall,VictorCărbune,Abhinav Rastogi,Sushant Prakash Prakash ICML 2024 div>
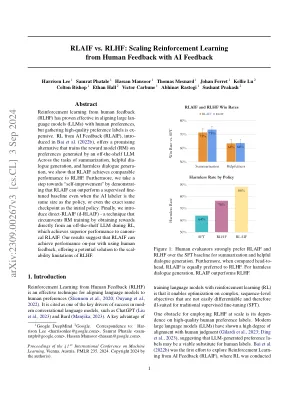
rlaif vs. rlhf:通过AI反馈从人类反馈中缩放加强
从人类反馈(RLHF)中学习的抽象强化学习已被证明有效地使大型语言模型(LLMS)与人类的偏好保持一致,但是收集高质量的偏好标签是可以表达的。rl来自AI反馈(RLAIF),在Bai等人中引入。(2022b),提供了一种有希望的替代方案,该替代方案对现成的LLM产生的偏好训练奖励模型(RM)。在摘要的任务,有用的直径生成和无害的对话构成的任务中,我们表明RLAIF的性能与RLHF相当。此外,我们通过证明RLAIF的表现可以超越受监督的细节基线,即使AI标签的大小与策略相同,甚至与初始策略完全相同的检查点,我们也可以迈出“自我完善”的一步。最后,我们引入了直接raif(D-RLAIF) - 一种通过直接从RL持续的LLM获得奖励来绕过RM训练的技术,该技术在RL期间获得了较高的性能,从而达到了Canoni-cal rlaif。我们的结果表明,RLAIF可以通过使用人类反馈来实现PAR的性能,从而为RLHF的尺度限制提供了潜在的解决方案。

人工智能协同与社会选择:根本限制和政策含义∗
使人工智能代理与人类意图和价值观保持一致是构建安全且可部署的人工智能应用的关键瓶颈。但人工智能代理应该与谁的价值观保持一致?强化学习与人类反馈 (RLHF) 已成为人工智能对齐的关键框架。RLHF 使用来自人类强化器的反馈来微调输出;所有广泛部署的大型语言模型 (LLM) 都使用 RLHF 使其输出与人类价值观保持一致。了解 RLHF 的局限性并考虑由这些局限性引起的政策挑战至关重要。在本文中,我们研究了构建尊重民主规范的 RLHF 系统的一个特定挑战。基于社会选择理论中的不可能结果,我们表明,在相当广泛的假设下,没有独特的投票协议可以通过民主程序使用 RLHF 普遍对齐人工智能系统。此外,我们表明,使人工智能代理与所有个人的价值观保持一致将始终违反个人用户的某些私人道德偏好,即使用 RLHF 进行普遍的人工智能对齐是不可能的。我们讨论了使用 RLHF 构建的 AI 系统治理的政策含义:首先,需要强制执行透明的投票规则,以追究模型构建者的责任。其次,模型构建者需要专注于开发与特定用户群体紧密结合的 AI 代理。