XiaoMi-AI文件搜索系统
World File Search SystemRammohan


A Sivathanu Pillai博士博士,D.Sc.A Sivathanu Pillai博士博士,D.Sc.
Dr. Pillai is a recipient of various prestigious awards including Technology Leadership Award, Dr. Vikram Sarabhai Research Award, OISCA – Organization for Industrial, spiritual & Cultural Advancement, International Award from Japan, Raja Rammohan Puraskar, Lokamanya Tilak Award, Performance Excellence Award from Institution of Industrial Engineering, Lal Bahadur Shastri National Award by the President of India and most importantly Padma Shri (2002)&Padma Bhushan(2013)由政府。印度为航空航天,导弹和国防技术以及政府的“友谊秩序”做出了贡献。俄罗斯联邦,俄罗斯最高的外国公民奖。

如何引用本文 Rammohan R、Joy MV、Magam S 等人(2024 年 1 月 8 日)了解前景:人工智能 (AI)、ChatGPT 和 Google Bard 在胃肠病学领域的出现。Cureus 16(1): e51848。DOI 10.7759/cureus.51848
本研究使用一系列患者可能会问的典型胃肠病学问题对 ChatGPT 和 Google Bard 进行了测试。这些问题被输入到每个 AI 工具中,并以“以下问题的合适答案是什么?”作为开头。每个问题都在新的聊天会话中提出,以保持实验的完整性并防止对记忆保留产生任何影响。ChatGPT 和 Google Bard 生成的答案随后由两位独立审阅者进行细致分析,他们并不知道哪个 AI 工具产生了哪个答案。这些审阅者采用李克特量表进行评估,其中 1 分表示“差”答案,10 分表示“优秀”答案。该评分系统提供了一种标准化方法来评估 AI 生成的答案的质量。
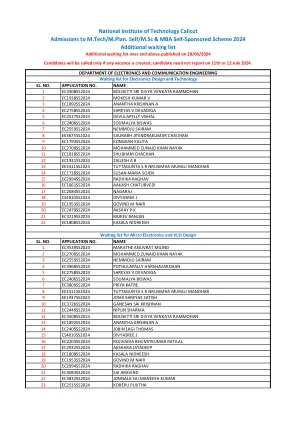
国家技术研究院卡利卡特录取给M.
SL。 否。 应用程序编号。 名称1 EC3539SSSS2024 MARATHE ANUVRAT MILIND 2 EC2700SSS2024 MOHAMMED KHAN NAYAK NAYAK 3 EC2559S2024 NEMMOJU SAIRAM 4 EC3968S2024 Shreyas v Devadiga 6 EC2406SSSS2024 SOUMALYA BISWAS 7 EC3800SSS2024 PRIYA KATRE 8 EE3311S2024 Sai Krishnan 11 EC2449SSS2024 Nipun Sharma 12 EC3508SS2024 EC2203SSS2024 Rojivadia Bhumitkumar ratilal 17 EC2932SSSSSSSSS2024 AKSHARA JAYADEEP 18 EC1808S2024 KASALA NIDHEESH 19 EC1953SSSSSSSSSS2024 GOVIND M NAIR M NAIR MNAIR 20 EC2994SSS2024 RADHIKA RAGHIKA RAGHAVA RAGHAVA RAGHAVA RAGHAVA RAGHAVA RAGHAVA RAGHAVA RAGHAVA RAGHAVA RAGHAVA SAI ARAVIND 22 EC3832SSS2024 JONNALA SAI MANEESH KUMAR 23 EC2515S2024 KOREPU PUJITHASL。否。应用程序编号。名称1 EC3539SSSS2024 MARATHE ANUVRAT MILIND 2 EC2700SSS2024 MOHAMMED KHAN NAYAK NAYAK 3 EC2559S2024 NEMMOJU SAIRAM 4 EC3968S2024 Shreyas v Devadiga 6 EC2406SSSS2024 SOUMALYA BISWAS 7 EC3800SSS2024 PRIYA KATRE 8 EE3311S2024 Sai Krishnan 11 EC2449SSS2024 Nipun Sharma 12 EC3508SS2024 EC2203SSS2024 Rojivadia Bhumitkumar ratilal 17 EC2932SSSSSSSSS2024 AKSHARA JAYADEEP 18 EC1808S2024 KASALA NIDHEESH 19 EC1953SSSSSSSSSS2024 GOVIND M NAIR M NAIR MNAIR 20 EC2994SSS2024 RADHIKA RAGHIKA RAGHAVA RAGHAVA RAGHAVA RAGHAVA RAGHAVA RAGHAVA RAGHAVA RAGHAVA RAGHAVA RAGHAVA SAI ARAVIND 22 EC3832SSS2024 JONNALA SAI MANEESH KUMAR 23 EC2515S2024 KOREPU PUJITHA

2022 年秋季刊 - Frontier Weekly
更多相同—3 Sumanta Banerjee 写给 Ranajit Guha 的信 —4 印度:Quo Vadis?作者:阿努普·辛哈 —5 历史、民族主义和甘地,作者:希曼舒·罗伊 —10 “与同志们同行”,作者:伯纳德·德梅洛 —12 公开号召共产主义革命者,作者:阿鲁普·拜西亚 —16 战争与左翼,作者:马塞洛·穆斯托—18 印度的替代道路,作者:Bharat Dogra —20 气候征用——一个政治问题,作者:Farooque Chowdhury —26 殖民现代性对印度知识分子的影响,作者:Aloke Mukherjee —30 重新发现和恢复罗摩罕·罗伊,作者:Asok Chattopadhyay —32 捍卫不可辩护之事,作者 Shamsul Islam —37 湿婆军:政治机会主义的限度,作者 Paranjoy Guha Thakurta —39 人类平均健康寿命可能达到多少?作者 Chaman Lal —40 工会运动的兴衰 作者 Asis Sengupta —44 新冠疫情对非正规部门工人的影响 作者 Nityananda Ghosh —47 伊拉克库尔德斯坦的印度劳工 作者 Arup Kumar Sen —49 Nirmal Kumar Bose : 阿比吉特·古哈 (Abhijit Guha) 著《民族主义人类学家》—50 所罗门·维克图斯 (Solomon Victus) 著《泰米尔民族主义》—55 普兰贾利·班杜 (Pranjali Bandhu) 著《罗兴亚人的困境》—57 马纳斯·巴克什 (Manas Bakshi) 著《妥协的政治》—61 拉纳·博斯 (Rana Bose) 著《物理学、宗教和顽固的从属关系》—63 更多帕累托变色龙的《来自帝国首都的新闻》—65 桑卡尔·雷伊的《莫迪正在逆转自由斗争的成果》—67 萨拉尔·萨卡尔的《乌克兰战争带来了生态悖论及其解释》 —69 Anuj B 的《街道在运动》—72